文字の Unicode プロパティやエンコーディングに関する情報を検索で調べる際にコードポイントが必要になることがあります。PHP 5.5 で intl 拡張モジュールに IntlCodePointBreakIterator が追加され、コードポイントを求めやすくなりました。
ワンライナー
ターミナルで調べるにはワンライナーのためのスクリプトを用意しておくと便利です。Ruby の場合、次のようになります。
ruby -e 'puts ARGV[0].ord.to_s(16).upcase' あ
少し修正すれば、文字列に対応させることができます。
ruby -e 'ARGV[0].each_char {|c| puts c.ord.to_s(16).upcase }' あいうえお
PHP バージョンをやってみよう。IntlCodePointBreakIterator を使う場合、次のようになる。
php -r '$it = IntlCodePointBreakIterator::createCodePointInstance(); $it->setText($argv[1]); while ($it->next() !== IntlCodePointBreakIterator::DONE) echo dechex($it->getLastCodePoint()), PHP_EOL;
;' あいうえお
不正なバイト列の扱い
この記事では IntlCodePointBreakIterator にならい、代替文字 (U+FFFD) のコードポイントである 0xFFFD を返すことにします。エラーや例外で処理を停止させる選択肢もありますが、毎回、不正なバイト列が含まれていないかチェックすることが必要になるので、不便です。
mb_ord
PHP 7.2 で導入される予定です。
IntlChar::ord
PHP 7 では IntlChar::ord を使うことができます。
IntlCodePointBreakIterator
createCodePointInstance メソッドでインスタンスを生成します。
function utf8_ord($char) {
$it = IntlCodePointBreakIterator::createCodePointInstance();
$it->setText($char);
$it->next();
return $it->getLastCodePoint();
}
UTF-32 への変換
mb_convert_encoding もしくは UConverter::transcode を使います。
function utf8_ord2($char) {
$char = mb_substr($char, 0, 1, 'UTF-8');
if ($char !== mb_convert_encoding($char, 'UTF-8', 'UTF-8')) {
return 0xFFFD;
}
$ret = mb_convert_encoding($char, 'UTF-32BE', 'UTF-8');
return hexdec(bin2hex($ret));
}
function utf8_ord3($char) {
$it = IntlBreakIterator::createCharacterInstance('en_US.UTF-8');
$it->setText($char);
$pos = $it->next();
$char = substr($char, 0, $pos);
$ret = UConverter::transcode($char, 'UTF32_BigEndian', 'UTF8');
return $ret !== '' ? (int) hexdec(bin2hex($ret)) : 0xFFFD;
}
HTML 数値文字参照
mb_encode_numericentity を使います。mb_convert_encoding で UTF-8 から HTML-ENTITIES に変換する場合、文字実体参照に変換される文字が多いので、コードポイントを求める用途には不向きです。
function utf8_ord4($char) {
$char = mb_substr($char, 0, 1, 'UTF-8');
$ret = mb_encode_numericentity($char, [0, 0x10FFFF, 0, 0xFFFFFF], 'UTF-8', true);
if ($ret === '?') {
return 0xFFFD;
}
$ret = substr($ret, 3, strlen($ret) - 4);
return (int) hexdec($ret);
}
Unicode エスケープシーケンス
json_encode もしくは transliterator_transliterate を使います。json_encode の場合、制御文字のエスケープシーケンスについて場合わけをしなければならないことがめんどうです。
function utf8_ord5($char) {
$c = htmlspecialchars_decode(htmlspecialchars($char, ENT_COMPAT, 'UTF-8'));
if ($c !== $char) {
return 0xFFFD;
}
$json = json_encode($c);
$head = substr($json, 1, 2);
if ('\b' === $head) {
return 0x8;
} else if ('\t' === $head) {
return 0x9;
} else if ('\n' === $head) {
