第4章 形態素解析、第5章 係り受け解析と言語処理100本ノックをPython3で解いてきました。
私はさしあたって、「第6章: 英語テキストの処理」、「第7章: データベース」あたりの内容は必要としていないので、それらはスキップして「第8章: 機械学習」を進めていきます。
私の知識レベルとしては、Pythonは仕事で使ったことはなく、Courseraで入門的な授業を一つとった程度、自然言語処理/機械学習は全くの素人だが、これから仕事で使おうとしているといった感じです。
この章からは、いよいよ問題文が言っていることを全く理解できなくなって来たので、用語の説明もメモしていきます。
この章で使うデータ
- 1万件ぐらいの映画の英文レビュー。肯定的なレビューと否定的なレビューがそれぞれ約5千件づつ含まれている。
この章でやっていること
- 各レビュー文から各レビューが肯定的か否定的かを予想するモデルを作る。
- 教師あり学習
- ロジスティック回帰
- 長いので勝手に5つのステージに分割して説明しています。1. 素性設計 => 2. 学習 => 3. 検証 => 4. 5分割交差検定による学習と検証 => 5. 閾値の変化による適合率と再現率の変化を観察
参考にしたサイト
- JAIST 言語情報処理 用語集
- Negative/Positive Thinking 文書分類メモ
- 北野坂備忘録 言語処理100本ノック 2015年版 (73)
- Gihyo.jp 機械学習 はじめよう 第18回 ロジスティック回帰
0. 準備 (70. データの入手・整形)
本章では,Bo Pang氏とLillian Lee氏が公開しているMovie Review Dataのsentence polarity dataset v1.0を用い,文を肯定的(ポジティブ)もしくは否定的(ネガティブ)に分類するタスク(極性分析)に取り組む.
文に関する極性分析の正解データを用い,以下の要領で正解データ(sentiment.txt)を作成せよ.
rt-polarity.posの各行の先頭に"+1 "という文字列を追加する(極性ラベル"+1"とスペースに続けて肯定的な文の内容が続く)
rt-polarity.negの各行の先頭に"-1 "という文字列を追加する(極性ラベル"-1"とスペースに続けて否定的な文の内容が続く)
上述1と2の内容を結合(concatenate)し,行をランダムに並び替える
sentiment.txtを作成したら,正例(肯定的な文)の数と負例(否定的な文)の数を確認せよ.
用語の確認
- 極性 (polarity): 文、句、語などの言語表現が肯定的もしくは否定的な意味を持つとき、「肯定」もしくは「否定」をその言語表現の極性という。極性を自動的に判定することは、評判情報処理の基礎的な技術である。
コード
from ml.Sentiment import Sentiments, Util
from ml.Model import LogisticRegression
import matplotlib.pyplot as plt
sentiments = Sentiments()
sentiments.restore_from_pos_neg_file('../8_ML/rt-polarity.pos', '../8_ML/rt-polarity.neg')
sentiments.shuffle()
sentiments.save('../8_ML/70_sentiment.txt')
import random
import re
from itertools import chain
from nltk.stem.porter import PorterStemmer
from stop_words import get_stop_words
from ml.Model import LogisticRegression
class Sentiments:
"""
レビューのリストを管理するクラス
"""
def __init__(self) -> None:
self.all = []
def restore_from_pos_neg_file(self, pos_file: str, neg_file: str) -> None:
"""
肯定的文章と否定的文章に極性ラベルをつけてリストとして保持する.
肯定的文章には極性ラベルとして'1'を、否定的文章には極性ラベルとして'-1'をつける.
:param pos_file 肯定的文章を保存したファイル(latin_1)
:param neg_file 否定的文章を保存したファイル(latin_1)
"""
with open(pos_file, encoding='latin_1') as input_file:
self.all += [{'label': 1, 'sentence': line.replace('\n', '')} for line in input_file]
with open(neg_file, encoding='latin_1') as input_file:
self.all += [{'label': -1, 'sentence': line.replace('\n', '')} for line in input_file]
def shuffle(self):
random.shuffle(self.all)
1. 素性設計 (71. ストップワード / 72. 素性抽出)
- 71.英語のストップワードのリスト(ストップリスト)を適当に作成せよ.さらに,引数に与えられた単語(文字列)がストップリストに含まれている場合は真,それ以外は偽を返す関数を実装せよ.さらに,その関数に対するテストを記述せよ.
