バリデーションの際に想定外の文字が通っていないか調べるには Unicode で定義されるすべての文字を試すことが必要です。UTF-8 の場合、コードポイントの範囲は U+0000 から U+7FFF、U+E000 から U+10FFFF までです。
PHP 5 の標準関数である chr は U+0080 よりも大きいコードポイントの範囲には対応しておらず、主要な拡張モジュールにも該当する関数は皆無なので、自分で関数を定義する必要があります。ベンチマークの結果から html_entity_decode や chr を使った方法がもっとよいと考えられます。
ワンライナー
Ruby を利用する場合、次のようなコードになります。
ruby -e 'puts ARGV[0].to_i(16).chr("UTF-8")' 0x3042
複数のコードポイントを受けつけたい場合、少しコードを修正する必要があります。
ruby -e 'ARGV.each {|cp| puts cp.to_i(16).chr("UTF-8")}' 0x3042 0x3044 0x3046 0x3048 0x304A
PHP バージョンもやってみよう。PHP 5.6 の時点で mb_decode_numericentity がもっともコンパクトである。
php -r 'array_shift($argv); echo mb_decode_numericentity("&#".hexdec($argv[0]).";", [0, 0x10FFFF, 0, 0xFFFFFF], "UTF-8"), PHP_EOL;' 0x3042
複数のコードポイントをとるバージョンは次のとおり。
php -r 'array_shift($argv); foreach ($argv as $cp) echo mb_decode_numericentity("&#".hexdec($cp).";", [0, 0x10FFFF, 0, 0xFFFFFF], "UTF-8"), PHP_EOL;' 0x3042 0x3044 0x3046 0x3048 0x304A
mb_chr
PHP 7.2 から mb_chr が利用できるようなる予定です。
IntlChar::chr
PHP 7 から IntlChar::chr を使うことができます。
UTF-32 からの変換
文字コード変換関数の mb_convert_encoding もしくは UConverter::transcode を使います。iconv 関数はあまり使われていないので省略します。これらの関数を使うメリットは実装の間違いが少なくてすむことです。筆者は文字コード変換関数以外の関数を使った実装に間違いがないのかを確認するためにこの方法を選びます。デメリットはパフィーマンスです。すべての文字を4バイトで生成した上で別のバイト列に変換することになるからです。
function utf8_chr($cp) {
if (!is_int($cp)) {
exit("$cp is not integer\n");
}
if ($cp < 0 || (0xD7FF < $cp && $cp < 0xE000) || 0x10FFFF < $cp) {
exit("$cp is out of range\n");
}
return mb_convert_encoding(pack('N', $cp), 'UTF-8', 'UTF-32BE');
}
function utf8_chr2($cp) {
if (!is_int($cp)) {
exit("$cp is not integer\n");
}
if ($cp < 0 || (0xD7FF < $cp && $cp < 0xE000) || 0x10FFFF < $cp) {
exit("$cp is out of range\n");
}
return UConverter::transcode(pack('N', $cp), 'UTF8', 'UTF32_BigEndian');
}
HTML の数値文字参照
この方法で使う関数は mb_decode_numericentity もしくは html_entity_decode です。実装のためのコード量が少なく、処理速度が速いので、運用環境で使うとよいでしょう。html_entity_decode を使う場合、U+009F 以下の範囲では文字ではなく数値文字参照をそのまま返すので、この範囲の文字は chr 関数を使って生成します。chr を使ったやり方は後で紹介します。
function utf8_chr3($cp) {
if (!is_int($cp)) {
exit("$cp is not integer\n");
}
if ($cp < 0 || (0xD7FF < $cp && $cp < 0xE000) || 0x10FFFF < $cp) {
exit("$cp is out of range\n");
}
return mb_decode_numericentity('&#'.$cp.';', [0, 0x10FFFF, 0, 0xFFFFFF], 'UTF-8');
}
function utf8_chr4($cp) {
if (!is_int($cp)) {
exit("$cp is not integer\n");
}
if ($cp < 0 || (0xD7FF < $cp && $cp < 0xE000) || 0x10FFFF < $cp) {
exit("$cp is out of range\n");
}
if ($cp < 0x80) {
return chr($cp);
} else if ($cp < 0xA0) {
return chr(0xC0 | $cp >> 6).chr(0x80 | $cp & 0x3F);
}
return html_entity_decode('&#'.$cp.';');
}
Unicode エスケープシーケンス
json_decode もしくは transliterator_transliterate を使います。どちらの関数も4桁固定長のエスケープシーケンス (\uXXXX)しか扱えないので、U+10000 とそれ以降の範囲は2つのエスケープシーケンス (\uXXXX\uYYYY) を組み合わせることになります。HTML の数値文字参照よりもコードが少し長くなります。
function utf8_chr5($cp) {
if (!is_int($cp)) {
exit("$cp is not integer\n");
}
if ($cp < 0 || (0xD7FF < $cp && $cp < 0xE000) || 0x10FFFF < $cp) {
exit("$cp is out of range\n");
}
if ($cp < 0x10000) {
return json_decode('"\u'.bin2hex(pack('n', $cp)).'"');
}
// Q: Isn’t there a simpler way to do this?