return 0xA;
} else if ('\f' === $head) {
return 0xC;
} else if ('\r' === $head) {
return 0xD;
} else if ('\"' === $head) {
return 0x22;
} else if ('\/' === $head) {
return 0x2F;
} else if ('\u' !== $head) {
return ord($json[1]);
}
$lead = hexdec(substr($json, 3, 4));
if (0xD7FF < $lead && $lead < 0xDC00) {
$trail = hexdec(substr($json, 9, 4));
return (($lead & 0x3FF) << 10) + ($trail & 0x3FF) + 0x10000;
}
return $lead;
}
function utf8_ord6($char) {
$ret = transliterator_transliterate("Any-Hex/Java", $char);
if ($ret === false) {
return 0xFFFD;
}
$lead = hexdec(substr($ret, 2, 4));
if ($lead > 0xD7FF && $lead < 0xDC00) {
$trail = hexdec(substr($ret, 8, 4));
return (($lead & 0x3FF) << 10) + ($trail & 0x3FF) + 0x10000;
}
return $lead;
}
ビット演算と ord
パフォーマンス改善のために不正なバイト列の検出には htmlspecialchars を利用します。Unicode Standard の3章にビットの分布が記載されています (テーブル 3-6)。
| スカラー値 | 第1バイト | 第2バイト | 第3バイト | 第4バイト |
|---|---|---|---|---|
| 00000000 0xxxxxxx | 0xxxxxxx | |||
| 00000yyy yyxxxxxx | 110yyyyy | 10xxxxxx | ||
| zzzzyyyy yyxxxxxx | 1110zzzz | 10yyyyyy | 10xxxxxx | |
| 000uuuuu zzzzyyyy yyxxxxxx | 11110uuu | 10uuzzzz | 10yyyyyy | 10xxxxxx |
var_dump(
0x0024 === utf8_ord7('$'),
0x00A2 === utf8_ord7('¢'),
0x20AC === utf8_ord7('€'),
0x10348 === utf8_ord7('?')
);
function utf8_ord7($char) {
if ($char !== htmlspecialchars_decode(htmlspecialchars($char, ENT_COMPAT, 'UTF-8'))) {
return 0xFFFD;
}
$x = ord($char[0]);
if ($x < 0x80) {
return $x;
} else if ($x < 0xE0) {
$y = ord($char[1]);
return (($x & 0x1F) << 6) | ($y & 0x3F);
} else if ($x < 0xF0) {
$y = ord($char[1]);
$z = ord($char[2]);
return (($x & 0xF) << 12) | (($y & 0x3F) << 6) | ($z & 0x3F);
}
$y = ord($char[1]);
$z = ord($char[2]);
$w = ord($char[3]);
return (($x & 0x7) << 18) | (($y & 0x3F) << 12) | (($z & 0x3F) << 6) | ($w & 0x3F);
}
ビット演算の計算過程
計算過程をわかりやすいようにするために、ビット演算に使う数値を2進数に書き換えたものは次のようになります。
function utf8_ord8($char) {
if ($char !== htmlspecialchars_decode(htmlspecialchars($char, ENT_COMPAT, 'UTF-8'))) {
return 0xFFFD;
}
$x = ord($char[0]);
if ($x < 0x80) {
return $x;
} else if ($x < 0xE0) {
$y = ord($char[1]);
return (($x & 0b11111) << 6) + ($y & 0b111111);
} else if ($x < 0xF0) {
$y = ord($char[1]);
$z = ord($char[2]);
return (($x & 0b1111) << 12) + (($y & 0b111111) << 6) + ($z & 0b111111);
}
$y = ord($char[1]);
$z = ord($char[2]);
$w = ord($char[3]);
return (($x & 0b1111) << 18) + (($y & 0b111111) << 12) + (($z & 0b111111) << 6) + ($w & 0b111111);
}
Wikipedia の UTF-8 の記事にコードポイントとバイト列の関係が記載されています。
