2015/12/2のWatson Visual RecognitionのVersion upで、なんと、独自の画像判別モデルを作成できてしまうAPIが公開されていたので、試してみました。具体的には、「スター・ウォーズ/フォースの覚醒」が公開されたということで、Watsonをレーニングして「R2D2」を判別するClassifier(分類器)を作ってみました!
はじめに
すごい時代になったもので、Deep Learning等を活用した最新の顔認識・物体認識サービスが各社より提供され、APIを通して簡単にアプリケーションに組み込むことができるようになってきています。APIとして利用できる代表的なサービスは、下記のようなサービスが代表的なようです。
- IBM Watson Visual Recognition
- IBM Bluemix Alchemy API
- Google Cloud Vision API
- Microsoft Project Oxford Computer Vision API
- ReKognition
- SkyBiometory
画像認識関連のサービスは大きく分けると、顔認識と物体認識の二つに分けられます。前者は文字通り、「写っている人は誰なのか」を判別するサービスで、人物の名前や顔や顔のパーツの位置、年齢、性別、感情等を分析してくれます。
後者の物体認識は、「写真に写っているモノや風景、シーンが何なのか」を判別するサービスで、一般的には、1000とか10000とかの「あらかじめ学習されたカテゴリのどれに該当するか」を教えてくれるサービスで、独自のカテゴリを機械学習させることができるサービスはあまり無いかと思います。
Version upしたIBM Watson Visual Recognitionは、この独自のカテゴリ・判別モデルをAPIを通して機械学習させることができるようになったのです!
「会社のロゴ」や「製品」を判別できるように学習させ、Instagram, Twitterでどんな人が、自社のロゴや製品の写真を投稿しているかを分析しマーケティングに生かすようなこともできるようなるでしょうし、掃除機にカメラを向けるだけで掃除機のManualが表示されるアプリなんかも出てくるかもしれません。
認識精度がどの程度向上するかにもよるとは思いますが、「独自のモノの判別モデルをAPIを通して、容易に機械学習させることができる」ようになることで、画像認識の活用シーンはどんどん広がり、我々の生活を大きく変えていくかもしれません。
ということで、こちらのVisual Recognitionの「Custom Classifiersの作り方」のガイドを参考に、独自のClassifier(分類器)を作って精度を確認してみたというのがこの記事の内容です。
Watsonのトレーニング方法
Custom Classifierwを作成するためには、そのClassifierに対して、Positiveな写真とNegativeな写真をそれぞれ大量に容易します。下記は、Visual RecognitionのDemoサイトからの抜粋ですが、「Golden Retrievers」というClassifierを作成する際には、Positiveな写真としてゴールデンレトリバーの写真を、Negativeな写真としてゴールデンレトリバー以外の写真を容易し、APIにPostします。
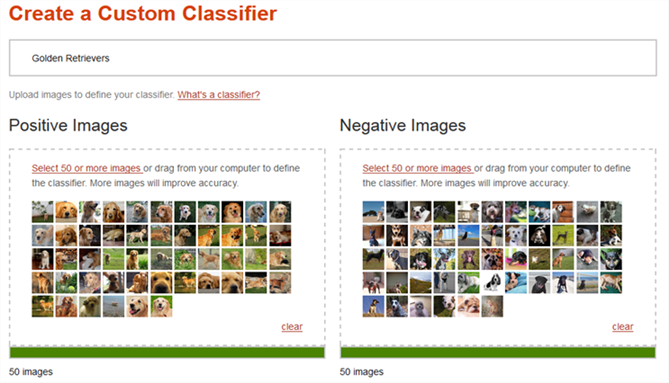
トレーニング画像について
- 画像の形式は、jpg/png/gif
- サイズは200 * 200 以上
- Positive / Negativeはそれぞれ最低でも50枚以上
ガイドには、それぞれ最低でも50枚以上は無いと精度が出ないとの記載がありました。
トレーニング用APIの使用方法
Visual RecognitionのAPIの使用方法はAPI Explorerにまとまっていていて、トレーニングには「POST /v2/classifiers」を使用します。
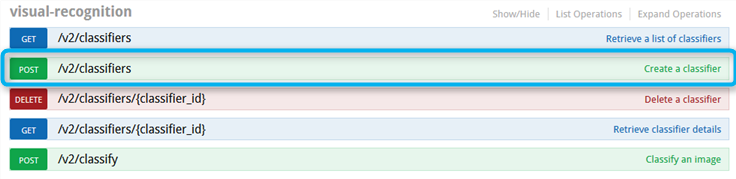
APIの使い方は、cURLであれば下記のように、パラメータをセットしAPIにPOST Requestを発行します。
- username/password : BluemixでVisual Recognitionをインスタンス化する際に割り振られます。
- positive_examples / Negative_examples : 写真をそれぞれzipで固めたもの
- name : Classifierの名前
- version : 2015-12-02 (Versionを指定しないと動かない)
- API URL : https://gateway.watsonplatform.net/visual-recognition-beta/api/v2/classifiers
curl -u "{username}":"{password}" \
-X POST \
-F "positive_examples=@tiger.zip" \
-F "negative_examples=@leopard.zip" \
-F "name=tiger" \
"https://gateway.watsonplatform.net/visual-recognition-beta/api/v2/classifiers?version=2015-12-02"
トレーニング開始!
