はじめに
リクルートライフスタイル Advent Calendar 2016の2日目の記事ではELB経由のfluentd Aggregatorを安定化するためにやった3つの対策について書きました。
前記事で書いたようにAggregatorクラスタの数が増えて手動で行っていたデプロイが大変になってきました。また開発メンバーが増えたときに、デプロイ方法を共有してミスなく行えるようにするのも大変です。
そこでfluentd Aggregatorのローリングアップデートを自動化したくなり、CloudWatchEvents + Lambda + SQSで仕組みを作りました。
fluentdのデプロイ時に気をつけること
fluentdはローカル上にバッファを持っているため、それを出力し終える前にインスタンスを落としてしまうと、ログのロストが発生します。
それを防ぐためにはバッファがなくなるまで待って、その後にインスタンスを落とすことが必要になります。
それを実現するために今回の仕組みを構築しました。
作った仕組み
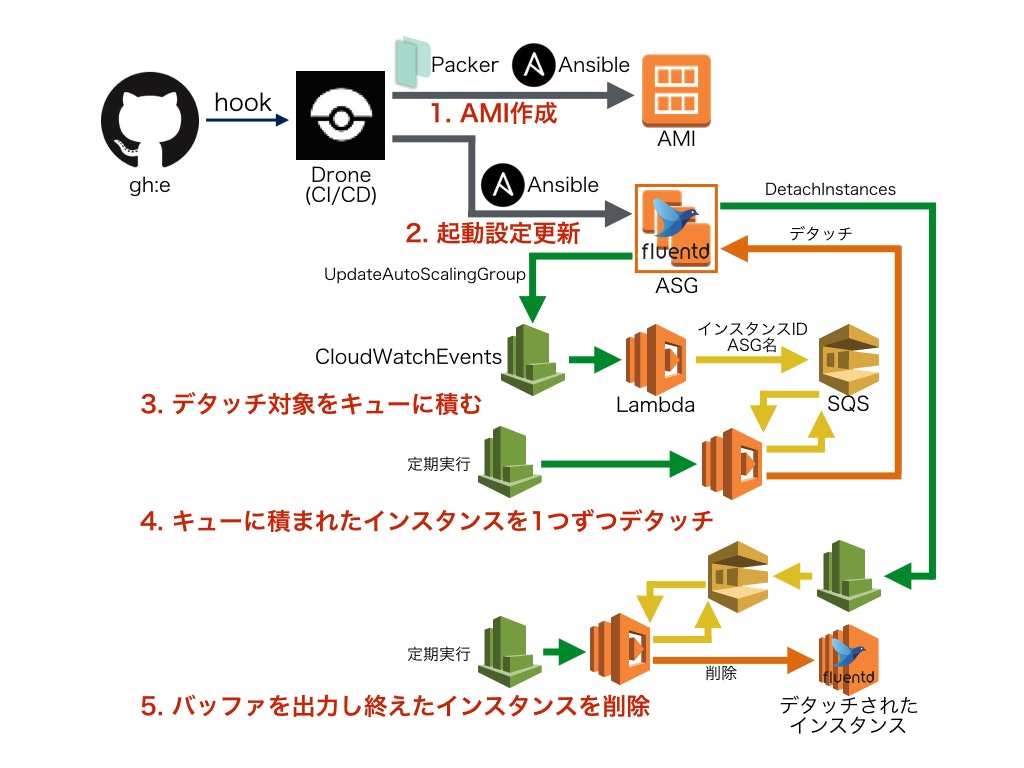
図の通り5つのステップから構成されています。
- AMIを作成する
- オートスケーリンググループの起動設定を更新する
- オートスケーリンググループの更新をトリガーにして、古いインスタンスをSQSに積む
- SQSを定期的にポーリングして、オートスケーリンググループからインスタンスをデタッチする
- デタッチしたインスタンスをSQSに積み、定期的にポーリングし、バッファがなくなったら削除する
各ステップについて順番に解説します。
1. AMIの作成
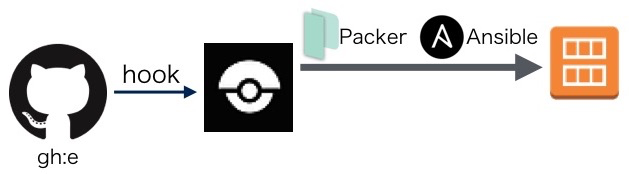
gh:eでリリースタグを作成するとCI/CDサーバー(OSS版Drone)から、Packer + AnsibleでAMIが作成されます。特に特別なことはしていません。
2. 起動設定更新
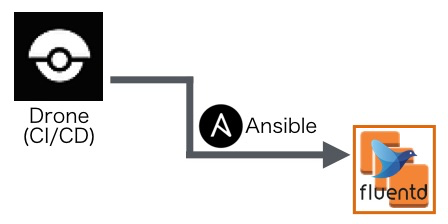
新しいAMIを指定した起動設定を作成します。
起動設定の作成およびオートスケーリンググループへの適用はAnsibleを使っています。
Terraformだと過去の起動設定を消してしまいますが、Ansibleではそういったことがなく、切り戻ししやすいため、ここではAnsibleを使っています1。
ここからのフローをDrone上で行うこともできなくはないものの、タスクが長くなってしまうと他のビルドタスクがスタックしてしまうため、ここから先はLambdaなどに任せます。
3. デタッチ対象をキューに積む
