この記事は Go Advent Calendar 2016 最終日の記事になります。参加頂いた皆さんお疲れさまでした。
今年も昨年に引き続き、25人以上の方が「何か書きたい」と名乗り出て頂き、go、go2、go3 の3本(2年連続)、計75エントリが揃う事になりそうです。Go 言語の人気が高まってきているのが良くわかるアドベントカレンダーでした。
あらすじ
普段あまり表だった所には姿を現さないのですが、今年は builderscon 2016 に登壇させて頂きました。

とても新鮮な体験で、味わった事のない緊張の中、いろいろな反響を貰いました。いい体験が出来たと思います。ありがとうございました。登壇し終えて数時間はなんだか緊張のほぐれた変な感じを味わっていました。懇親会の時あたりでようやく皆さんとお話する事ができて Vimmer の皆さんと Vim 談義をしてきました。
その懇親会で香り屋さんに紹介頂いたKii株式会社の方とお話させて頂き、builderscon2016 で配布されたパンフレットがKiiさんのデザインと教えて頂きました。

実はこのパンフレット、正規表現を使ったクロスワードパズルになってるんです。builderscon2016 が終わり自宅に帰ったあと、この正規表現クロスワードをやってみたんですが、なかなか頭を使わさせられるクロスワードで十分楽しめました。
この正規表現クロスワードパズルの開発秘話をKiiさんが記事にされておられます。
このクロスワードパズルを解いた僕は誇らしげに Twitter にポストしてしまったんです。

が...
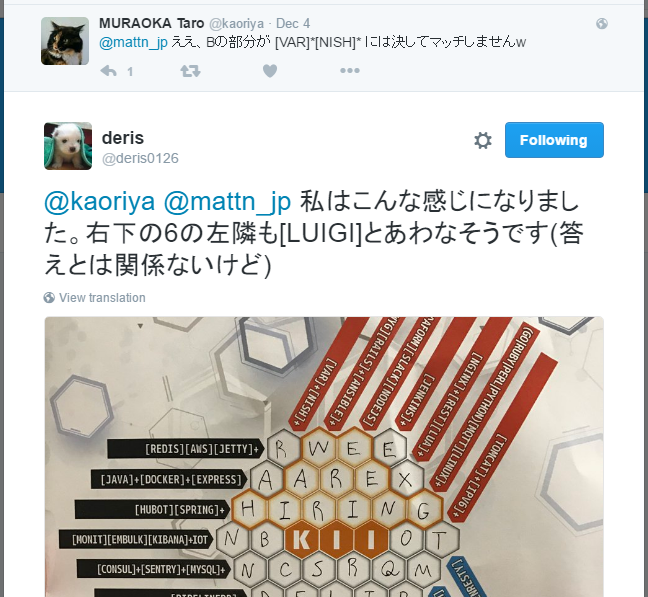
まっ間違ってた!!!!!!1
自らの詰めの甘さに悔やんでも悔やみきれませんでした。

なぜ間違った
なぜ間違ったのかを説明する前にまずこの正規表現クロスワードのルールを説明したいと思います。
三方向に延びる帯には正規表現パターンが書かれています。例えば左側の上から2段目は
[JAVA]+[DOCKER]+[EXPRESS]
この正規表現を使って5文字を埋めます。正規表現の文字クラスなので J, A, V の何れかで1文字以上、続いて D, O, C, K, E, R の何れかで1文字以上、最後に E, X, P, R, S の何れかで1文字となります。各 + で何文字使うかは他の列の正規表現パターンでマッチしうる物を選ばなければなりません。