さて、トレーニング方法がわかったところで、いよいよビシバシWatsonをトレーニングしていきます。今回はWatsonがR2D2を判別できるようにトレーニングしていくわけですが、問題はNegative画像をどのように準備するかと言う点です。Positive画像はR2D2をひたすら集めればよいですが、Negative画像はロボット全般を集めればよいのか、それとも、特定の例えばトランスフォーマーの画像を集めればよいのか。
Classifierは、R2D2か否かを判断するものだと思うので、とりあえずR2D2以外の画像ならば何でも良いように思います。Negative画像の選び方がどのようにClassifierの判別精度に寄与するのかは今後もっと調査していきたいと思います。が、今回はお試しということで、「C3PO」の画像をNegativeとして与えてみることにしました。

画像の収集
画像の収集は、Google画像検索を利用して、キーワードに関連する画像を指定の枚数だけ一括でダウンロードするツール、「Image Spider」を使い、集めました。
画像サイズが大きいとトレーニングに時間がかかるため、画像の長辺が800ピクセルになるように、「BULK Resize」というWeb Serviceで一括サイズ変換しました。
トレーニング実施
画像の準備が完了したので、いよいよトレーニング実施です。コマンドプロンプトでcURLにてAPIにリクエストを発行します。
curl -u "439337e6-948f-4588-8fda-e3b9b*******":"QC7hUT3ZH***"
-X POST
-F "positive_examples=@R2D2.zip"
-F "negative_examples=@c3po.zip"
-F "name=R2D2"
"https://gateway.watsonplatform.net/visual-recognition-beta/api/v2/classifiers?version=2015-12-02"
5分程度たったころに、下記のようにJSON形式で、classifier_idが割り振られ、classifierの作成が完了します。
{
"name" : "R2D2",
"classifier_id" : "R2D2_1257443589",
"created" : "2015-12-18T06:03:45.000Z",
"owner" : "595e84cb-e686-4939-99bf-1d59ec3e4e81-us-south"
}
トレーニング成果の確認
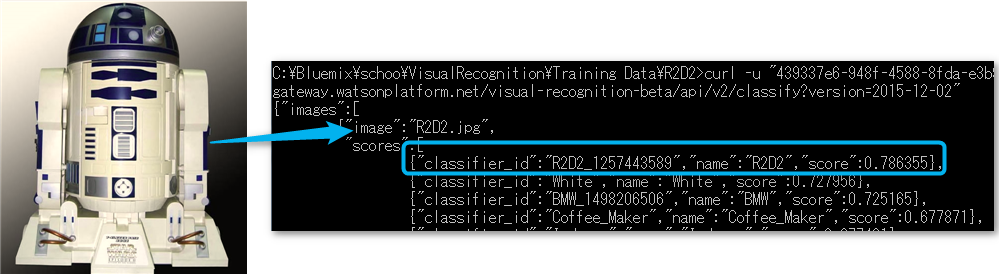
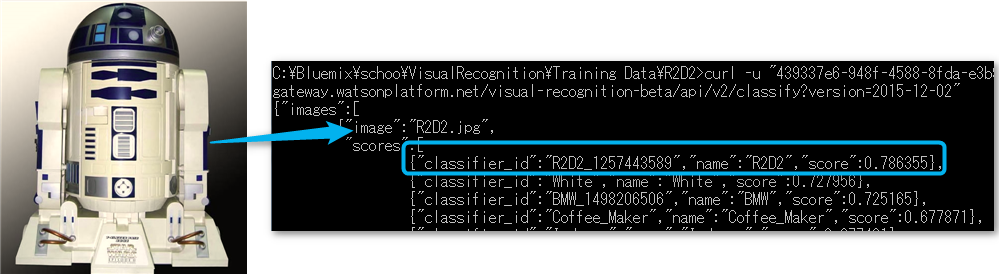
トレーニング成果を確認するために、トレーニングでは使用しなかったR2D2の画像を用意し、下記のように、画像認識のAPIを利用して画像認識をさせてみます。期待値は、もちろん、「R2D2」の確率が高いという結果が得られることです。
curl -u "439337e6-948f-4588-8fda-e3b9b32fa282":"QC7hUT3ZHhyV" -X POST -F "images_file=@R2D2.jpg" "https://
gateway.watsonplatform.net/visual-recognition-beta/api/v2/classify?version=2015-12-02"
結果は、ということで、冒頭で添付した画像のように、R2D2以外にも色々なモノと認識されてはいますが、R2D2の確率が一番高いと言う結果が得られました!
ということで、見事、R2D2を判別するClassifierを作ることができました!!
{"images":[
{"image":"R2D2.jpg",
"scores":[
{"classifier_id":"R2D2_1257443589","name":"R2D2","score":0.786355},
{"classifier_id":"White","name":"White","score":0.727956},
{"classifier_id":"BMW_1498206506","name":"BMW","score":0.725165},
{"classifier_id":"Coffee_Maker","name":"Coffee_Maker","score":0.677871},
{"classifier_id":"Indoors","name":"Indoors","score":0.677431},
{"classifier_id":"Appliance","name":"Appliance","score":0.674548},
・・・・
・・・・
こうなってくると、色々試したくなります。人を識別することはできるのか?会社のロゴや製品は?追って、色々と試して追記していきたいと思います。
まとめ
ということで、ひっそりとトレーニング可能になっていたVisual Recognitionですが、トレーニング方法も単純明快で、画像の枚数やサイズを適切に抑えれば、トレーニング時間もそこまで長くはかからず、結果かなりお手軽にClassifierを作れる印象です。
R2D2以外にも、いくつかのClassifierを作成し確認してみましたが、First Impressionとしては適当にやってもそこそこの精度が得られるように感じました。独自のClassifierを使えるVisual Recognition、このAPIを使ってどんなアプリが作られるのか楽しみです。