kerasで事前学習できるモデルの理解を深めるたい。
大規模な画像認識のための非常に奥行きのあるコンビネーションネットワーク(VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION)
抜粋
本研究では、大規模な画像認識設定における畳み込みネットワークの深さがその精度に及ぼす影響を調べる。 私たちの主な貢献は、非常に小さい(3×3)畳み込みフィルタを備えたアーキテクチャを使用して、深度のネットワークを徹底的に評価することであり、深さを16-19ウェイトのレイヤーにプッシュすることによって、 これらの調査結果は、私たちのチームがローカライゼーションと分類のそれぞれで第1位と第2位を確保したImageNet Challenge 2014提出の基礎となりました。 我々の表現は、最先端の結果を達成する他のデータセットにもよくあることを示しています。 Wehaveは、コンピュータビジョンにおける深い視覚的表現の使用に関するさらなる研究を容易にするために、2つの最も優れたConvNetモデルを公開しました。
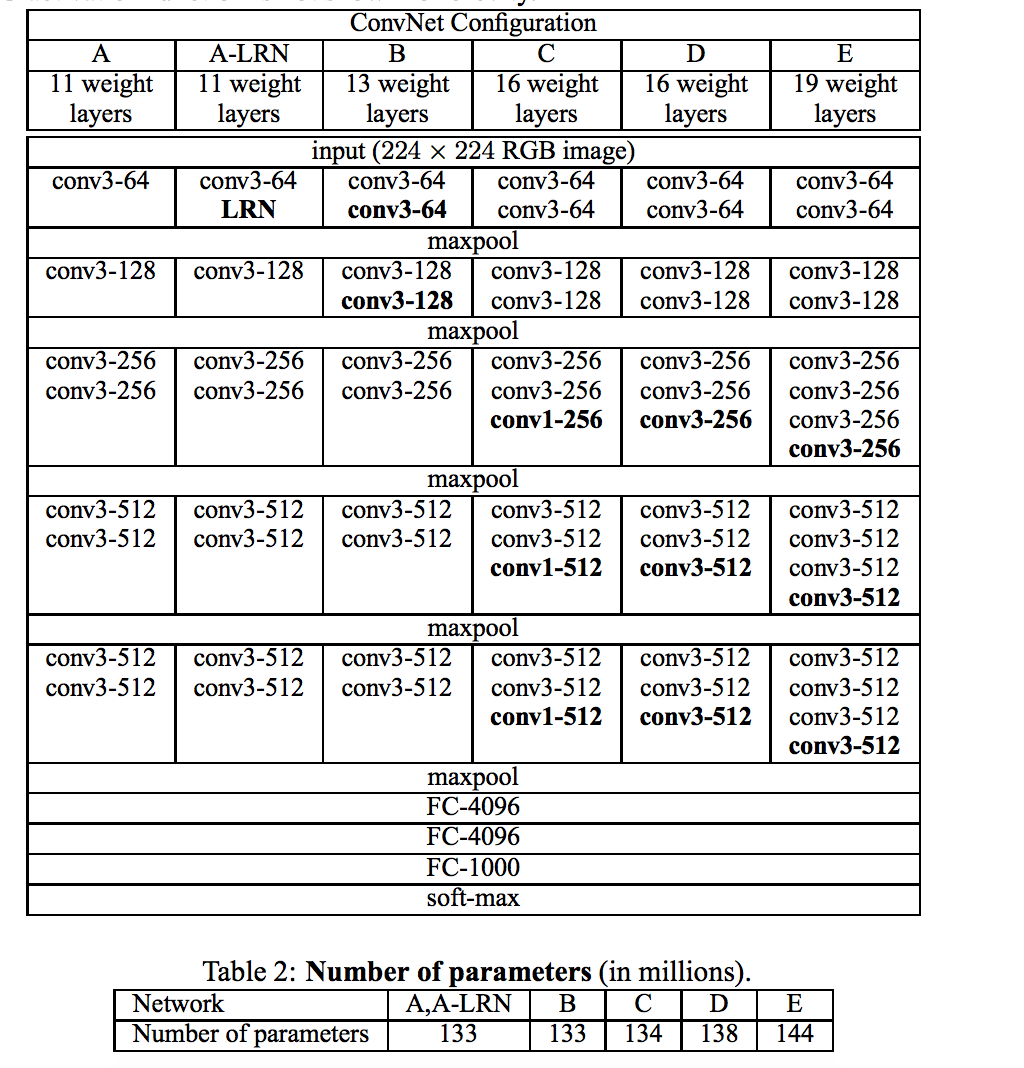
大規模な画像認識のための非常に奥行きのあるコンビネーションネットワーク(VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION)
抜粋
本研究では、畳み込みネットワークの深さが大規模画像認識設定の精度に与える影響を調べる。私たちの主な貢献は、非常に小さい(3x3)畳み込みフィルタを備えたアーキテクチャを使用して、深さが深くなるネットワークの徹底的な評価であり、深さを16-19の重さにすることによって従来技術の構成を大幅に改善できることを示しています。これらの調査結果は、ImageNet Challenge 2014の提出の基礎となりました。私たちのチームは、ローカリゼーションと分類のそれぞれで第1位と第2位を確保しました。我々はまた、我々の表現が最先端の結果を達成する他のデータセットに一般化することを示す。私たちは、コンピュータビジョンにおける深い視覚的表現の使用に関するさらなる研究を促進するために、2つの最も優れたConvNetモデルを公開しました。
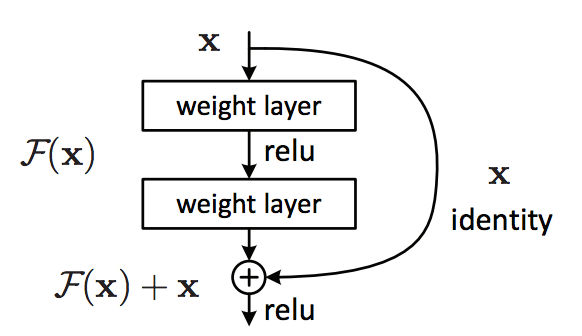
# 画像認識のための深層残差学習(Deep Residual Learning for Image Recognition) ## 抜粋 より深いニューラルネットワークは訓練することがより困難です。これまでに使用されていたものよりもかなり深いネットワークのトレーニングを容易にするために、残りの学習フレームワークを提示します。非参照関数を学習するのではなく、層入力を参照して残差関数を学習するように層を明示的に再構成する。我々は、これらの残留ネットワークが最適化しやすく、かなり深い深度から精度を得ることができるという包括的な経験的証拠を提供する。 ImageNetデータセットでは、VGGネットより8倍深い152階層までの深さの残存ネットを評価しますが、複雑さは依然として低くなっています。