// http://unicode.org/faq/utf_bom.html#utf16-4
$lead = 0xD800 - (0x10000 >> 10) + ($cp >> 10);
$trail = 0xDC00 + ($cp & 0x3FF);
return json_decode('"\u'.bin2hex(pack('n', $lead)).'\u'.bin2hex(pack('n', $trail)).'"');
}
function utf8_chr6($cp) {
if (!is_int($cp)) {
exit("$cp is not integer\n");
}
if ($cp < 0 || (0xD7FF < $cp && $cp < 0xE000) || 0x10FFFF < $cp) {
exit("$cp is out of range\n");
}
if ($cp < 0x10000) {
$hex = dechex($cp);
$hex = str_repeat('0', 4 - strlen($hex)).$hex;
return transliterator_transliterate('Hex-Any/Java', '\u'.$hex);
}
$high = 0xD800 | $cp - 0x10000 >> 10;
$low = 0xDC00 | $cp - 0x10000 & 0x3FF;
return transliterator_transliterate('Hex-Any/Java',
'\u'.dechex($high).'\u'.dechex($low));
}
ビット演算と chr
C/C++ 言語で UTF-8 の文字列関数を自分で定義する場合、ビット演算は必須です。フレームワークやライブラリのテストケースで採用されています。Unicode Standard の3章にビットの分布が記載されています (テーブル 3-6)。
| スカラー値 | 第1バイト | 第2バイト | 第3バイト | 第4バイト |
|---|---|---|---|---|
| 00000000 0xxxxxxx | 0xxxxxxx | |||
| 00000yyy yyxxxxxx | 110yyyyy | 10xxxxxx | ||
| zzzzyyyy yyxxxxxx | 1110zzzz | 10yyyyyy | 10xxxxxx | |
| 000uuuuu zzzzyyyy yyxxxxxx | 11110uuu | 10uuzzzz | 10yyyyyy | 10xxxxxx |
function utf8_chr7($cp) {
if (!is_int($cp)) {
exit("$cp is not integer\n");
}
if ($cp < 0 || (0xD7FF < $cp && $cp < 0xE000) || 0x10FFFF < $cp) {
exit("$cp is out of range\n");
}
if ($cp < 0x80) {
return chr($cp);
} else if ($cp < 0x800) {
return chr(0xC0 | $cp >> 6)
.chr(0x80 | $cp & 0x3F);
} else if ($cp < 0x10000) {
return chr(0xE0 | $cp >> 12)
.chr(0x80 | $cp >> 6 & 0x3F)
.chr(0x80 | $cp & 0x3F);
}
return chr(0xF0 | $cp >> 18)
.chr(0x80 | $cp >> 12 & 0x3F)
.chr(0x80 | $cp >> 6 & 0x3F)
.chr(0x80 | $cp & 0x3F);
}
ビット演算の計算過程
計算過程をわかりやすいようにするために、ビット演算に使う数値を2進数に書き換えたものは次のようになります。
var_dump(
'$' === utf8_chr8(0x0024),
'¢' === utf8_chr8(0x00A2),
'€' === utf8_chr8(0x20AC),
'?' === utf8_chr8(0x10348)
);
function utf8_chr8($cp) {
if (!is_int($cp)) {
exit("$cp is not integer\n");
}
if ($cp < 0 || (0xD7FF < $cp && $cp < 0xE000) || 0x10FFFF < $cp) {
exit("$cp is out of range\n");
}
if ($cp < 0x80) {
return chr($cp);
} else if ($cp < 0x800) {
return chr(0b11000000 + ($cp >> 6))
.chr(0b10000000 + ($cp & 0b111111));
} else if ($cp < 0x10000) {
return chr(0b11100000 + ($cp >> 12))
.chr(0b10000000 + ($cp >> 6 & 0b111111))
.chr(0b10000000 + ($cp & 0b111111));
}
return chr(0b11110000 + ($cp >> 18))
