ドット絵をきれいに拡大するためのツールを http://mitaki28.info/pixcaler/ にて公開しています。
- デモページ: http://mitaki28.info/pixcaler/
- Google Chrome 推奨
- レポジトリ: https://github.com/mitaki28/pixcaler
適用例
- キャラチップを拡大した例【素材: 白螺子屋様】
- マップチップを拡大した例【素材: 白螺子屋様】
- ゲーム画面のスクリーンショットを拡大した例【 https://opengameart.org/content/castle-platformer 】

- ※1ドット1pxにするため、nearest neighbor 法で1/2縮小しています


使い方
- 以下の条件を満たすドット絵を前提としています
- 1ドット1px
- 拡大されたドット絵の場合は適切な倍率に縮小する必要があります
- bilinear 法など、不可逆な方法で拡大されていたり、拡大倍率が整数でない場合、簡単には1ドット1pxに復元できません
- 拡大されたドット絵の場合は適切な倍率に縮小する必要があります
- jpeg 圧縮などでノイズがかかっていない
- JPEG圧縮ノイズなど、画像にノイズがかかっている場合は不自然な結果になる可能性があります
- png 形式(他の形式は未検証)
- 画像サイズに制限はありませんが、画像サイズ分のメモリをブラウザが使用するため、600x600程度の画像までにとどめておいたほうが無難です
- 1ドット1px
- 特にスクリーンショットの拡大について、一般にWeb上で公開されている画像は、jpeg 形式だったり、拡大されていたりして、前提条件が崩れることが多く、そのまま変換してもうまくいかないことが多いです
- 画像の拡大処理はクライアントサイドでWebGLを使って実行されます。
- タブを切り替えたりブラウザを非表示にしたりしてレンダリングが止まると拡大処理も止まるので注意が必要です
実装の詳細
- chainer-pix2pix をベースにドット絵向けに改造して実装しています
- 以下の素材を機械的に重ね合わせて合成したデータを用いて学習しています
-
カミソリエッジ様が配布されている First Seed Material 素材(高解像度版)のカラーバリエーション約7000枚
- サイト閉鎖のため、規約のアーカイブページのリンクになっています
- M+フォント全種から、light, thin を除いたもの
- コミュ将様の配布されているタイルセット(RTP不使用版)
-
カミソリエッジ様が配布されている First Seed Material 素材(高解像度版)のカラーバリエーション約7000枚
- 合成したデータに対して、 nearest neighbor 法による縮小を行い、元データを復元する方法を学習させています
- 拡大時には32x32pxのブロック単位で拡大を行っています
- 実際には 64x64px の範囲を拡大し、上下左右16pxを切り捨てています
- 画像の上下左右には reflect padding を入れて拡大しています
- 具体的にどのような動作になっているかは、デモを実行するとわかりやすいです
- デモ版の実装には、上記の実装を keras に移植し、 tensorflow.js で利用可能なモデルを生成しています
- ただし、現状、 keras 版は移植の過程で loss 関数がバグっています、が、問題なく学習できているため、そのままにしています→修正しました(後述)
- デモ版は読み込み速度を考慮してモデルサイズを抑えるため chainer 実装のデフォルト値よりもチャネル数を4分の1にして学習しています
- 詳細については https://github.com/mitaki28/pixcaler の README.md も参照してください
既存手法との比較
- Super XBR と比較します。こちら の node.js 移植を使いました。
- 直接実行できる実装がこれしかなかったため
- (左、上が Super XBR です)
キャラチップ

- キャラチップの拡大については、重点的に学習しているだけあって、この手法の方が圧倒的に自然な仕上がりになっています。
マップチップ

- マップチップについては、
- この手法のほうが、エッジがより細く、はっきりした仕上がりになっています
- 草の部分について、xbr は草の1本1本がはっきり描かれているのに対し、この手法は、ぼかした感じになっています
スクリーンショット