これらの残差ネットのアンサンブルは、ImageNetテストセットで3.57%のエラーを達成します。この結果は、ILSVRC 2015分類作業の第1位を獲得しました。我々はまた、100および1000層のCIFAR-10に関する分析を提示する。 表現の深さは、多くの視覚的認識課題にとって重要である。私たちの非常に深い表現のせいで、私たちはCOCOオブジェクト検出データセットで28%の相対的な改善を得ています。深い残留網は、ILSVRC&COCO 2015競技会への提出の基礎であり、ImageNet検出、ImageNetローカリゼーション、COCO検出、およびCOCOセグメンテーションの第1位を獲得しました。
コンピュータビジョンのためのインセプションアーキテクチャの再考(Rethinking the Inception Architecture for Computer Vision) InceptionV3
抜粋
畳み込みネットワークは、幅広い種類のタスクのための最先端のコンピュータビジョンソリューションの中核をなしています。 2014年以降、非常に深い畳み込みネットワークが主流になり、さまざまなベンチマークで大幅な利益を上げ始めました。モデルサイズと計算コストの増加は、ほとんどのタスクで(トレーニングに十分なラベル付きデータが提供されている限り)すぐに品質が向上する傾向にありますが、計算効率とパラメータ数は、モバイルビジョンやビッグデータシナリオ。ここでは、適切に因数分解された畳み込みと積極的な正則化によって可能な限り効率的に計算を利用することを目指す方法でネットワークをスケールアップする方法を検討します。私たちは、ILSVRC 2012分類挑戦検証セットの方法をベンチマークすることにより、最先端技術に対する実質的な利益を実証しました。計算コスト50億のネットワークを使用したシングルフレーム評価では、トップ1エラー21.2%、トップ5エラー5.6%推論を追加し、2500万未満のパラメータを使用します。 4つのモデルと複数の作物評価のアンサンブルを使用して、検証セット(検証セットの3.6%のエラー)で3.5%の上位5つのエラーと、検証セットでの上位1のエラー17.3%を報告します。
音楽分類のための畳込リカレントニューラルネットワーク(CONVOLUTIONAL RECURRENT NEURAL NETWORKS FOR MUSIC CLASSIFICATION)
ざっくりいうと
CNNにRNNをくっつけたのがCRNN。
音楽タグ付けをCNNかRCNNを使用した話。
kerasのMusicTaggerCRNNに使われている。
抜粋
我々は、音楽タグ付けのための畳み込みリカレントニューラルネットワーク(CRNN)を導入する。 CRNNは、局所特徴抽出のための畳み込みネットワーク(CNN)および抽出された特徴の時間的累積のための再帰的ネットワークを利用する。 我々は、音楽タグ付けに使用されている3つのCNN構造とCRNNを比較しながら、サンプルあたりのパフォーマンスとトレーニング時間に関してパラメータの数を制御します。 全体として、我々はCRNNがパラメータと訓練時間の数に関して強力な性能を示し、音楽特徴抽出と特徴聴覚におけるハイブリッド構造の有効性を示していることを見出した.