- 72.極性分析に有用そうな素性を各自で設計し,学習データから素性を抽出せよ.素性としては,レビューからストップワードを除去し,各単語をステミング処理したものが最低限のベースラインとなるであろう.
用語の確認
-
ストップワード (stop words):
情報検索において、索引語から除去するべき語のリスト。付属語や、be, have のような一般的な意味を持つ語など、情報検索に有効でないと考えられる語から構成される。ストップワードは数が限られるため、あらかじめ人手で作成しておくことが多い。
「適当に作成せよ」ということで少し迷いますが、他の人がどうやっているかサラッと見てみたところ、「本当にテキトーに作る」「形態素分析+頻度分析をして作る」「ネットで一般的なリストを拾ってきてベタ書きする」などの方法をとっている人いるようです。
ここではstop-wordsというpythonパッケージを使おうと思います。 -
素性 (feature):
機械学習の際、データを分類する手がかりとなる情報を指す。学習素性 (feature for machine learning) ともいう。
例えば、単語の品詞を推定するモデルを機械学習する際には、その単語の前後に出現する語や品詞が学習素性として使われる。
言い換えれば、前後に出現する語や品詞を手がかりとして対象語の品詞を推定するモデルを学習する。
学習素性として何を使うかは、機械学習に基づく自然言語処理の成否を決める重要な要因である。 -
学習データ:
機械学習において、分類モデルを自動的に学習するために用いるデータ。訓練データ。
sentiment.txtに保存したレビューデータ(sentimentsリスト)のことですね。 -
ステミング処理 (Stemming):
Stem = 語幹。語幹は語基とも言い、語の語形変化において、変化しない部分のこと。例えば、「投げる」という動詞なら「投げ」が語幹になる。
ステミング処理とは「投げる」という語を「投げ」に変換すること。
Pythonでは、nltk.stem.porterパッケージのPorterStemmerクラスのstemメソッドで実行できる。
(「52. ステミング」で取り上げられている。) -
素性を設計:
極性分析に有用そうな素性を各自で設計。。。って何をすれば良いんだろう?
問題文中で最低限のベースラインとされている、ストップワード除去+ステミング処理以外に、出現回数が多すぎる(10,000回以上)、もしくは、少なすぎ(3回以下)て極性に影響がなさそうな単語は、素性から取り除いてみたが最終的に良い結果が出なかったので、ここでは最低限のベースラインで進める。
コード
sentimentsが持つレビュー毎に素性リストを追加していきます。
sentiments.add_features()
sentiments.save('../8_ML/72_sentiment.txt')
class Sentiments:
# 紹介済みメソッド
def __init__(self) -> None: ...
def restore_from_pos_neg_file(self, pos_file: str, neg_file: str) -> None: ...
# 以下、1. 素性設計 (71. ストップワード / 72. 素性抽出)で追加するメソッド
def add_features(self):
stemmer = PorterStemmer()
# 学習データに素性情報を追加していきます
for sentiment in self.all:
words = re.compile(r'[,.:;\s]').split(sentiment['sentence'])
features = []
for word in words:
stem = stemmer.stem(word)
# if not (stop_words.is_stop_word(stem) or is_freq_word(stem) or stem == ''):
if not (Util.is_stop_word(stem) or stem == ''):
features.append(stem)
sentiment['features'] = list(set(features))
class Util:
stop_words = get_stop_words('english')
@staticmethod
def is_stop_word(_word: str) -> bool:
"""
引数に与えられた単語(文字列)がストップリストに含まれている場合は真,それ以外は偽を返す
:param _word 単語
:return bool 引数に与えられた単語(文字列)がストップリストに含まれている場合は真,それ以外は偽
"""
return _word in Util.stop_words
2. 学習 (73. 学習 / 75. 素性の重み)
- 72で抽出した素性を用いて,ロジスティック回帰モデルを学習せよ.
- 73で学習したロジスティック回帰モデルの中で,重みの高い素性トップ10と,重みの低い素性トップ10を確認せよ.
