リクルートライフスタイル Advent Calendar 2015の21日目の記事です。
仕事では全サービス横断のリアルタイムログ収集・可視化・分析基盤のシステムの開発運用をしています。
1. 何をやる?
最近話題のApache Spark MLlibを使って機械学習し、Spark Streamingでその学習したモデルを使って判定します。
- 全体図
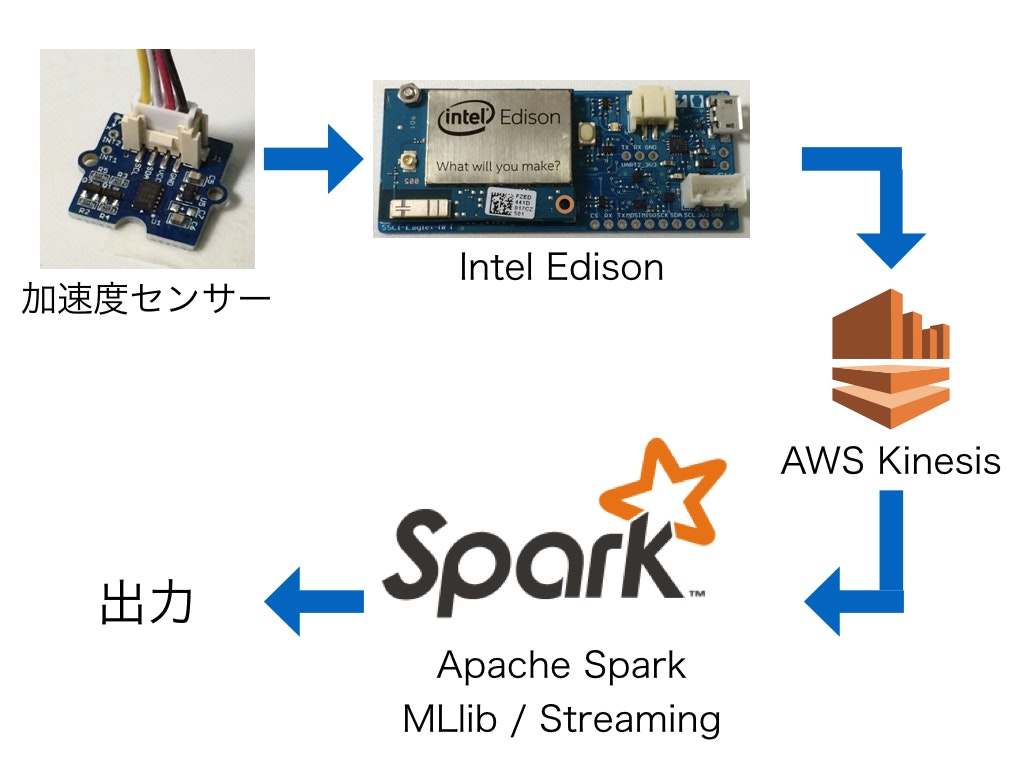
体に取り付けた加速度センサーの値から、つけている人が「立っている」か「座っている」かを機械学習します。
さらに、その加速度センサーの値をリアルタイムに流し、学習したモデルから「立ち」「座り」状態を予測しようというシステムです。
データの送信には小型でLinuxが動くボードのIntel Edsionを使います。
1.1. なぜ加速度センサーの値で判定できるのか?
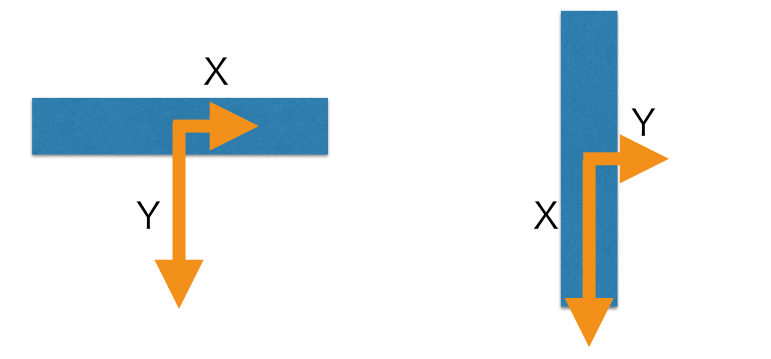
加速度センサーには地面の方向に向かって重力加速度がかかります。
重力加速度は、水平に置いた状態では左図のようにセンサーのY軸方向にかかり、垂直に置いた場合には右図のようにX軸方向にかかります。
上図では簡略化のために2軸で描いていますが、実際にはZ軸方向もあります。
太もものあたりにセンサーを取り付けると「立っている」か「座っている」かでセンサーの向きが変わります。
向きが変われば重力加速度のかかる向きも変わります。
したがって、加速度のかかっている方向さえ特定できれば「立ち」か「座り」かが判定できます。
2. データソースを作る
2.1. 用意するもの
Intel Edison + スイッチサイエンス版Eaglet

EdisonはLinuxが動くSDカードサイズのコンピューターです。
2コア500MHzのAtom CPU、1GBのメモリに加えてWiFiも搭載されており、この小ささでありながら一昔前のパソコンと同じくらいのスペックを持っています。
Edisonは裏側にセンサーなどをつなぐためのコネクタが出ていますが、非常に細かいコネクタで、そのままでは工作に使えません。
別途、拡張ボードを使う必要があります。
拡張ボードには純正のEdisonキット for ArduinoやEdison Breakout ボードキットなどがあります。
今回は、各種センサーがケーブル1つで接続できるGroveを接続できるスイッチサイエンス版Eagletを使用します。
GROVE - I2C 三軸加速度センサ ADXL345搭載

センサーには先ほど説明したGroveシリーズを使います。
Eagletとの接続はケーブルを挿しこむだけでOKです。逆方向には刺さりません。

2.2 Kinesisへデータを流す
Edisonからセンサーの値を取得してKinesisに流すプログラムは、以下のリポジトリにおいています。
https://github.com/mia-0032/edsion-adxl345-to-kinesis
Edisonのセットアップ手順やプログラムの使い方などはEaglet + Intel EdisonからKinesisへ加速度センサーの値を送る - Qiitaにまとめていますので、そちらをご覧ください。
root@myedison:~# python sender.py <your_stream_name>
とすればKinesisにセンサーデータが延々と流れます。
2.3. 体への取り付け
こんな感じでさくっと取り付けてしまいましょう。

もし常用するのであればケースに入れた方が良いと思いますが、実験なのでテープで固定してUSBから給電しています。
Edisonと加速度センサーも両面テープで板にくっつけただけです。
見た目はよくないですが、これでデータソースは完成です!
3. Sparkアプリケーションを作る
Spark MLlib, Spark Streamingを使ってアプリケーションを作ります。
作ったアプリケーションのコードは以下に公開しました。
https://github.com/mia-0032/spark-ml-adxl345-from-kinesis
3.1. アプリケーションの流れ
大きく分けるとバッチ処理部分とストリーム処理の部分にわかれます。
- 「立ち」「座り」状態でサンプリングした加速度データをMLlibの決定木を使って学習しモデルを作成
- 立ちデータ: https://github.com/mia-0032/spark-ml-adxl345-from-kinesis/blob/master/data/standing.json
- 座りデータ: https://github.com/mia-0032/spark-ml-adxl345-from-kinesis/blob/master/data/sitting.json
- 作成したモデルにStreamingで受けたデータを流し、現在の状態を判定
なお、Spark 1.5.2だとKinesisからデータを取得できなかったため、1.4.1を使っています。
3.2. 決定木について
簡単に説明すると、決定木はフローチャートのIFを組み合わせて、どういう条件で分岐していけば、目的とする結果にたどり着くかをデータから導く手法です。