Index用語 - 畳み込みニューラルネットワーク、再発性ネットワーク、音楽分類
1.はじめに
畳み込みニューラルネットワーク(CNN)は、音楽タグ付け[1、2]、ジャンル分類[3,4]、および推薦のためのユーザアイテム潜在性予測[5]などの様々な音楽分類タスクに積極的に使用されてきた.CNNは、異なるレベルの階層を畳み込みカーネルによって抽出することができる。教授訓練中に与えられたタスクを達成するために、階層的特徴が学習される。例えば、CNNは、ジャンル分類のための訓練を受けた低レベルの特徴(例えば、発症)から高レベルの特徴(例えば、聴覚器のパターン)を呈する[6]。最近、CNNはリカレントニューラルネットワーク(RNN)と組み合わされている。音声信号や単語列などの順次データをモデル化するためによく使用されます。このハイブリッドモデルは、畳み込みリカレントニューラルネットワーク(CRNN)と呼ばれます。 CRNNは、最後の畳み込み層をRNNで置き換えることによって、修正されたCNNとして記述することができる。 InCRNN、CNNおよびRNNは、それぞれ、特徴抽出器および時間的加算器の役割を果たす。特徴を集約するためにRNNを採用することにより、ネットワークはグローバル構造を考慮に入れ、残りの畳み込み層によって局所特徴が抽出される。この構造は文書分類のために[7]で最初に提案され、その後画像分類[8]に適用され、音楽転写[9] .CRNNは音楽タグ付け作業によく適合した。 RNNは、加重平均(畳み込み)およびサブサンプリングを使用することによって静的であるCNよりも局所的特徴をどのように要約するかを選択する上でより柔軟である。このような柔軟性は、グローバルな構造の影響を受けるタグ(例えばムードタグ)が存在し、楽器などの他のタグがローカルおよびショートセグメント情報の影響を受けるため有用である。 3つの既存のCNN。正しい比較のために、構造の2つの属性、i)パラメータの数、およびii)計算時間を変えながら、ハードウェア、データ、および最適化技術を慎重に制御します。
2.モデル
 図1:k1c2、k2c1、k2c2、およびCRNNのブロック図。 灰色の領域は、畳み込みカーネルを示しています。 Nは、畳み込み層の特徴マップの数を指す。
図1:k1c2、k2c1、k2c2、およびCRNNのブロック図。 灰色の領域は、畳み込みカーネルを示しています。 Nは、畳み込み層の特徴マップの数を指す。
図1に示すk1c2、k2c1、およびk2c2とCRNNを比較します。3つの畳み込みネットワークは、カーネル形状(1Dカーネルの場合はk1)と畳み込み次元(2D畳み込みの場合はc2)を指定する名前が付けられています。すべてのネットワークについて、入力は、サイズ96×1366(メル周波数帯×時間枠)および単一チャネルであると仮定される。本論文では、すべての畳み込みと完全接続層には同一の最適化技術と活性化関数、すなわちバッチ正規化[10]とELUactivation関数[11]が装備されている。これは正しい比較のためのものであり、本質的に同じ構造を有するネットワークの性能を大幅に改善する。例外的に、CRNNは、RNN層のオーバーフィッティングを防ぐために畳み込み層間の弱いドロップアウト(0.1)を有する[12]。
2.1。 CNN - k1c2