用語の確認
-
ロジスティック回帰モデルを学習
正確な定義を説明できるほどちゃんと理解できてないが、「72で作ったlabelとfeaturesの対応から、識別関数(シグモイド関数)を使って「重みベクトル」を算出すること」だと暫定的に理解しておきます。 -
重みベクトル
各素性が結果にどの程度影響を与えるかを表す値の集まり(Python的にはdict型で表す)。
例えば、下記プログラムを実行すると、{..., 'perfect': 1.829376624682014, 'remark': 1.8879018752394459, 'dull': -2.8891666516371806, 'bore': -3.153237996082115, ... のようなdictweightsが取れます。これは、レビュー文中にperfectやremarkという言葉(語幹)が入っていれば肯定的なレビューである可能性が高く、dullやboreという言葉が入っていれば否定的なレビューである可能性が高いというふうに解釈できます。直感的にも妥当だと思える数字になってますね。 -
識別関数(シグモイド関数)
重みベクトルと素性リストをインプットとして、肯定的レビューである可能性を予測する関数。
内部的に計算ロジックはここでは気にしないでおきます。 -
学習率
適当な正の値で、一回の更新でパラメータをどれくらい動かすかを調整します。学習率が大きいほど学習は速くなりますが,予測確率が安定しません。初期値は0.1くらいにして、学習が進むにつれて徐々に小さくしていく、というのが一般的らしいですが、ここでは試行錯誤の末、0.6にしています。
コード
model = LogisticRegression()
model.calc_weights(sentiments=sentiments.all)
import math
from collections import defaultdict
class LogisticRegression:
def __init__(self):
self.weights = defaultdict(float) # 重みベクトル
def predict(self, _features: list) -> float:
"""
識別関数: 重みベクトルと素性リストをインプットとして、肯定的レビューである可能性を予測する
:param _features レビュー文毎にまとめられた素性のリスト
:return 肯定的レビューである確率
"""
# 重みベクトルと素性リストの内積
x = sum([self.weights[feature] for feature in _features])
# シグモイド関数
return 1.0 / (1.0 + math.exp(-x))
def update(self, _features: list, _label: int, _eta: float) -> None:
"""
重みベクトルを更新する.
:param _features レビュー文毎にまとめられた素性のリスト
:param _label レビュー文につけられたラベル (肯定的レビュー:+1 / 否定的レビュー:-1)
:param _eta 学習率
"""
# 識別関数によって予測した答え (肯定的レビューである確率)
predict_answer = self.predict(_features)
# 実際に肯定的レビューであるかどうか (ラベルを確率に変換する (-1 => 0.0000, 1 => 1.0000))
actual_answer = (float(_label) + 1) / 2
# 重みベクトルの更新
for _feature in _features:
_dif = _eta * (predict_answer - actual_answer)
# 差が0に近づきすぎたら更新しない
if 0.0002 > abs(self.weights[_feature] - _dif):
continue
self.weights[_feature] -= _dif
def calc_weights(self, eta0: float = 0.6, etan: float = 0.9999, sentiments: list = None) -> None:
"""
重みベクトルを計算
:param eta0 初期学習率
:param etan 学習率減少率
:param sentiments レビューのラベル、文章、素性リストを含む辞書のリスト
"""
for idx, sentiment in enumerate(sentiments):
self.update(sentiment['features'], sentiment['label'], eta0 * (etan ** idx))
def save_weights(self, file_name: str) -> None:
"""
重みベクトルをファイルに書き出す (ソートしておきます)
:param file_name ファイル名
"""
with open(file_name, mode='w', encoding='utf-8') as output:
for k, v in sorted(self.weights.items(), key=lambda x: x[1]):
output.write('{}\t{}\n'.format(k, v))
def restore_weights(self, file_name: str) -> dict:
"""
重みベクトルをファイルから復元する
:param file_name 重みベクトルが保存されているファイル名
:return 重みベクトル
"""
weights = {}
with open(file_name, encoding='utf-8') as input_file:
for line in input_file:
key, value = line.split()
weights[key] = float(value)
self.weights = weights
3. 検証 (74. 予測 / 76. ラベル付け / 77. 正解率の計測)
- 73で学習したロジスティック回帰モデルを用い,与えられた文の極性ラベル(正例なら"+1",負例なら"-1")と,その予測確率を計算するプログラムを実装せよ.