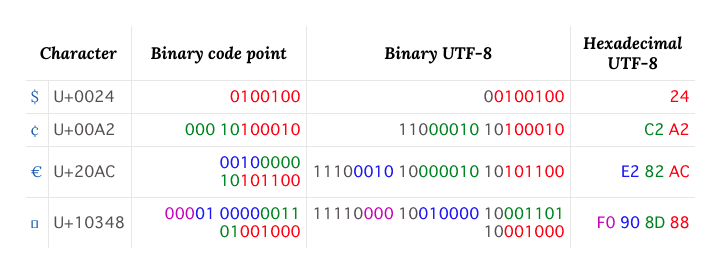
4バイト文字の U+10348 で確認してみましょう。
$cp = 0x10348;
$char = "\xF0\x90\x8D\x88";
var_dump(
'10000001101001000' === decbin($cp),
[
'11110000' === decbin(0xF0),
'10010000' === decbin(0x90),
'10001101' === decbin(0x8D),
'10001000' === decbin(0x88)
],
'0' === decbin((0b11110000 & 0b1111) << 18),
'10000000000000000' === decbin((0b10010000 & 0b111111) << 12),
'1101000000' === decbin((0b10001101 & 0b111111) << 6),
'1000' === decbin(0b10001000 & 0b111111)
);
テスト
0 から 0x10FFFF までの整数から生成した文字をコードポイントに変換して、元の整数と一致するか確認します。
test('utf8_ord');
function test(callable $callable) {
for ($i = 0; $i < 0x110000; ++$i) {
if ($i > 0xD7FF && $i < 0xE000) {
continue;
}
$char = utf8_chr($i);
$cp = $callable($char);
if ($cp !== $i) {
$hex = strtoupper(dechex($i));
echo 'U+',
$i < 0x10000 ? str_repeat('0', 4 - strlen($hex)) : '',
$hex, PHP_EOL;
}
}
}
function utf8_chr($cp) {
if (!is_int($cp)) {
exit("$cp is not integer\n");
}
if ($cp < 0 || (0xD7FF < $cp && $cp < 0xE000) || 0x10FFFF < $cp) {
exit("$cp is out of range\n");
}
return mb_decode_numericentity('&#'.$cp.';', [0, 0x10FFFF, 0, 0x11FFFF], 'UTF-8');
}
簡易ベンチマーク
ord を使った方法がもっとも速く、次点が IntlCodePointBreakIterator でした。transliterator_transliterate は一桁遅いので、運用環境で使わないほうがよいでしょう。
array(7) {
["ord"]=>
float(0.21411490440369)
["IntlCodePointBreakIterator"]=>
float(0.2562141418457)
["json_encode"]=>
float(0.30807304382324)
["mb_encode_numericentity"]=>
float(0.394446849823)
["mb_convert_encoding"]=>
float(0.60804796218872)
["UConverter::transcode"]=>
float(1.3823528289795)
["transliterator_transliterate"]=>
float(6.6276679039001)
}
$ret = [
'IntlCodePointBreakIterator' => timer(function() {
utf8_ord("\xF4\x8F\xBF\xBF");
}),
'mb_convert_encoding' => timer(function() {
utf8_ord2("\xF4\x8F\xBF\xBF");
}),
'UConverter::transcode' => timer(function() {
utf8_ord3("\xF4\x8F\xBF\xBF");
}),
'mb_encode_numericentity' => timer(function() {
utf8_ord4("\xF4\x8F\xBF\xBF");
}),
'json_encode' => timer(function() {
utf8_ord5("\xF4\x8F\xBF\xBF");
}),
'transliterator_transliterate' => timer(function() {
utf8_ord6("\xF4\x8F\xBF\xBF");
}),
'ord' => timer(function() {
utf8_ord7("\xF4\x8F\xBF\xBF");
})
];
asort($ret);
var_dump($ret);
function timer(callable $callable, $repeat = 100000) {
if (!is_int($repeat)) {
exit("$repeat is not integer");
}
if ($repeat < 0) {
exit("$repeat is not positive integer");
}
$start = microtime(true);
do {
$callable();
} while($repeat -= 1);
$stop = microtime(true);
return $stop - $start;
}