図1aのk1c2は、ジャンル分類のための構造によって動機づけられる[13]。ネットワークは、4つの畳み込みレイヤーとそれに続く2つの完全接続レイヤーで構成されています。 (1×4) - (1×5) - (1×8) - (1×8))の一次元畳み込み層(全て1×4、すなわち畳み込み時間軸)および最大プール層最後のフィーチャマップの各要素(第4のサブサンプリング層の出力)は、各帯域についての情報を符号化する。それらは平らにされ、クラシファイアとして機能する完全に接続されたレイヤーに送られます。
2.2。 CNN - k2c1
図1bのk2c1は、音楽タグ付け[1]およびジャンル分類[14]のための構造によって動機付けられる。ネットワークは、5つの畳み込みレイヤーと2つの完全接続レイヤーで構成されています。第1の畳み込み層(96×4)は、全周波数帯域に適用される2Dカーネルを学習する。その後、1次元畳み込み層(すべて1×4、すなわち畳み込み時間軸)および最大プール層((1×4)または(1×5))が交互になる。結果は平坦化され、完全接続層に供給されます。このモデルは、全周波数範囲の情報を第1の畳み込み層の1つの帯域に圧縮し、これにより計算の複雑さが大幅に低減されます。
2.3。 CNN - k2c2
k2c2は、3×3のカーネルと(2×4) - (2×4)の最大プール層の5つの畳み込み層から成り立っている[15] .2次元畳み込みを持つCNN構造は、モジュレーション[2]とボーカル/ (2×4) - (3×5) - (4×4))である。このネットワークでは、各レイヤーがink1c1とk2c1のように各周波数帯域ではなく入力全体をカバーしている最終レイヤーで、オフエアメントマップのサイズを1×1に縮小します。このモデルでは、徐々に2Dサブサンプリングによって異なるスケールで時間と周波数の不変量が許されます。また、2Dサブサンプリングを使用すると、ネットワークを完全に畳み込みすることができ、結果的にパラメータが少なくなります。
2.4。 CRNN
CRNNは、図1cに示すように、二次元RNNをgated recurrent unit(GRU)[16]とともに使用して、二次元4層CNNの最上部の時間パターンを要約します。このモデルの基礎となる仮定は、局所的特徴抽出のために入力側のCNNに依存しながら、時間的パターンをRNNs、次にCNNsにより良好に集約することができることである。CRNNでは、RNNsを使用して、 [1]のように、または他のCNNの畳み込みとサブサンプリングと同様です。そのCNNサブ構造において、畳み込み層および最大プール層のサイズは、3×3および(2×2) - (3×3) - (4×4) - (4×4)である。このサブサンプリングの結果、N×1×15(特徴マップの数×周波数×時間)のフィーチャマップサイズが得られる。次に、2層RNNに供給され、最後の隠れ状態はネットワークの出力に接続される。
2.5。スケーリングネットワーク
モデルは、パラメータの数を2万の公差で100,000,250,000,150,000,1M、3Mに制御することによってスケーリングされます。現在のハードウェアの限界とデータセットのサイズを考慮すると、3Mパラメータネットワークは、構造の複雑さの近似上限を提供すると推定される。表1は、レイヤ幅(フィーチャマップまたは隠されたユニットの数)を含む異なる構造の詳細を要約する。層はk1c2とk2c1の場合は[1]、k2c2の場合は[2]に基づいています。 CRNNについては、畳み込み層の特徴マップの数の相対的な重要性がRNNの隠れユニットの数を上回っていることを示す予備実験に基づいて幅が決定される。ネットワークのパラメータの数を制御するために層幅が変更される一方で、深度および畳み込みアルゴリズム形状は一定に保たれる。したがって、学習された特徴の階層は保存され、各階層レベル(すなわち、各層)の特徴の数は変更される。これは、深さの幅の相対的重要性を考慮して、ネットワークの表現能力を最大化することである[17]。
