2017-01-21 第34回 PostgreSQL 勉強会
自己紹介
- 増田和弘 Twitter: @masudakz
- 所属:株式会社ジャストシステム
- 中途入社で一太郎Ver.4開発中(1987)から
- 当時の主力機 NEC PC-9801VX
5インチFDD、80286/8MHz+V30/10MHzを搭載。VX4(SASI HDD、容量20MB)
PostgreSQL歴
- 2000年代初めのエンタープライズ製品での利用から接触
- 実装・運用経験は2013年から


- PostgresSQL 9.2〜
- CentOS on AWS
本日の内容紹介
- ユーザ視点の事例発表
株式会社ジャストシステムのWebサービスはスマイルゼミをはじめとしてほとんどがPostgreSQLを使っています。 Webサービスのヘルスチェックにpg_stats_reporterを利用しているので、その活用状況や社内でのノウハウ共有状況について話します。
pg_stats_reporterについて、参加者同士でノウハウ交換したい。
たとえばこんなサービス
pg_stats_reporter以前
Apache Log, Postgres Log を grep して Slow API, Slow Queryを探してた
例:100msec から 10secまで
grep -E "期間: [0-9]{3,5}\.[0-9]"
[4182]: [429-1]: [53ed53fc.1056]: [u=xxxxxxxx]: [v=4/24062]: [x=0]:
[r=10.243.232.16(35970)]: LOG: 期間: 171.143 ミリ秒
サービスが無事テイクオフすると
- 日銭が入ってくる
- 継続的開発が可能
- 追加機能要求・変更要求
- 増え続けるAPIとSQL
DBAはやってられない
- 毎月(毎週)なんかしら新機能がデプロイされる
- コードレビューも性能テストも受けていないSQLが次々運用環境へ
- 障害対応が後手後手
- 原因究明・対策に時間がかかる
PGFouine?
2014にPostgreSQLスケールアウト問題で、Instagram の tech blog読んでたら
Postgres Query Log の分析には PGFouineがよかったぞ
でも、blogが古くて情報として古そう
中国地方DB勉強会in岡山2014
「第4回 中国地方DB勉強会 in 岡山 #ChugokuDB」にセキココしました! http://t.co/JcOn2MCbU8 #sekicoco
— そーだい@初代ALF (@soudai1025) 2014年7月13日
pg_statsinfoが紹介された
とりあえずpg_statsinfoのレポート見とけ #PostgreSQL #ChugokuDB
— さく%モートレ(エアなし)仮運用中 (@S_a_k_U) 2014年7月13日
喜田さんin岡山2014のまとめ
- DBチューニング
- SQLチューニング
- pg_statsinfoの紹介
- PostgreSQL 9.4 betaの話
pg_stats_reporter
- PGFouineは開発止まってた
- pgBadgerはサービスのログの量が膨大すぎて、うまくいかなかった
「pg_statsinfoがいいらしいよ」
当社インフラチームに相談
→ pg_stats_reporterもいれましょう ![]()
現代的だ 
- Create new report
- 1/15 11:00 - 1/15 15:00
※勉強会終了時点で閉じます
御利益1:運用作業時間減少
Web可視化
- server に login しなくていいんだ
- 監査観点でもloginは避けたい
- log grep しなくていいんだ
- 作業時間減って監視密度は上がる
御利益2:性能障害検出機会
- ステージングで普通に使うだけでいいんだ
- UnitTestくらいはみんなしてくれるけど
- 性能テストまでは手が回ってない
導入後は
- ステージングで1回でも通せばSlow Queryが可視化される
御利益3:デプロイ直後の検出機会
- ステージングで見過ごしても…
- 運用デプロイしてアクセスピークが来る前にヤバイSQLが可視化される
- ヤバイと思ったらピーク前にロールバック
御利益4:予防対策
- 予防対策がうてる
- 今は性能余裕がまだあるけど、会員増えるとヤバいぞ
- 今は小さな負荷だけど seq. scan だからデータ成長とともにヤバくなるぞ
例:応答時間 5sec 〜 17sec APIがチラチラ
- Long Transactions
- SQL特定
- Heavily Accessed Tables
- seq_tup_read でインデックスの利いてないTABLE
- SQLチューニングへ
改善結果

まとめ1
- 中国地方DB勉強会は控えめにいって最高
- pg_stats_reporter入れたらサービスの性能リスク減るよ
- 楽に減るよ
- 作った人、イベントした人、講演した人、ありがとうございます
次のお題