Wikipediaの解説( https://ja.wikipedia.org/wiki/%E6%B1%BA%E5%AE%9A%E6%9C%A8 )に記載されている図がわかりやすいです。
3.3. コード
メインの処理は以下の部分です。
各処理はコメントをつけて説明します。
object App {
def main(args: Array[String]): Unit = {
/**
初期化処理
*/
val conf = new SparkConf().setAppName("SensorValueDecisionTree")
val ssc = new StreamingContext(conf, Seconds(2))
val sc = ssc.sparkContext
Logger.getRootLogger.setLevel(Level.WARN)
val standingDataPath = args(0)
val sittingDataPath = args(1)
val streamName = args(2)
/**
事前にサンプリングしたデータを読み込む
*/
val standingData = loadTrainingData(standingDataPath, sc, "standing")
val sittingData = loadTrainingData(sittingDataPath, sc, "sitting")
val data = standingData.union(sittingData)
/**
トレーニングデータとテストデータに分ける
*/
val splits = data.randomSplit(Array(0.8, 0.2))
val (trainingData, testData) = (splits(0), splits(1))
/**
トレーニングデータでモデルを作成
*/
val model = createDecisionTreeModel(trainingData)
/**
テストデータでモデルの当てはまりを確認
*/
testMSE(testData, model)
/**
モデルにストリームでデータを流して状態の出力を行う
*/
val dStream = createDStream(streamName, ssc)
dStream.foreachRDD { rdd =>
model.predict(rdd).foreach { p =>
val s = p match {
case 1.0 => "standing"
case 0.0 => "sitting"
}
println(s)
}
}
ssc.start()
ssc.awaitTermination()
}
def loadTrainingData(filePath: String, sc: SparkContext, state: String): RDD[LabeledPoint] = {
sc.textFile(filePath)
.map { l =>
// JSONをパース
implicit val formats = DefaultFormats
parse(l).extract[Acceleration]
}.map { a => LabeledPoint(
// 目的変数を指定
state match {
case "standing" => 1.0
case "sitting" => 0.0
},
// 説明変数を指定
Vectors.dense(a.X, a.Y, a.Z)
)}
}
def createDecisionTreeModel(trainingData: RDD[LabeledPoint]): DecisionTreeModel = {
// カテゴリ変数がある場合は指定。今回はなし。
val categoricalFeaturesInfo = Map[Int, Int]()
// アルゴリズムの指定
val impurity = "variance"
// ツリーの分岐の最大値を指定
val maxDepth = 5
val maxBins = 32
// 学習してモデルの作成(MLlibはLabeledPointインスタンスに格納されたデータを受け取る)
val model = DecisionTree.trainRegressor(
trainingData, categoricalFeaturesInfo, impurity, maxDepth, maxBins
)
// モデルを描画
println("Learned regression tree model:\n" + model.toDebugString)
model
}
def testMSE(testData: RDD[LabeledPoint], model: DecisionTreeModel): Unit = {
// 誤差の自乗値からモデルの当てはまりをみる
val labelsAndPredictions = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testMSE = labelsAndPredictions.map{ case(v, p) => math.pow(v - p, 2)}.mean()