.chr(0b10000000 + ($cp >> 12 & 0b111111))
.chr(0b10000000 + ($cp >> 6 & 0b111111))
.chr(0b10000000 + ($cp & 0b111111));
}
Wikipedia の UTF-8 の記事には1バイト文字から4バイト文字までの対応表が記載されている。
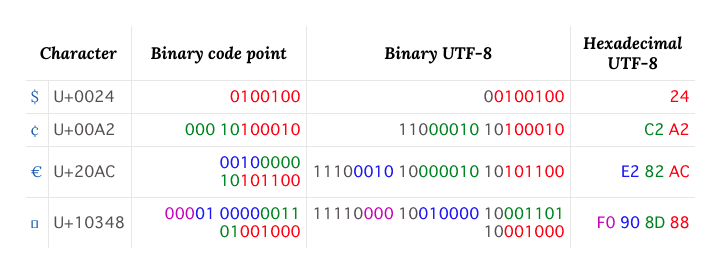
先ほど実装した関数がバイト列の計算結果が想定どおりになっているか4バイト文字の U+10348 で試してみよう。
$cp = 0x10348;
$char = "\xF0\x90\x8D\x88";
var_dump(
'10000001101001000' === decbin($cp),
[
'11110000' === decbin(ord($char[0])),
'10010000' === decbin(ord($char[1])),
'10001101' === decbin(ord($char[2])),
'10001000' === decbin(ord($char[3]))
],
'11110000' === decbin(0b11110000 + ($cp >> 18)),
'10010000' === decbin(0b10000000 + ($cp >> 12 & 0b111111)),
'10001101' === decbin(0b10000000 + ($cp >> 6 & 0b111111)),
'10001000' === decbin(0b10000000 + ($cp & 0b111111))
);
テスト
同じコードポイントから同じ文字が生成されるか比較します。
test('utf8_chr', 'utf8_chr2');
function test($callable, $callable2) {
for ($i = 0; $i < 0x110000; ++$i) {
if ($i > 0xD7FF && $i < 0xE000) {
continue;
}
$char = $callable($i);
$char2 = $callable2($i);
$hex = strtoupper(dechex($i));
if ($char !== $char2) {
echo 'U+',
$i < 0x1000 ? str_repeat('0', 4 - strlen($hex)) : '',
$hex, PHP_EOL;
}
}
}
ベンチマーク
筆者のマシンでは html_entity_decode を使ったコードが最速で、2位が chr でした。transliterator_transliterate は一桁遅いので、使わないほうがよいでしょう。
array (
'html_entity_decode' => 0.12990903854370117,
'chr' => 0.16111207008361816,
'json_decode' => 0.23690009117126465,
'mb_decode_numericentity' => 0.2619929313659668,
'mb_convert_encoding' => 0.42672300338745117,
'UConverter::transcode' => 0.51613211631774902,
'transliterator_transliterate' => 6.8395729064941406,
)
$ret = [
'mb_convert_encoding' => timer(function() {
utf8_chr(0x10FFFF);
}),
'UConverter::transcode' => timer(function() {
utf8_chr2(0x10FFFF);
}),
'mb_decode_numericentity' => timer(function() {
utf8_chr3(0x10FFFF);
}),
'html_entity_decode' => timer(function() {
utf8_chr4(0x10FFFF);
}),
'json_decode' => timer(function() {
utf8_chr5(0x10FFFF);
}),
'transliterator_transliterate' => timer(function() {
utf8_chr6(0x10FFFF);
}),
'chr' => timer(function() {
utf8_chr7(0x10FFFF);
})
];
asort($ret);
var_export($ret);
function timer($callable, $repeat = 100000) {
if (!is_int($repeat)) {
exit("$repeat is not integer");
}
if ($repeat < 0) {
exit("$repeat is not positive integer");
}
$start = microtime(true);
do {
$callable();
} while($repeat -= 1);
$stop = microtime(true);
return $stop - $start;
}