はじめに
長い間mrubyのJITは32bitのx86のみサポートでしたが、最近64bitのx86アーキテクチャ(以下x64)も対応するようになりました。64bit化しようと思った理由はh2o に組み込んで遊ぶためです。また、中古でパソコンを買ってLinux 64bit版を入れたからです。
32bitのみで開発したmrubyのJITを64bitでも動くようにするには新しいCPUほどではないのですが、いくつかのトレードオフがあります。それらのトレードオフについてなにを考えて決定したのか記しておくことは、自分を含む今後JITコンパイラを開発する者にとって有益ではないかと思います。
NaN Boxing
mrubyのJITではオブジェクトの内部表現としてNaN Boxingを採用しています。NaN boxingについては、Constellationさんの解説記事 を読んでいただくのが良いと思います。
簡単にNaN Boxingを説明すると、浮動小数点数の標準的なフォーマットIEEE754では数ではない数(NaN)がたくさんの種類(50bitくらい)とってあります。ここにポインタ情報と型情報を含めることにより、浮動小数点数をオーバーヘッドなしに扱うことが出来ます1。
NaN Boxingを使う理由
型情報のタグが大きくなる欠点はありますが、今後ますます重要が高まると思われる浮動小数点演算が高速化出来るのは魅力なので、mrubyのJITでは採用しています。また、mrubyの配列の構造はNaN Boxingを採用することにより、SSEのようなデータ並列命令を使うのに適した形になっています2。まだ、実験段階でサンプルがちょっと動いただけですが、PArrayというSSE命令対応のベクターライブラリがmrubyのJITに同梱されています。
NaN Boxingの64bit化
Constellationさんの解説記事でも述べられている通り、NaN Boxingは64bit環境では結構扱いにくいです。x64は64bitであるといっても実際には48bitしか使ってことを利用して48bitの生のアドレスを格納するという実装が一般的なようです。しかし、mrubyのJITでは次のような理由からこれとは違う方法を取っています。
- 32bitを超えるアドレスを扱うにはビットマスクをして上位のタグをクリアする必要がある
- mrubyでは64bitシステムで動いていてもそれほど大きなヒープ領域を必要としないと考えられる(死亡フラグか?)
このような理由から、32bit版と同様にアドレスは32bitだけ使うことにしました。
32bitでは当然生アドレスは格納できないので、ヒープ上の適当な場所からのオフセットを取ることでアクセスするようにしています。その適当な場所として、mrb_state *型の変数mrbを使用することにしました。mrbはmruby中のほとんどの関数からアクセスできるし3、mrubyのJITではレジスタに割り当ててある(r13)ので64bitのリテラルを引っ張ってくるより高速化が期待できます。
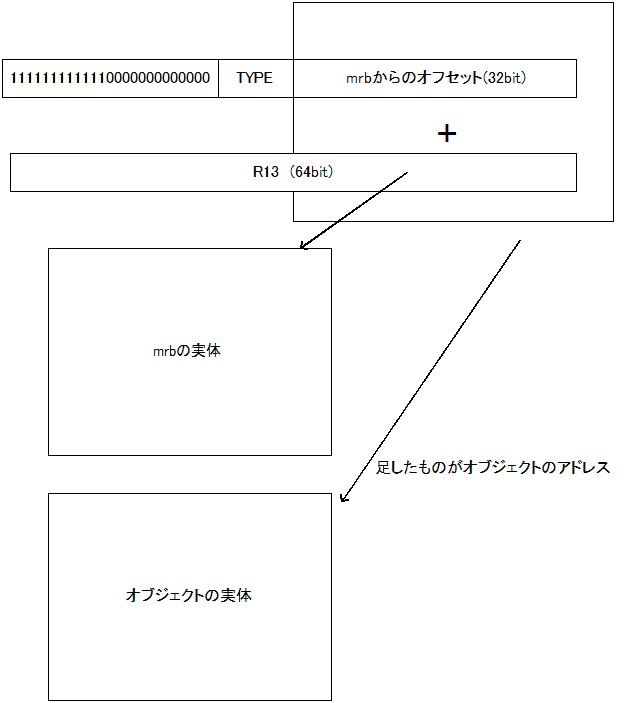
ただし、
- 31bitを超えるサイズのヒープはサポートできない4
- mrbが複数ある場合まずい場合がある
- mmapとかを使いまくるメモリアロケータだとうまくいかない恐れがある
といった心配がありますが、今の所は動いているようです。
命令の違いの吸収
x86とx64は32bitと64bitの違いはあるが所詮は同じCPUなのでそれほど違いはないのでは?って思うかもしれませんが意外と相違点があります。この相違点を吸収するために実際の機械語命令ではなくそれより少し抽象度の高い命令をXbyak5のメソッドとして用意してそれをx86とx64用にそれぞれ用意しています。
x86用のメソッド定義
x64用のメソッド定義
ただし、すべての命令を抽象度の高い命令でコンパイルするわけではなく、一部実際の機械語命令も現状は使っています。条件付きブランチとか論理演算とか全部用意していると膨大な数になるからです。ただし、今後ARMに移植したいとかそういうことになればそうは言ってられないでしょう。
抽象度の高い命令はとはたとえばこんな感じです
| 名前 | 意味 |
|---|---|
| emit_local_var_read | RITE VMのレジスタをCPUレジスタに入れる |
| emit_local_var_int_value_read | RITE VMのレジスタをCPUレジスタに入れる。その場合に整数を浮動小数点数に変換する |
| emit_local_var_value_read | RITE VMのレジスタのうち値の部分(下位32bit)をCPUレジスタに入れる |
| emit_local_var_ptr_value_read | RITE VMのレジスタのうち値の部分をポインタとしてCPUレジスタに入れる(reg_mrbの値を加える) |
| emit_load_literal | リテラルをCPUレジスタに入れる。0とか1とかは特別扱いして効率の良いコードを生成する |
レジスタ
mrubyのJITではよく使う構造体がいくつかあります。それらはCPUのレジスタに格納しています。このレジスタはメソッド呼び出しやC言語の関数呼び出しでも壊れない必要があるので、意外と数に余裕が無いです。x86だと16個のレジスタが使えるので余裕かと思ったら、Cの関数呼び出しの引数のためのレジスタとか(これはCの関数呼び出しをすれば当然壊れる)あまり使えないレジスタが多くて結局x64でもレジスタに余裕はありません。
レジスタはこのように使っています
| 目的 | x86 | x64 |
|---|---|---|