みんなで幸せになろうよ
社内根回し
- ステージングの事前検出
- デプロイ後の障害対策
- 「pg_stats_reporterによると」と枕詞をつけて、Redmine/全社サービス障害分析会 に分析見解書いては対策してた
- インフラチームの目にも入っていた
「活用できてるやん」 - pg_stats_reporter 他でも使おう
技術内閣
- ファ? DB大臣? なにそれ 2016-01-27
- 事業部越えて直接貢献(設計品質・効率化提案)
- スキルアップ施策、情報共有、技術戦略
事業が多様になると、事業ごとに使う技術もバラバラになり、組織は縦割りになっていきます。そのような環境の中で、どう全社的に横連携するか。

横連携成果の一発目
2016-03
- 某サービスの SQL statement のログが大きくなりすぎ
- リリース直後はよかったがDAUが上がってきて破綻寸前
- サーバ大臣+インフラ大臣+DB大臣
- 設定のはまりどころ、実績ありの設定値を共有
snapshot_interval
pg_statsinfo.snapshot_interval = 30min
- Report にするには snapshot が 2つは必要
- 本導入前の調査で、いろいろ試すには30minはちと長い。
- デプロイ直後の状況も早く反映したい。
pg_statsinfo.snapshot_interval = 5min
Query Activity - Statements が空
- 複数サーバで繰り返し失敗した。はまりどころ?
- 導入時に下記を忘れるとSlow Query Reportだけが出ない
CREATE EXTENSION pg_stat_statements;
ログ出し過ぎ
- 負荷テストで毎分200MB超増大した
- 1GB/4分 = 15GB/h = 360GB/day!
log_min_duration_statement = 10
log_connections = off
log_disconnections = off
log_duration = off
log_statement = 'none'
10msec以下のを切り捨てた。
ログを切り捨てて負荷正常化
stat_statements_exclude_users
- postgres user が statsrepo schema を操作する分を出力抑制
pg_statsinfo.stat_statements_exclude_users = ‘postgres'
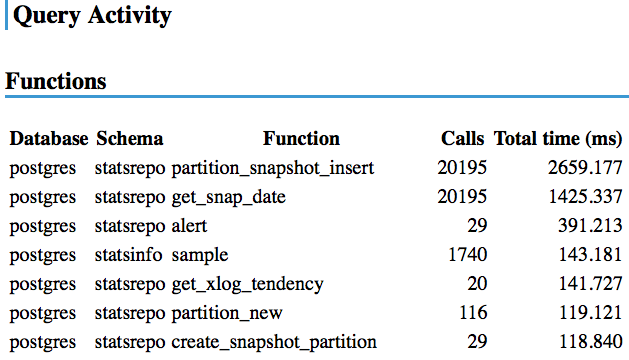
stat_statements_max
- Query Activity - Statementsにはデフォールトで30個までしか出ない
- 期間中のcalls上位30件だけ表示
- 低頻度のSlowQueryがあると表示されない!
- tup_seq_scan とかには出てくる
-
2016 Advent Calendar 12/23のネタにしました
pg_statsinfo.stat_statements_max = 1000
まとめ2:オレオレ設定ポイント
log_min_duration_statement = 10
log_statement = 'none'
pg_statsinfo.snapshot_interval = 5min
pg_statsinfo.stat_statements_exclude_users = ‘postgres'
pg_statsinfo.stat_statements_max = 1000
CREATE EXTENSION pg_stat_statements;
Excuse
オレオレ設定=サービス・アプリの特性次第
当社サービスの基本特性
- 有料会員制サービス
- 時間帯・暦日で負荷予想しやすい
- × 長時間つかってもらいたい
- ○ なるべく速く用が済む
- 負荷変動が大きいのは、不特定多数向けのLPくらい
- なんでもかんでも集める戦略はない。CV率重視
次のお題
みんなでもっと幸せになろうよ
DB大臣SOS 
2016-05
- 「このサービスの性能問題なんとかなりませんか」
- 「30分だけでも相談時間を」
- 予備知識なしのDB大臣に助言してくれというムリゲー
読める、読めるぞ 
- ムリゲーじゃなかった
- サーバ大臣とサービスDBAがpg_stats_reporter画面を見せながらブリーフィング
- pg_stats_reporterあると、問題点がどこか探しやすい
- サービスDBAへの質問も最小限で、30分で次の一手の方向決めてお持ち帰り
- 実装コード1行も読まずに
DB大臣の横連携施策 
- DBA集めてpg_stats_reporter見よう
- DB読影会

DB読影会のススメ
- みんな事前準備不要
- ふだん監視している画面をさらすだけ
- pg_stats_reporter
- munin / zabbix
- 問題発生時のsnapshotがあるとよい
- 技能向上の即効性
- そこを見るのか
- これヤバかった?
