はじめに
Deep Learningを始めて、学習/認識できるようになって、次に頑張らなくてはいけないのが認識率の向上。
てことで、ファインチューニングのお話。
ファインチューニングとは
すでに学習済みのモデルを使って、自分用に賢くする仕組み。
一から学習させるよりも楽で、しかも認識率がよいのでいいことづくめ。
ただし、自分が認識させたいものと合っている学習済みモデルを探す必要がある。
具体的な話
ニューラルネットワークにおいて、ニューロンの重みや閾値は、最初は初期値で設定され、逆伝播によって調整されていきます。
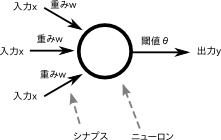
この初期値を、すでに学習済みのモデルの値を利用しようというのがファインチューニングです。
Caffeの学習済みモデル
実は「Model Zoo」というものが用意されおり、ここに公式/非公式の学習済みモデルが置かれている。
公式の学習済みモデル
公式には、以下の学習済みモデルが用意されている。
ちなみに、ソルバーやネットワークが記述されたProtoTxtは「caffe\models」にあるものを利用する。
| 名前 | 内容 | URL |
|---|---|---|
| BVLC Reference CaffeNet | 一番標準的なサンプル(AlexNetをシンプルにしたもの) | http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel |
| BVLC AlexNet | いわゆる「AlexNet」 | http://dl.caffe.berkeleyvision.org/bvlc_alexnet.caffemodel |
| BVLC Reference R-CNN ILSVRC-2013 | R-CNNのサンプル | http://dl.caffe.berkeleyvision.org/bvlc_reference_rcnn_ilsvrc13.caffemodel |
| BVLC GoogLeNet | いわゆる「GoogLeNet」 | http://dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel |
非公式の学習済みモデル
「コミュニティモデル」と呼ばれるもので、Caffeのユーザが作成したものになる。
「Model Zoo」のWikiページからたどって取りに行くことになる。
大体、GitHub Gistに置かれている。
※全て英語なので、探すのがちょっと大変 ^^;
実行コマンド
取得した学習済みモデルを使用してファインチューニングするには、「caffe.exe -solver solver_file -weights caffemodel_file」という感じで行う。
もちろん自分の環境に合わせてファイルを修正(自分の環境用の画像データベースを指定するなど)する必要がある。
注意事項
- 入力画像サイズは変えてはいけない(Dataレイヤーのtransform_param→crop_size)
- 分類数を変えるときは、レイヤー名を変更すること(deploy.prototxtの修正も忘れずに)