Xception:深度分離可能な深層学習(Xception: Deep Learning with Depthwise Separable)
抜粋
我々は、畳み込みニューラルネットワークにおけるインセプションモジュールの解釈を、規則的な畳み込みと深さ方向の分離可能な畳み込み演算(奥行き方向の畳み込みとその後のポイント畳み込み)との間の中間ステップとして提示する。この光では、深さ方向に分離可能な畳み込みは、最大数の塔を有するインセプションモジュールとして理解することができる。この観察は、Inceptionモジュールが深さ方向に分離可能な畳み込みに置き換えられている、Inceptionに触発された新規な畳み込みニューラルネットワークアーキテクチャを提案する。我々は、Xceptionと呼ばれるこのアーキテクチャが、ImageNetdataset(Inception V3が設計された)上のInception V3をわずかに上回り、3億5000万の画像と17,000クラスを含むより大きな画像分類データセットでInceptionV3を大幅に上回ることを示す。 XceptionアーキテクチャはInceptionV3と同じ数のパラメータを持つため、パフォーマンスの向上は容量の増加によるものではなく、モデルパラメータの効率的な使用によるものです。
1 はじめに
畳み込みニューラルネットワークは、近年コンピュータビジョンのマスターアルゴリズムとして浮上し、それらを設計するためのレシピを開発することはかなり重要な課題であった。畳み込みニューラルネットワーク設計の歴史は、特徴抽出のための畳み込みの単純な積み重ねであり、空間サブサンプリングのための最大プール演算であるLeNet-スタイルモデル[10]で始まった。 2012年には、これらのアイデアがAlexNetarchitecture [9]に洗練されました。そこでは、畳み込み操作が複数のmax-pooling操作の間で繰り返され、ネットワークがあらゆる空間スケールで豊富な機能を学習できるようになっています。主に年1回のILSVRCの競技会に牽引されます。最初にZeilerとFergusを2013年に、次にVEGGアーキテクチャを2014年に導入しました[18]。この時点で、新しいスタイルのネットワークが登場しました.Segegedyらが導入したInceptionアーキテクチャ。 2014年にGoogLeNet(Inception V1)として、Inception V2 [7]、Inception V3 [21]、そして最近ではInception-ResNet [19]として洗練された。インセプション自体は、以前のネットワークインネットワークアーキテクチャ[11]に触発されました。最初の導入以来、インセプションは、ImageNetデータセット[14]やGoogleで使用されている内部データセットで最も優れたモデルのファミリーを持っていました。インセプションスタイルのモデルの基本ブロックは、いくつかの異なるバージョンが存在するインセプションモジュールです。図1では、Inception V3アーキテクチャで見られるInceptionモジュールの標準形式を示します。 Inceptionモデルは、そのようなモジュールのスタックとして理解することができます。これは、単純な畳み込みレイヤのスタックであった以前のVGGスタイルのネットワークからの出発点です。概念的には畳み込みに似ています(コンボルーションフィーチャエクストラクタ)が経験的に少ないパラメータでより豊かな表現を学習できるようです。彼らはどのように動作し、通常の畳み込みとはどのように異なるのですか?