- 学習データに対してロジスティック回帰モデルを適用し,正解のラベル,予測されたラベル,予測確率をタブ区切り形式で出力せよ.
- 76の出力を受け取り,予測の正解率,正例に関する適合率,再現率,F1スコアを求めるプログラムを作成せよ.
用語の確認
- 正例に関する適合率 (precision rate): 正例を正例と予測できた数 / 正例と予測した数
- 再現率 (recall rate): 正例を正例と予測できた数 / 実際の正例の数
- F1スコア 適合率と再現率の調和平均 = ( 2 * 適合率 * 再現率 ) / ( 適合率 + 再現率 )
コード
sentiments.add_predict(model.predict)
score = sentiments.calc_score()
Util.print_score(score, '77. 正解率の計測')
class Sentiments:
# 紹介済みメソッド
def __init__(self) -> None: ...
def restore_from_pos_neg_file(self, pos_file: str, neg_file: str) -> None: ...
def add_features(self) -> None: ...
# 以下、ここで追加するメソッド
def add_predict(self, predict_func: classmethod, threshold: float = 0.0):
for sentiment in self.all:
probability = predict_func(sentiment['features'])
sentiment['probability'] = probability
if probability > 0.5 + threshold:
sentiment['predict_label'] = 1
elif probability < 0.5 - threshold:
sentiment['predict_label'] = -1
else:
sentiment['predict_label'] = 0
def calc_score(self) -> dict:
count = 0
correct_count = 0
actual_positive_count = 0
predict_positive_count = 0
correct_positive_count = 0
for sentiment in self.all:
count += 1
correct = int(sentiment['label']) == int(sentiment['predict_label'])
positive = int(sentiment['label']) == 1
predict_positive = int(sentiment['predict_label']) == 1
if correct:
correct_count += 1
if positive:
actual_positive_count += 1
if predict_positive:
predict_positive_count += 1
if correct and predict_positive:
correct_positive_count += 1
precision_rate = correct_positive_count / predict_positive_count
recall_rate = correct_positive_count / actual_positive_count
f_value = (2 * precision_rate * recall_rate) / (precision_rate + recall_rate)
return {
'correct_rate': correct_count / count,
'precision_rate': precision_rate,
'recall_rate': recall_rate,
'f_value': f_value
}
class Util:
# 紹介済みメソッド
def is_stop_word(_word: str) -> bool: ...
# 以下、ここで追加するメソッド
@staticmethod
def print_score(score: dict, title: str = '') -> None:
print('\n{}\n\t予測の正解率: {}\n\t正例に関する適合率: {}\n\t再現率: {}\n\tF1スコア: {}'.format(
title, score['correct_rate'], score['precision_rate'], score['recall_rate'], score['f_value']))
出力結果
大きく外してはなさそうです。
77. 正解率の計測
予測の正解率: 0.8743200150065654
正例に関する適合率: 0.8564029290944811
再現率: 0.8994560120052523
F1スコア: 0.8774016468435498
4. 5分割交差検定による学習と検証 (78. 5分割交差検定)
76-77の実験では,学習に用いた事例を評価にも用いたため,正当な評価とは言えない.すなわち,分類器が訓練事例を丸暗記する際の性能を評価しており,モデルの汎化性能を測定していない.そこで,5分割交差検定により,極性分類の正解率,適合率,再現率,F1スコアを求めよ.
用語の確認
- 5分割交差検定: 学習データを5つに分割して、4つを学習に、1つをテストに使ったモデルの構築・評価を組み合わせを変えて5回実施する方法。
コード
sentiments.restore('../8_ML/72_sentiment.txt') # 未学習のsentimentsをリストアします.
score = sentiments.cross_validation(model=LogisticRegression())
Util.print_score(score, '78. 5分割交差検定')
class Sentiments:
# 紹介済みメソッド
def __init__(self) -> None: ...
def restore_from_pos_neg_file(self, pos_file: str, neg_file: str) -> None: ...
def add_features(self) -> None: ...
def add_predict(self, predict_func: classmethod, threshold: float = 0.0) -> None: ...
def calc_score(self) -> dict: ...