DB読影会の様子1
- 開いたときのデフォールトのレポート期間が使いにくい
- 深夜の分析・保存用pg_dump が入っていて、負荷を跳ね上げてるので、実需ピークがわからない
- Create New Reportでスコープを限定する
- スマゼミだと前日12:00-24:00とか
DB読影会の様子2
- え、なにこれ? 5/9 に2本の負荷スパイクがあるじゃないの
- スパイクのところだけに snap_begin, snap_end を狭めて犯人捜し
- "Long Transactions" で犯人みつかった
- client address から事務局ツールの中に犯人
- "Heavily Accessed Tables" も某TABLEの seq_tup_read がダントツ。58万行の seq.scan を10万回。
- INDEX未設置だったので、追加する
DB読影会の様子3
- "Heavily Updated Tables" に database:postgres, schema:statsrepo のtableが上位に複数出てくる。pg_stats_report はそれなりの記録負荷がかかるもの。
- このサービスは postgres ユーザを使っていてStatementから
stat_statements_exclude_usersで除外できない!
DB読影会の様子3b
- "Heavily Accessed Tables" で一番注目しているのは"seq_tup_read":シーケンシャルスキャンによって読みとられた行数
- tup_per_seq が大きくてもアドホックなSQLによる単発なら性能問題にはならない。セキュリティ案件にはなるかも。
- ※2016-12には低頻度SQLが性能障害を引き起こすようになった
DB読影会の様子4
- "Statements"
- 最初に見るのは "total time"降順
- 次に time/call 降順でスロークエリ。今の某サービスは top でも 20msec。
DB読影会の様子5
- "Statements"
- 認可のための契約状態確認のSQL数がダントツで、total time でも上位に出てきた。認可に今のままのSQLを使うのはそろそろ限界。KVSにするか?
DB読影会の様子6
- 1週間のレンジで見ると、やはり 0:00, 4:00 のpg_dump のスパイクがじゃま
- 実需の長期傾向がスパイクの影に隠れて読めなくなってしまう
- 5/16 だけスパイクが3本?
- 09:05 ですね。誰か何かやった?
- メンテ前の手順としてのpg_dumpでした
DB読影会の様子7
- Heavily Accessed Tables
- Top 2 が user_info と member の TABLE
- メンテ・分析専用カラムだったはずの update_at をビジネスロジックがSQLに取り込んでしまった。INDEX追加するよりは、ロジック修正する方向。
- "Statetemts"の call の回数と seq_scan 回数がほぼ一致しているので、要修正のSQLはこの2つ
DB読影会の様子8
- レンジを 5/17 14:00-16:00 にすると別の現象が見える
- pg_dump以外の負荷の山ができているところ
- Disk Read のパイチャートが job TABLE 99%
- seq_tup_read も user_info/memberを上回る job の圧勝
- ”Statements” の Top 2 も job の SELECT
- たぶん job TABLE に何かINDEXが不足している
DB読影会の様子9
- バックヤードアカウントテーブルを繰り返し全件scanしている!
- 内部犯行のブルートフォースアタック?
- 誰?