1.1初期仮説
畳み込みレイヤーは、2つの空間次元(幅と高さ)とチャネル次元を持つ3次元空間のフィルターを学習しようとします。したがって、単一の畳み込みカーネルには、クロスチャネル相関と空間相関を同時にマッピングすることが任されています。インセプションモジュールの背後にあるこの考え方は、クロスチャネル相関と空間相関を独立して調べる一連の操作に明示的に分解することで、 。より正確には、典型的なインセプションモジュールはまず、1x1コンボリューションのセットを介してクロスチャネル相関を調べ、入力データを元の入力空間よりも小さい3つまたは4つの別々の空間にマッピングし、次にこれらの小さな3D空間の全相関を、 3x3または5x5の畳み込み。実際、インセプションの背後にある根本的な仮説は、クロスチャネル相関と空間相関が十分に分離されているため、それらを共同してトラップしないことが好ましいということです。1.コンボリューションのサイズを1つしか使用しない、 (例えば3x3)、平均プールタワーは含まれていない(図2)。このインセプションモジュールは、大きな1x1畳み込みとそれに続く出力チャンネルの重なり合わないセグメントで動作する空間畳み込みとして再定式化することができます(図3)。この観察結果は、当然ながら、パーティション内のセグメント数(およびそのサイズ)の影響はどのくらいですか?その仮説仮説よりもはるかに強力な仮説を立て、クロスチャネル相関と空間相関を完全に別々に写像できると仮定することは合理的でしょうか?
1.2畳み込みと分離可能な畳み込みとの間の連続
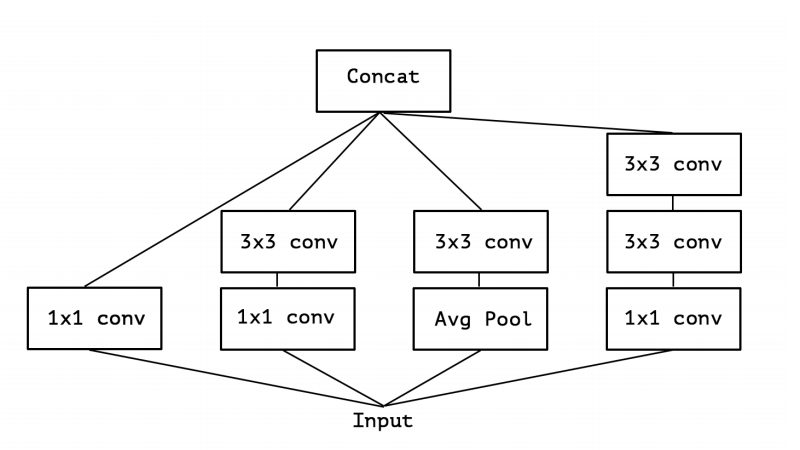 図1:カノニカルインセプションモジュール(インセプションV3)。
図1:カノニカルインセプションモジュール(インセプションV3)。
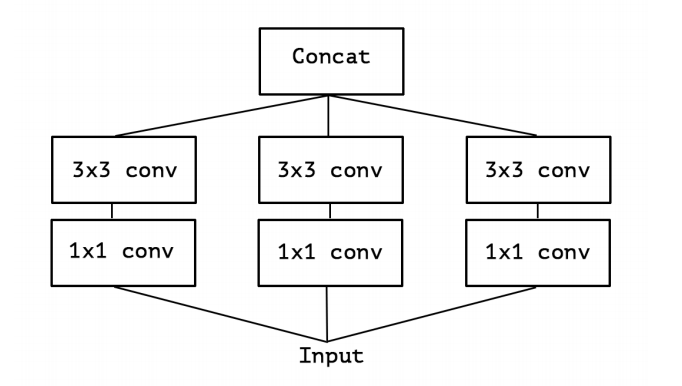 図2:簡略化されたインセプションモジュール
図2:簡略化されたインセプションモジュール
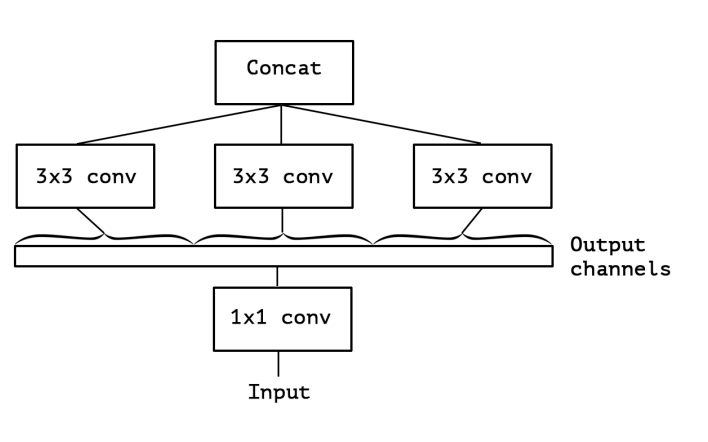 図3:簡略化されたInceptionモジュールの厳密に同等の再構成。
図3:簡略化されたInceptionモジュールの厳密に同等の再構成。
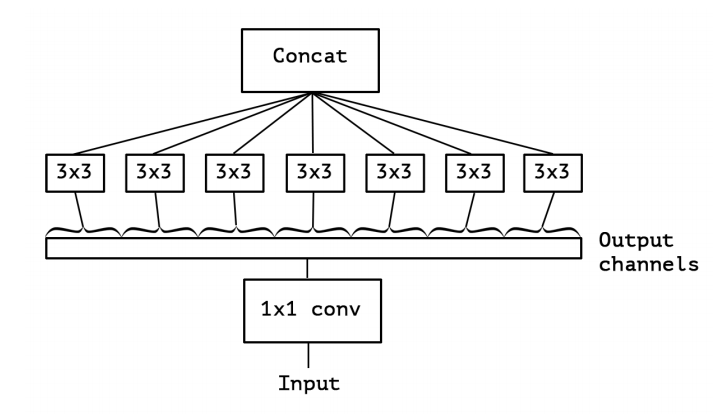 図4:Inceptionモジュールの「極端な」バージョン.1つの空間畳み込みがある
1x1コンボリューションの出力チャネル。
図4:Inceptionモジュールの「極端な」バージョン.1つの空間畳み込みがある
1x1コンボリューションの出力チャネル。
この強力な仮説に基づいて、Inceptionモジュールの「極端な」バージョンでは、最初に1x1畳み込みを使用してクロスチャネル相関をマップし、各出力チャネルの空間相関を別々にマッピングします。これは図4に示されている。我々は、この極端な形態のインセプションモジュールは深さ方向の分離可能なコンボリューションとほぼ同じであると言い、2014年の早い時期にニューラルネットワーク設計で使用されており、 2016年のTensorFlowフレームワーク[1]。TensorFlowやKerasのような空想フレームワークで一般に「分離可能な畳み込み」と呼ばれる深さ方向に分離可能な畳み込みは、深さ方向の畳み込み入力の各チャネル上で独立して実行される空間畳み込みに続いて、ポイントワイド畳み込み、すなわち、1x1畳み込みが行われ、深度畳み込みによって出力されたチャネルを新しいチャネル空間に投影する。これは、空間的に分離可能な畳み込みと混同してはいけません。これは画像処理コミュニティで一般に「分離可能な畳み込み」とも呼ばれます。インセプションモジュールと高度に分離可能な畳み込みとの間の2つの小さな相違点は、