- スクリーンショットの拡大について、
- 全体的に見てかなり似通った拡大(特に塗りとエッジの平滑化)になっており、最終的に似たような拡大法を学習していることがわかります
- 一方、この手法の方が線が細くより鮮明な拡大になっています
備考
- なお、実行時間は Super XBR の数十倍〜数百倍かかります
- リアルタイム処理には向かないので、キャラチップやマップチップを事前に変換しておく用途がメインになると思われます
考察
なぜ SuperXBR と似通った結果になったのか
このNNが学習した拡大法は本質的にXBR法と同じ考え方がベースになっているからです。
XBR法は、
- 拡大前のピクセルを拡大後の2x2格子の左上に配置し、
- 各2x2格子について、1 以外の残り3点を補完する
というアルゴリズムです。
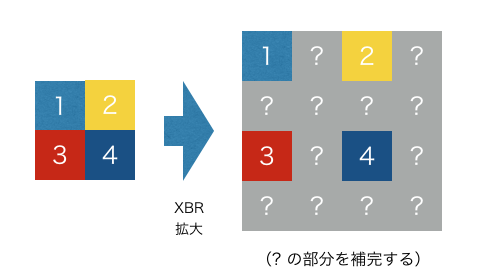
一方、 pix2pix では変換元と変換先の各ピクセル値の差を誤差関数としています。
今回は、変換先のデータを nearest neighbor 法による縮小(2x2格子の左上の点をサンプリング)→ nearest neighbor 法による再拡大(各ピクセルで拡大後の2x2格子を埋める)という手順で変換前のデータを生成しています。このような手順を踏んだ場合、変換先のデータの各2x2格子の左上の点は、変換先のデータと全く同じピクセルになります。
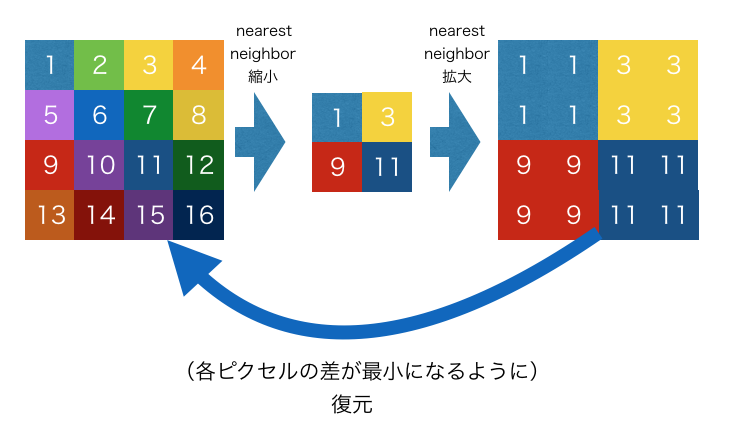
変換元と変換先の各ピクセル値の差を最小化する場合、この2x2格子の左上の点については、そのままにしておくのが最適解となるため、実質的に、拡大前のピクセルを各2x2格子上の左上に配置し、残り3点を補完することになります。
実際、この手法で拡大した画像は2x2格子の左上の点をサンプリングすることによって、完全に拡大前の画像に戻ります。
この手法は、XBR法の補完処理部分をニューラルネットワークに置き換えたものといえるかもしれません。
まとめ
- pix2pixをベースにきれいにドット絵を拡大できるツールを作成した
- 既存の手法と比較してよりはっきりとした拡大が可能になった
- この手法はSuperXBR法をニューラルネットワークで拡張したものかもしれない
(2018/5/9 追記) loss 関数の修正
keras 版では loss 関数の実装がバグっていたのを修正しました。結論から言うと、 adversarial loss が機能していなかったようです。
(左がバグ修正前、右がバグ修正後)

バグ修正後は、細部まで鮮明に拡大されていることがわかります(特に草地の部分)
マップチップの草地のように、拡大結果として、様々なパターンが考えられ、一意に定まらないような拡大では、単純に元画像とのピクセル値の誤差を最小化する場合には、拡大結果として考えられるパターンすべての平均を取るのが一番楽な解決策になってしまい、結果としてぼんやりした画像になります。
adversarial loss は、「本物の画像にどれだけ似ているか」という誤差であり、この誤差を加えることで、より鮮明で本物に近い画像が生成されるようになります。
このことは、元論文でも言及されています。


鮮明な変換になる一方、細部を想像で描くため、出力画像がやや不安定になるという問題もあります。例えば上のキャラチップの拡大では、境界がギザついたり左目の右側あたりが歪んでしまっています。
キャラチップやスクリーンショットについても、よりはっきりとした変換は可能ではあるのですが、これらのような線がもともとはっきりしている画像は、拡大結果が比較的予想しやすいため、ピクセル値の誤差を最小化するだけでも、そこそこはっきりした仕上がりになり、むしろ境界の歪みやノイズが発生するデメリットのほうが大きいケースもありそうです。
そのため、デモ版では、拡大時にどちらの方式で拡大するかを選択できるようにしています。