- 正規管理者の通常管理業務でした。
- 実装の作りが悪くて導出テーブル使わずに相関サブクエリーで計算量膨らませていた
- TABLEが小さいのでINDEXつけていなかった
DB読影会の様子10
- 交差テーブル作ってindexもあるのに遅いんですよ
- Heavily Accessed Tables みると seq. scanになってる
- Information - SchemaInformation - Index
- TABLE item_group_item_image
- 主キー (image_id, group_id)
- group_idで検索してるじゃないですか。単キーindexも必要。
- group, item というカラム名からすると、主キーとしての順序は、(group, item) になるのが普通の感覚です。普通じゃない設計や前提なら、どこかに意図を書いておくか、名前を考え直したほうがよかったと思います。
- 主キー定義を間違って作った可能性も微レ存
- 実装途中で交差テーブルの列順入れ替えたときに、主キー作り直しを忘れてました!
オレオレ分析優先順位
別サービスからSOSで、pg_stats_reporterを診た。読影会でも、Qiitaでも共有したけど、Long Transactions - Statements - Heavily Accessed Tables - Indexの順でみてけば、大概わかるよ。
— masuda kaz (@masudakz) 2016年9月22日
pg_stats_reporterのLong Transactions/Statements でクエリ特定して、H.A.TでSeq.ScanになってるTABLE特定して、結合条件列がIndexになかったら、Gotcha! 簡単だよー
— masuda kaz (@masudakz) 2016年9月22日
困りごと1:RDSでどうしよう
- RDS for PostgreSQLの正式リリース後は新規サービスはRDSへ
- 既存サービスもRDS移行検討・実施
困りごと2:Instagram way
- PostgreSQLスケールアウトパターン Instagram way
- 小さく多数の論理shardを、少数の物理shard サーバーに mapする
- 物理Shard = Postgres データベースクラスタ(≒ DB Server)
- 論理Shard = Postgres の schema
- 急成長サービスは何度も再分割する=再分配が不要なやり方
Using PostgreSQL in Tantan - From 0 to 350bn rows in 2 years
Victor Blomqvist, Tantan (探探)
December 2, PGConf Asia 2016 in Tokyo
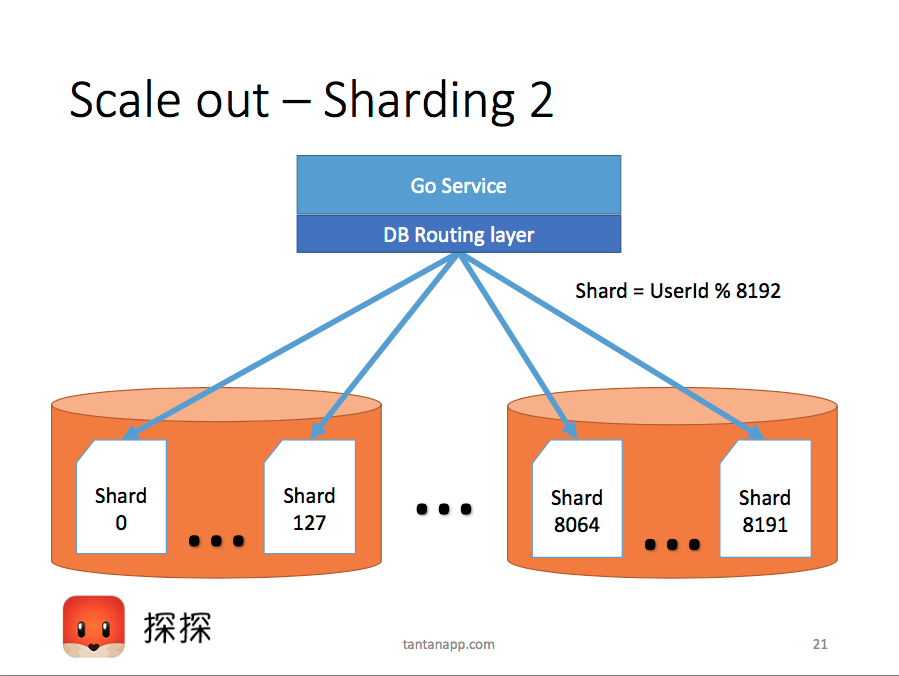
困りごと2:Instagram wayでのStatement
- 引数違いのSQLは同一視して、Statementに統計してくれる
- しかしschema違いの同型SQLは?
- DBServerあたり最大8192個のschemaがある
まとめ
- JPUGは控えめにいって最高
- pg_stats_reporter入れたらサービスの性能リスク減るよ
- オレオレ設定
- DB読影会のススメ
- オレオレ分析優先順位