println("Test Mean Squared Error = " + testMSE)
}
def createDStream(streamName: String, ssc: StreamingContext): DStream[Vector] = {
// Kinesisからストリームでデータを受け取る
KinesisUtils.createStream(
ssc,
"spark-ml-adxl345-from-kinesis",
streamName,
"kinesis.ap-northeast-1.amazonaws.com",
"ap-northeast-1",
InitialPositionInStream.TRIM_HORIZON,
Seconds(2),
StorageLevel.MEMORY_AND_DISK_2
).map(s => new String(s))
.map { l =>
implicit val formats = DefaultFormats
println(l)
parse(l).extract[Acceleration]
}.map{ a =>
Vectors.dense(a.X, a.Y, a.Z)
}
}
}
3.4. 実行結果
学習したモデルは以下のようになります。
Learned regression tree model:
DecisionTreeModel regressor of depth 4 with 9 nodes
If (feature 1 <= -0.2377357929944992)
If (feature 2 <= 0.7265625)
If (feature 1 <= -0.8792451024055481)
Predict: 1.0
Else (feature 1 > -0.8792451024055481)
If (feature 2 <= -0.33203125)
Predict: 1.0
Else (feature 2 > -0.33203125)
Predict: 0.0
Else (feature 2 > 0.7265625)
Predict: 0.0
Else (feature 1 > -0.2377357929944992)
Predict: 0.0
Test Mean Squared Error = 0.0
feature 1がY軸方向、feature 2はZ軸方向の加速度です。
Predictは、1.0のとき立っている、0.0のとき座っている状態に対応しています。
Y軸方向の加速度が-0.2377357929944992以下で、さらにZ軸方向が0.7265625以下で・・・という感じに読んでいきます。
ざっとデータを見る限りでは条件を入れ子にしなくても判定できそうですが、出力されたモデルは非常に階層の深いモデルとなっています。
過学習しているように見えます。学習パラメータを変えれば少し結果は変わるかもしれません。
このモデルにストリームでデータを流し込んだときの出力は以下になります。
{"Y": -0.98113185167312622, "X": -0.041509423404932022, "Z": 0.01171875}
standing
{"Y": -0.97735828161239624, "X": -0.045283008366823196, "Z": 0.015625}
standing
{"Y": -0.97735828161239624, "X": -0.060377344489097595, "Z": 0.00390625}
standing
...
{"Y": -0.052830174565315247, "X": -0.11320751905441284, "Z": 0.9453125}
sitting
{"Y": -0.045283008366823196, "X": -0.11320751905441284, "Z": 0.94140625}
sitting
{"Y": -0.049056593328714371, "X": -0.11320751905441284, "Z": 0.94140625}
sitting
Y軸方向の値を見るだけでも-1付近のときは「立ち」、0付近の時は「座り」になっているので、ちゃんと判定できているのがわかります。
4. まとめ
Sparkはバッチ処理から機械学習、ストリーム処理まで一つのプログラムの中で完結できるので、それぞれの連携がしやすいのが特徴です。
今回作ったプログラムもその特徴をうまく使った構成になっています。
センサーデータはその値だけでは何をしているときのデータなのかわからないことが多く、実際にサービスに応用するにはまだ難しい部分があるかもしれません。
今回は判定するタイミングのセンサーの値だけ取得すればよいので楽でした。
「走っている」「歩いている」あたりになると、時系列でのデータの処理が必要になりそうで難しいかもしれません。
最近はプロトタイプに使える小型ボードが増えています。
中にはJavascriptでコードを書けたり、Linuxの知識をそのまま使うことができたりと、Web開発の知識が活かせるボードもあります。
昔に比べると、物を作りやすくなっているので、ぜひ試してみてください。