・操作の順序:通常実行される(例えば、TensorFlowにおける)深度分離可能な畳み込みは、最初にチャネルワイズ空間畳み込みを行い、次に1x1畳み込みを実行するが、Inceptionは最初に1x1畳み込みを実行する。
•最初の操作後に非線形性があるかどうか。インセプションでは、両方の操作の後にReLUの非線形性が続きますが、通常、奥行き方向の分離可能な畳み込みは非線形性なしで実装されます。
最初の違いは重要ではないと主張します。特に、これらの操作は積み重ねられた設定で使用されるためです。第2の違いは重要であり、実験セクション(特に図10を参照)で調べることができます。また、正規のインセプションモジュールと深さ方向に分離可能な畳み込みの間にあるインセプションモジュールの他の中間的な形式も可能です。空間畳み込みを行うために使用される独立したチャネル空間セグメントの数によってパラメータ化された、規則的な畳み込みと深さ方向の分離可能な畳み込みとの間の離散スペクトル。このスペクトルの極端な極大値(1x1コンボリューションが先行する)は、単一セグメントの場合に対応します。深さ方向に分離可能な畳み込みは、チャネルあたり1つのセグメントが存在する他の極端に対応し、開始モジュールが数百のチャネルを3つまたは4つのセグメントに分割する。そのような中間モジュールの特性はまだ探究されていないようである。これらの観測結果から、Inceptionモジュールを深さ方向に分離可能なコンボリューションに置き換えることによって、つまり深さ方向に分離可能なコンボリューションのスタックとなるモデルを構築することで、アーキテクチャの継承ファミリを改善することが可能であることを示唆しています。 TensorFlow。以下では、Inception V3と同数のパラメータを用いて、このアイデアに基づく畳み込みニューラルネットワークアーキテクチャを提示し、2つの大規模画像分類タスクにおけるInception V3に対する性能を評価する。
2 これまでのワーク
現在の研究は、以下の分野における先の努力に大きく依存している。
•畳み込みニューラルネットワーク[10,9,25]、特にVGG-16アーキテクチャ[18]。これは、いくつかの点で提案されたアーキテクチャに概略的に類似している。
•畳み込みニューラルネットワークのインセプションアーキテクチャファミリー[20,7,21,19]。最初に畳み込みを複数の枝分れにチャネルを逐次的に、次に宇宙で順調に処理する利点が示されました。
•深さ方向に分離可能な畳み込み。提案されたアーキテクチャは完全にベースになっています。ニューラルネットワークにおける空間的に分離可能な畳み込みの使用には長さがありますが、少なくとも2012年に戻っていますが(より早いものであろうが)、奥行き方向のバージョンは最近のものである。 Laurent Sifreは、2013年にGoogle Brainのインターンシップで深さ方向に分離可能な畳み込みを開発し、AlexNetで使用して、小さなゲインの精度と収束速度の大幅な向上、さらにはモデルサイズの大幅な縮小を実現しました。彼の作品の概要は、ICLR 2014 [23]のプレゼンテーションで最初に公開されました。