僕が間違った WE ARE BIREING の B は、実は最後に残ったピースでした。横列 [HUBOT][SPRING]+ で最初の文字、下列 [CONCOUR][SE][CI][BASH]+ の最後の文字、この時点で僕は「もう解ける。B しかないし。ツイッターにポストするぞ!」と心に決めて B しか無いと思い込んでしまったのです。しかし縦列 [VAR]+[NISH]+ を見るとパターンに当てはまりません。
こんなのは人間の解く問題じゃない(横暴)
ぼっ... 僕が悪いんじゃない!こんなのは機械が解くべきなんだ!
勝手にふつふつと沸かせた思いを抱きながらこの記事を書く数日前までこんな事を考えていました。
これ、プログラムで解いてやる
プログラムでこの問題を解くには
この問題をプログラムで解く為にはまず2つの方法がありました。
- ブルートフォース的に文字を入れ込み都度、全方向から正規表現パターンでマッチさせるという小学生でも思いつきそうな雑な方式
- 正規表現パターンを解釈し、あり得る文字の候補を作った後で他のパターンで検証しつつ消していくという真面目な方式
後者をやるには正規表現パーサを自作する必要があり、「めんどくさいな」という思いから前者のブルートフォース案を選びました。
間違った決断
まずは正規表現パターンでマッチさせる処理を書き始めました。しかし途中で気付きます。
下段中央に着目して下さい。
\d([VIM]([MARKDOWN]))\1[EMACS]\2
こっこれは...。
そうです。パターン内の後方参照です。置き換え文字列内での後方参照はよくある話ですが、この正規表現パターンを解釈できる正規表現エンジンは限られます。Perl や Ruby、ちなみに Vim も扱えます(Vim 関係ないだろ)。そしてこのパターン内後方参照が golang では使えないと気付いてしまいました。
まさかこれを Vim script で作るってのは無理があるし、そもそももう Vim Advent Calendar の担当終わったよね。このネタ詰んだ。

そう思いました。
正規表現を事前に弄るか
こんな風にも考えましたが実は簡単には置き換えられないのです。例えば上記の
\d([VIM]([MARKDOWN]))\1[EMACS]\2
は、単に
\d[VIM][MARKDOWN][VIM][MARKDOWN][EMACS][MARKDOWN]
に置き換えられる訳ではなく最初のグループでマッチした結果で初めて \1 が決定します。つまり別のマッチを行ってはいけないのです。
さらには登場し得る文字は AからZおよび0から9、計38文字。正規表現パターンが任意だと仮定してインクリメンタルサーチ無しに全てのマスをあてはめるには 38^37 通り、試す正規表現は3方位、コンピュータリソースがリッチになった近代だとしても、とても今年中に解けそうにもありません。

しぶしぶ正規表現をパースする処理を書き始めた
やるしかないと決めたからには golang で進めるしかありません。仕方なくパーサを書き始めました。問題中の全ての正規表現パターンで出現するアトムトークンは以下の通り。
- A から Z、もしくは 0 から 9
- 文字クラス
[] - グループ
() - 量指定子
+ - 後方参照
\1,\2
まずは問題となる正規表現をファイルから読み込ませる事にしました。ファイルの内容は以下の通り。
[REDIS][AWS][JETTY]+ 11,12,13,14
[JAVA]+[DOCKER]+[EXPRESS] 21,22,23,24,25
[HUBOT][SPRING]+ 31,32,33,36,35,36
[MONIT][EMBULK][KIBANA]+IOT 41,42,43,44,45,46,47
[CONSUL]+[SENTRY]+[MYSQL]+ 51,52,53,54,55,56
[PIPELINEDB]+ 61,62,63,64,65
[HEROKU]+[ES6] 71,72,73,74
[VAR]+[NISH]+ 11,21,31,41
[WYSIWYG][RAILS]+[ANSIBLE]+ 12,22,32,42,51
[TE]RR[^AFORM][SLACK][NODEJS] 13,23,33,43,52,61
[JENKINS]+ 14,24,34,44,53,62,71
[NGINX]+[REST][LUA]+ 25,35,45,54,63,72
(GO|RUBY|PERL|PYTHON)[MQTT][LINUX]+ 36,46,55,64,73
[TOMCAT]+[IPV6]+ 47,56,65,74
[SDK]+([FLUENTD])\1 71,61,51,41
[CONCOUR][SE][CI][BASH]+ 72,62,52,42,31
[LUIGI]+[JAVASCRIPT][KAFKA][AGILE]+ 73,63,53,43,32,21
\d([VIM]([MARKDOWN]))\1[EMACS]\2 74,64,54,34,33,22,11
[PUPPET][QA](.)\1[SERVERSPEC][W3C] 65,55,45,34,23,12
[MONGODB]+[NOMAD][ELASTIC][SEARCH] 56,46,35,24,13
[GITHUB]+[ZABBIX][OPENRESTY] 47,36,25,14
1行の内容は正規表現パターンと番号の列がタブで区切られます。マスを番号で表現し、正規表現でマッチすべきマスの番号をカンマで列挙します。番号体系は2桁の数字で表現し、1桁目は縦方向の行1~7、2桁目は横方向の列1~7です。