| RITE VMのレジスタ(regs)の先頭アドレス | ecx | r12 |
| mrb (mrb_state *の構造体) | esi | r13 |
| 現在のcontext (mrb->c) | edi | r14 |
| RITE VMで使う各種変数 (ローカル変数pcのアドレス) | ebx | rbx |
| テンポラリ1 | eax | rax |
| テンポラリ2 | edx | rdx |
また、r15にはmrbjit_instance_allocのアドレスが入っています。理由は後述
ABI
mrubyは基本的にCで書かれているのでmrubyのJITでも各種ランタイムを利用するために生成した機械語はCの関数を呼ぶ必要があります。ところが、x86とx64では引数の渡しかたが全く違います。x86はスタックで引数を渡すのですが、x64はレジスタで渡します。また、mrubyではオブジェクトが構造体(mrb_value)でこれを引数に含める必要があります。構造体を渡す必要があると言うことでさらに面倒さを増しています。
mrubyのJITではemit_arg_pushという抽象度の高い命令を用意して、x86とx64のABIの違いを吸収しています。これについてはコードを見た方が早いのでコードを示します。
まず、x86版のもの
void emit_arg_push(mrb_state *mrb, mrbjit_code_info *coi, int no, Xbyak::Reg32 reg)
{
push(reg);
}
実に簡単な定義ですね。いろいろ変な引数がありますが、noってのに注目してください。これは、関数の何番目の引数かってのを示すものです。x86では何番目だろうと引数に突っ込むだけなので使ってないです。
次にx64のもの
void emit_arg_push(mrb_state *mrb, mrbjit_code_info *coi, int no, Xbyak::Reg64 reg)
{
mov(argpos2reg[no], reg);
}
argpos2regってなんだろう?って思うでしょうが、こんな感じの配列です。
Xbyak::Reg64 argpos2reg[6];
argpos2reg[0] = rdi;
argpos2reg[1] = rsi;
argpos2reg[2] = rdx;
argpos2reg[3] = rcx;
argpos2reg[4] = r8;
argpos2reg[5] = r9;
つまり、引数の位置にあたるレジスタに代入しているわけです。Xbyakはレジスタがオブジェクトでファーストクラスなんでこういう芸当が出来てとても便利です。お気づきかもしれませんが、7つ以上の引数を渡す場合は動きません。この場合はスタックにpushする処理にしないといけないのですが、そんな引数の多い関数を使っていないので手を抜いています。
ちょっと込みいった話
通常はこの程度の工夫でABIは吸収できそうなのですが、mrubyではこれでは不十分です。それは、オブジェクトを表現するmrb_value型ってのが64bitの構造体(厳密には構造体と浮動小数点数をメンバーに持つ共用体)なのです。mrb_valueを引数として渡す処理はx86ではpushを2命令、x64では64bitのレジスタの代入の1命令になります。そうすると、引数の位置をどうするのかという問題にぶつかります。
mrubyのJITでは、emit_arg_push_nanという抽象度の高い命令を用意して、対処しています。x86版についてはこの中で、2回pushしています。
callが届かない問題
x64はcallは即値では32bitの範囲しか届かないという素敵仕様です。そのため、C言語とかはコンパイラやリンカが32bitの範囲を超えてcallしないといけない場合はジャンプテーブルを作成してそこにcallするようにしています。
しかし、mrubyのJITではそんなジャンプテーブルを作ってメモリを使うのは嫌だったので別の方法を執りました。r15レジスタにmrbjit_instance_allocのアドレスを入れておいて、r15からのオフセットを付けてcallするようにしています。mrbjit_instance_allocなのはおそらく一般的に一番使う関数だからです。mrbjit_instance_allocを呼び出すときはオフセットが0になって高速化と省メモリが望めるのではないかなと思います。
今後の展望
現状、x64版のmrubyのJITはx86版より間違いなく遅いです。たくさんあるレジスタを活かし切れていないからです。これを活かしきるにはレジスタに固定的な役割を割り振るのではなく生存期間を解析して動的にレジスタを割り振る必要があるでしょう。これは多くを作り直す必要がある程度に大変なので、本当に将来の話です。
とりあえず可能そうなのは、C言語で書かれたランタイムを呼び出すのに余計なメモリアクセスを無くす対策です。
たとえば、
a + "1"
というプログラムは次のようにRITE VMにコンパイルされるんだけど
1 002 OP_STRING R2 L(1) ; "1"
1 003 OP_ADD R1 :+ 1
この+は文字列に対する+なので文字列の加算のランタイム関数が呼ばれるわけです。現状では、R2に当たるメモリ領域に"1"というストリングオブジェクトを書きこんでから、CPUレジスタを書き込んで文字列の加算(mrb_str_plus)を呼び出すのですが、直接引数に当たるレジスタ(rdx)に文字列オブジェクトを格納すればメモリの読み書きを1回ずつ減らせるわけです。
すぐにできそうだけど、でっかいバグがまだあるのでそれが取れてからですね。この手の小細工は本当にバグを誘発しますから。
おしまい