詳細な実験結果はSifreの論文、セクション6.2 [15]に報告されている。深さ方向に分離可能な畳み込みに関するこの初期の研究は、変形不変散乱[16,15]のSifreとMallatの先行研究に触発された。後で、深さ方向に分離可能なたたみ込みが、Inception V1とV2 [20、7]の第1層として用いられた。 Googleでは、Andrew Howard [6]は、深さ方向に分離可能な畳み込みを使用してMobileNetsと呼ばれる効率的なモバイルモデルを導入しました。 Jin et al。in 2014 [8]およびWang et al。 2016年に[24]は分離可能な畳み込みを用いた畳み込みニューラルネットワークのサイズと計算コストを削減することを目的とした関連研究を行った。さらに、我々の研究は、TensorFlowフレームワーク[1]に深さ方向に分離可能な畳み込みの効率的な実装を含めることによってのみ可能である。
•Heらによって導入された残存接続。 [4]では、提案されているアーキテクチャが広く使用されています。
3 例外アーキテクチャ
奥行き分離可能な畳み込み層に完全に基づく畳み込みニューラルネットワークアーキテクチャを提案する。実際、畳み込みニューラルネットワークの特徴マップにおけるクロスチャネル相関および空間相関のマッピングは、完全に切り離すことができるという、以下の仮説を立てる。この仮説は、インセプションアーキテクチャの根底にある仮説の強力なバージョンであるため、我々は、「エクストリーム・インセプション」を意味する提案されたアーキテクチャ「Xception」と命名する。ネットワークの仕様の完全な記述が図5に示されている。ネットワークの特徴抽出ベースを形成する。我々の実験評価では、画像分類のみを調べるため、畳み込み基底の後にロジスティック回帰層が続きます。任意選択的に、ロジスティック回帰層の前に完全に連結された層を挿入することができ、これは実験評価セクション(特に図7および図8参照)で探索される。要約すると、Xceptionアーキテクチャは、深さ方向に分離可能な畳み込み層と、残りの接続との線形積み重ね体である。この畳み込み層は、14個のモジュールから構成されている。これにより、VGG-16 [18]などのアーキテクチャーとは異なり、Keras [2]やTensorFlowSlim [17]などの高レベルライブラリを使用したコードは30〜40行しかかかりません。むしろはるかに複雑である定義V2やV3のようなアーキテクチャーとは異なります。
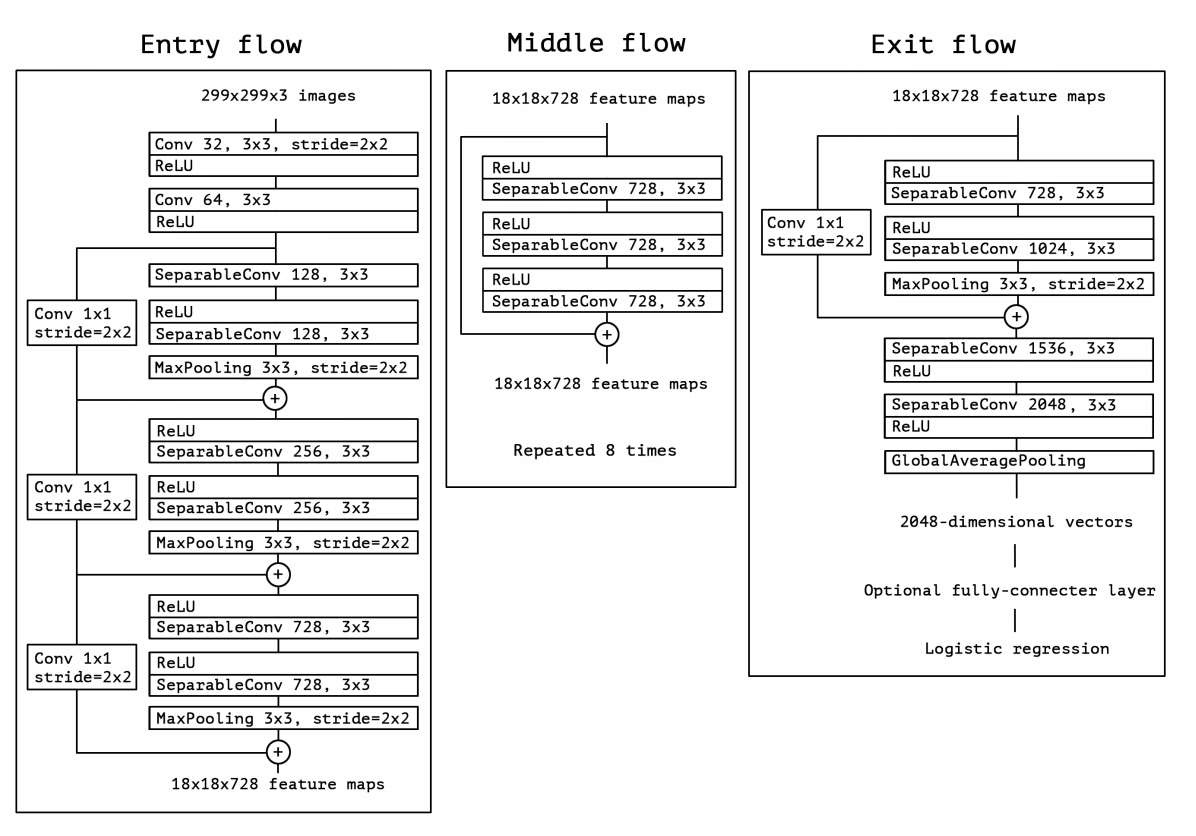 図5:Xceptionアーキテクチャ:データは最初に入力フローを経て、次に8回繰り返される中間フロー、最後に出口フローを経ます。 ConvolutionおよびSeparableConvolutionのすべてのレイヤーにバッチ正規化[7]が続くことに注意してください(図には含まれていません)。 すべてのSeparableConvolutionレイヤーは、1の深さ乗数を使用します(深度拡張なし)。
図5:Xceptionアーキテクチャ:データは最初に入力フローを経て、次に8回繰り返される中間フロー、最後に出口フローを経ます。 ConvolutionおよびSeparableConvolutionのすべてのレイヤーにバッチ正規化[7]が続くことに注意してください(図には含まれていません)。 すべてのSeparableConvolutionレイヤーは、1の深さ乗数を使用します(深度拡張なし)。
参考