正規表現でマッチさせるためには、上記のトークンを解釈して出現しうる文字をマスに当てはめる事になります。
Go言語らしいパーサの書き方
Go に限らずパーサという物を書いた事がある方なら想像付くと思いますが、パーサを書くにはまずはノードを定義します。ノードはパースするデータを分解し、決められた文脈(トークン)を一まとめにしたかたまりに束ねます。
その際、このかたまりの表現方法が各言語によって異なってきます。例えばC言語であれば union を使って表現します。
struct _NODE {
NODE_TYPE t;
int r;
union {
long i;
double d;
char* s;
} v;
int nchild;
struct _NODE **children;
};
この NODE が木構造になった物を AST と呼び、木のてっぺんから分岐しながら渡り歩いて行きます(AST Walker と呼びます)。その際上記のC言語の方式では以下の様に若干煩わしい処理を書かないといけません。
NODE node = (NODE*)arg;
switch (node->t) {
case NODE_NUMBER:
printf("このノードは整数だよ: %d\n", node->v.i);
break;
case NODE_DOUBLE:
printf("このノードは浮動小数だよ: %f\n", node->v.d);
break;
case NODE_STRING:
printf("このノードは文字列だよ: %s\n", node->v.s);
break;
}
この様に、分岐した先でも node が何なのかを書き手が把握しないといけません。しかし Go の switch 構文を使うと非常に綺麗に書けるのです。
type node interface {
expr()
}
type String string
func (s String) expr() {}
type Number int64
func (n Number) expr() {}
type Float float64
func (f Float) expr() {}
switch v := node.(type) {
case String:
// ここで見える v は String になっている
fmt.Println("文字列足すよ", "「" + v + "」") // 文字列結合できる
case Number:
// ここで見える v は Number になっている
fmt.Println("整数に3足すよ", v + 3) // 整数として足し算できる
case Float:
// ここで見える v は Float になっている
fmt.Println("浮動小数を2で割るよ", v / 2) // 浮動小数として割り算できる
}
case の中では既に型に成り代わった値 v が渡される為、書き手は意識する事無く処理を実装でき、バグが混入する事も少ないのです。
ここで何もしないメソッド expr() を定義していますが、実は呼び出しません。ではなぜ定義するか、それはインタフェースで型を拘束したいからです。Go は Duck Typing で型交換される言語です。逆に言うと、あるグループに属した共通インタフェースを作るには何かしらのシグネチャが必要なのです。expr() というメソッドを定義すればその瞬間に node インタフェースを満たす事になるという仕組みです。まぁ、言ってしまえば「間違った型の値を node インタフェース放りこんでしまわない為」のテクニックです。
今回のケースであれば、以下の定義になりました。
type node interface {
expr()
}
type marker string
func (x marker) expr() {}
type quantum string
func (x quantum) expr() {}
type backref string
func (x backref) expr() {}
type nodelist []node
func (x nodelist) expr() {}
type runelist []rune
func (x runelist) expr() {}
そしてパーサは以下の様になりました。
func parseAndWalk(pat string, nest int) ([]node, error) {
rs := []rune(pat)
var cc []rune
var ret []node
for i := 0; i < len(rs); i++ {
switch rs[i] {
case '(':
i++
ff := ""
ret = append(ret, marker(fmt.Sprintf("S%d", nest+1)))
var cd []node
for ; i < len(rs) && rs[i] != ')'; i++ {
if rs[i] == '|' {
r, err := parseAndWalk(ff, nest+1)
if err != nil {
return nil, err
}
cd = append(cd, nodelist(r))
ff = ""
continue
}
ff += string(rs[i])
}
r, err := parseAndWalk(ff, nest+1)
if err != nil {
return nil, err
}
cd = append(cd, nodelist(r))
ret = append(ret, nodelist(cd))
ret = append(ret, marker(fmt.Sprintf("E%d", nest+1)))
case '\\':
i++
switch rs[i] {
case 'd':
ret = append(ret, number)
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
ret = append(ret, backref("P"+string(rs[i])))
default:
return nil, errors.New("invalid token: " + string(rs[i-1:]))
}
case '+':
ret = append(ret, quantum("+"))
case '[':
cc = nil
i++
if rs[i] == '^' {
i++
ff := ""
for ; i < len(rs) && rs[i] != ']'; i++ {
ff += string(rs[i])
}
for _, a := range alnum {
if strings.IndexRune(ff, a) == -1 {
cc = append(cc, a)
}
}
} else {
for ; i < len(rs) && rs[i] != ']'; i++ {
cfound := false
for _, cf := range cc {
if cf == rs[i] {
cfound = true
break
}
}
if !cfound {
cc = append(cc, rs[i])
}
}
}
ret = append(ret, runelist(cc))
case '.':
ret = append(ret, alnum)
default:
ret = append(ret, runelist([]rune{rs[i]}))
}
}
return ret, nil
}
func parse(pat string) ([]node, error) {
return parseAndWalk(pat, 0)
}
今回はこの問題を解くことが目的だったので間違った正規表現のチェックなどは行っていません。
文字クラス [] は発生し得る文字(rune)の slice を、グループ () は後方参照可能な様に start/end で範囲を格納、あとはそれぞれ switch/case で型が判別できる形にしてパースします。
実行はマッチじゃない
正規表現の簡易パーサを書きましたが、このパーサはマッチする為の物ではありません。なぜならこのクロスワードパズルの問題は「発生し得る文字を調べるため」の物だからです。