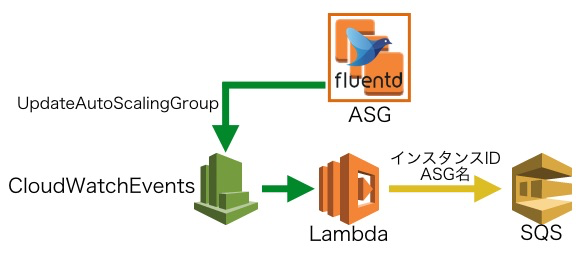
オートスケーリンググループの起動設定を更新するイベントをCloudWatchEventsでフックし、Lambdaを実行します。
Lambdaでオートスケーリンググループに含まれるインスタンスIDとオートスケーリンググループ名を、各インスタンスごとにSQSへ積みます。
4. キューに積まれたインスタンスを1つずつデタッチ
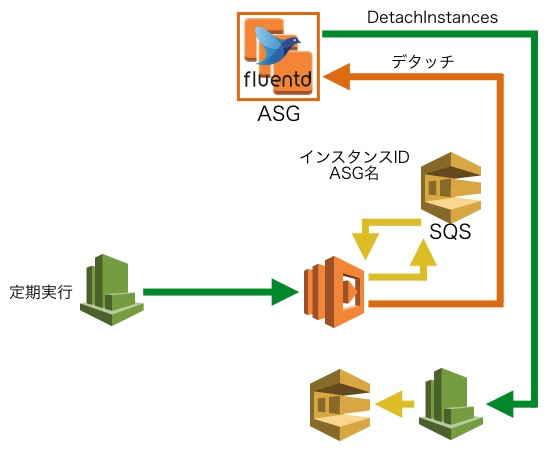
キューに積まれたインスタンスを1つずつオートスケーリンググループからデタッチしていきます。
このときにオートスケーリンググループ内のデタッチ中のインスタンスが一定以上にならないようにしています。
もしデタッチ中のインスタンスが一定数以上ある場合はスキップして次の実行まで待ちます。
デタッチイベントを更にCloudWatchEventsでフックしキューに積みます。
5. バッファを出力し終えたインスタンスを削除
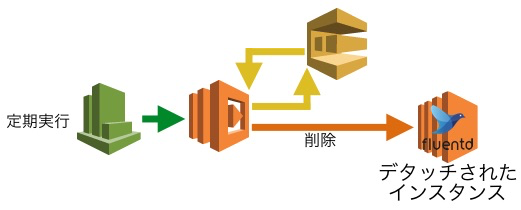
デタッチしたインスタンスの一覧が入っているキューをポーリングし、バッファーを出力し終えたfluentdのインスタンスを削除します。
将来的にはバッファーのチェックと強制flush処理も入れようと思っていますが、今は一定時間経過したインスタンスを削除するという方法でやっています。
障害時の切り戻し
オートスケーリンググループの起動設定を戻すだけです。
正常に動作していたときの起動設定およびAMIは残っているので問題なく、また起動設定の更新のイベントは同じように発生するため、残りのフローは同じように実行されます。
デプロイスクリプトでエラーが出た場合はキューが削除されないため、修正したバージョンをデプロイすることで解決できます。
おわりに
ピタゴラスイッチっぽくデプロイ・後片付けまでやってくれる仕組みを作ることができました。
うまくCloudWatchEventsとSQSを使うことで、並列化やエラー時のリトライなどの処理を簡潔にすることができます。
この仕組みも最初から全部一気に作ったわけではなく、1, 2を先にやり、次に5、最後に3, 4の部分を作成しました。
やることを切り分けることで、順次、必要なところから自動化できたのは良かったと思います。
この仕組みはAggregator以外にもfluentdを使っているインスタンスであれば、応用できる構成になっています。
ただ思っていた以上に複雑な仕組みになってしまったので、もう少しシンプルな形にできないか、今後試してみようと思います。
-
他のインフラ部分は基本的にTerraformで管理しています。 ↩