よってマッチ処理ではなく候補の生成処理を書きます。
func generate(prefix string, ci int, cs []node, bi int, br [10]group, max int, cb func(s string)) {
if len(prefix) > max {
return
}
if len(prefix) == max {
for i := ci; i < len(cs); i++ {
s, ok := cs[i].(marker)
if !ok {
return
}
if !strings.HasPrefix(s.String(), "E") {
return
}
}
cb(prefix)
return
}
for i := ci; i < len(cs); i++ {
c := cs[i]
switch t := c.(type) {
case runelist:
for _, r := range t {
generate(prefix+string(r), ci+1, cs, bi, br, max, cb)
}
return
case quantum:
if ci > 0 {
for j := 0; j < max-len(prefix); j++ {
var qp []node
for jj := 0; jj <= j; jj++ {
qp = append(qp, cs[i-1])
}
qp = append(qp, cs[i+1:]...)
generate(prefix, 0, qp, bi, br, max, cb)
}
return
}
case backref:
if ci > 0 && t[0] == 'P' {
mp, _ := strconv.Atoi(string(t)[1:])
part := prefix[br[mp].start:br[mp].end]
prefix += part
generate(prefix, ci+1, cs, bi, br, max, cb)
continue
}
case marker:
if t[0] == 'S' {
mp, _ := strconv.Atoi(string(t)[1:])
br[mp].start = len(prefix)
ci++
continue
}
if ci > 0 && t[0] == 'E' {
mp, _ := strconv.Atoi(string(t)[1:])
br[mp].end = len(prefix)
ci++
continue
}
default:
for _, ii := range c.(nodelist) {
iv := ii.(nodelist)
var cv []node
for _, iiv := range iv {
cv = append(cv, iiv)
}
cv = append(cv, cs[ci+1:]...)
generate(prefix, 0, cv, bi, br, max, cb)
}
}
}
}
prefix が出来上がった文字、ci が今見ているトークンのインデックスです。生成した文字列の長さが想定している文字列長で全て処理仕切ったなら、それが出現し得る候補になります。この関数を呼び出すと、例えばパターン [AB][CD] から以下の候補が生成できます。
AC
AD
BC
BD
後方参照がある場合も大丈夫 ([AB])[CD]\1
ACA
ADA
BCB
BDB
結果を蓄積するとメモリがパンクしかねない為、都度コールバックで呼び出します。
generate("", 0, q.token, 0, br, len(q.pos), func(s string) {
for i, c := range s {
pos := q.pos[i]
// ignore KII on center
if pos == 43 && c != 'K' {
continue
}
if pos == 44 && c != 'I' {
continue
}
if pos == 45 && c != 'I' {
continue
}
if d[pos] == nil {
d[pos] = make(map[rune]bool)
}
d[pos][c] = true
}
qs[qi].cand = append(qs[qi].cand, s)
})
ここでマス番号 43, 44, 45 が固定文字かを見ています。パンフレットを見て頂くと真ん中の部分に K, I, I が初めから文字が割り当たっているのが分かります。これ以外として現れた候補をキャンセルしている処理になります。これだけでも随分とメモリをケチれます。
候補からNGを取り除く
この段階ではまだ各行にてあり得る候補が出来上がっただけで、掛け合わせるとNGになる候補も混ざっています。

3方向から出来上がった候補と掛け合わせます。同じマスには同じ文字が入るはずなので異なってしまった候補を取り除いていきます。
// マスに割り当てられた文字候補を試していく
for k, _ := range d {
// 列で回す
for _, q := range qs {
pi := -1
pq := -1
// 列の中に対象のマスがあるか探す
for i, pos := range q.pos {
if pos == k {
pi = i
pq = pos
break
}
}
if pq == -1 {
continue
}
// 同じマスを共有しているので候補を試す
for qi, cand := range q.cand {
if cand == "" {
continue
}
// 文字候補にあるか確認する
if _, ok := d[pq][rune(cand[pi])]; !ok {
// 無かったので候補を潰す
q.cand[qi] = ""
}
}
}
}
しかしここで強敵が現れます。
強敵あらわる

懇親会の時、kaoriya さんと Kiiさんが「.* とかなんでもありだからねー」と仰っていたのがここでようやく分かりました。本来ならば上記の消し込みで1つだけ候補が残るはずだったのです。.* により複数の候補が残ってしまいます。しかし、3方向から複数候補でマッチし得るのならば、それだけスコアが高い事になります。そこでランキング付けしました。
rank := make(map[int]map[rune]int)
for _, s := range qs {
for i, pos := range s.pos {
for _, cand := range s.cand {
if cand == "" {
continue
}
if rank[pos] == nil {
rank[pos] = make(map[rune]int)
}
// 見つけた候補をランクアップ
rank[pos][rune(cand[i])]++
}
}
}
gs := make(map[int]string)
for pos, v := range rank {
lr := 0
lc := rune(0)
// ランキングが一番高い物を探す
for rk, rv := range v {
if rv > lr {
lr = rv
lc = rk
}
}
// 最終候補が決定
gs[pos] = string(lc)
}
動かす
出来上がった文字の集まりから、パンフレットの橙色部分にある穴あきを集めて文字列を作ります。
s := gs[12] + gs[13] + " " +
gs[22] + gs[23] + gs[24] + " " +
gs[31] + gs[32] + gs[33] + gs[34] + gs[35] + gs[36] + " " +
gs[43] + gs[44] + gs[45]
fmt.Println(s)
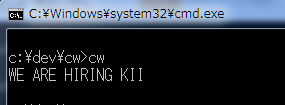
やったー!(地味)
しかし、何なのこの上手くいったのに負けた気がするこの感じは...

おわりに
実装し終えて感じたのは「最初から僕が、注意深く最後のマスに気を付けていれば、こんな事にはならなかった」という事でした。
また builderscon2016 から帰宅してこの正規表現クロスワードパズルを解くのに掛かったのは20分程度でしたが(間違ったけどな)、このコードを書くのに3時間ほど掛かってしまいました。実行結果こそ数百ミリ秒で終わる計算ですが、実装には3時間も掛けてしまった訳で
人間の脳ってやっぱりすごいな
と感じずにはいられませんでした(間違ったけどな)。今度からちゃんとチェックしてからツイートしようと思いました。
そして最後に言いたい。
Kii株式会社では優秀なエンジニアを募集しています!詳しくは採用のページをご覧ください!
らしいです。
※筆者は Kii 株式会社の者ではありません
ソースは GitHub に置いておきます。