# 以下、ここで追加するメソッド
def restore(self, file: str):
_sentiments = []
with open(file, encoding='utf-8') as input_file:
for line in input_file:
_label, _sentence, _features_str, _probability, _predict_label = line.split('\t')
_sentiments.append({
'label': int(_label),
'sentence': _sentence,
'features': _features_str.split(' '),
'probability': 0 if _probability == '' else float(_probability),
'predict_label': 0 if _predict_label.rstrip() == '' else float(_predict_label)
})
self.all = _sentiments
def cross_validation(self, _divide_count: int = 5, model: LogisticRegression = None, threshold: float = 0.0) -> dict:
divided_list = Util.divide_list(self.all, _divide_count)
_scores = []
for i in range(_divide_count):
# 学習
learning_data = list(chain.from_iterable([divided_list[x] for x in [_i for _i in range(_divide_count) if _i != i]]))
model.calc_weights(sentiments=learning_data)
# テスト
self.all = divided_list[i]
self.add_predict(model.predict, threshold)
_scores.append(self.calc_score())
return {
'correct_rate': sum([_score['correct_rate'] for _score in _scores]) / _divide_count,
'precision_rate': sum([_score['precision_rate'] for _score in _scores]) / _divide_count,
'recall_rate': sum([_score['recall_rate'] for _score in _scores]) / _divide_count,
'f_value': sum([_score['f_value'] for _score in _scores]) / _divide_count
}
class Util:
# 紹介済みメソッド
def is_stop_word(_word: str) -> bool: ...
def print_score(score: dict, title: str = '') -> None: ...
# 以下、ここで追加するメソッド
@staticmethod
def divide_list(lst: list, count: int) -> list:
"""
リストを指定された数で分割する
:param lst 分割対象のリスト
:param count いくつに分割するか
:return list 分割後のリスト
"""
divided_list = []
list_len = len(lst) / count
for _i in range(count):
begin_index = int(_i * list_len)
end_index = int((_i + 1) * list_len if _i + 1 < count else len(lst))
divided_list.append(lst[begin_index:end_index])
return divided_list
出力結果
77と比べると当然下がっているものの、それほど大きな悪化ではないですね。
78. 5分割交差検定
予測の正解率: 0.848988423671968
正例に関する適合率: 0.8481575029900081
再現率: 0.852642297684391
F1スコア: 0.8503632552717463
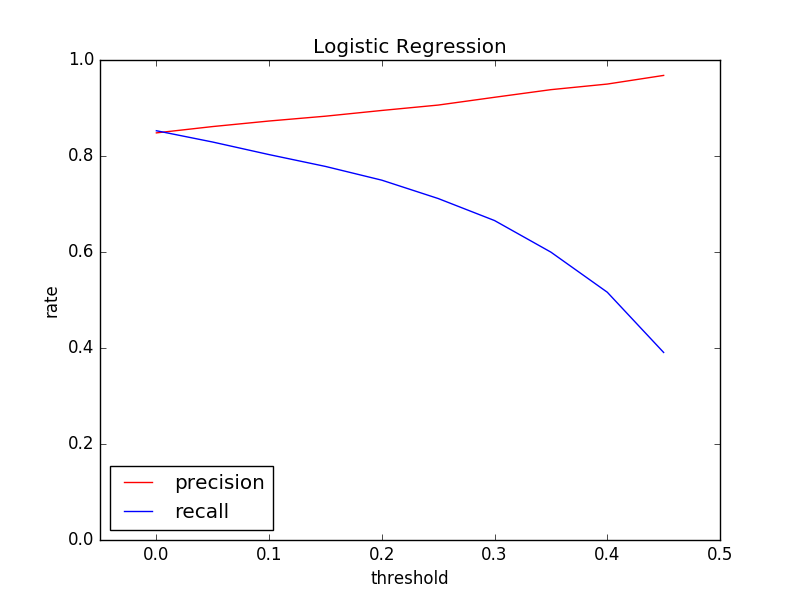
5. 閾値の変化による適合率と再現率の変化を観察 (79. 適合率-再現率グラフの描画)
ロジスティック回帰モデルの分類の閾値を変化させることで,適合率-再現率グラフを描画せよ.
用語の確認
- 閾値: ここまでは予測したラベルがポジティブである可能性が0.5以上ならポジティブ、そうでなければネガティブと判定してきました。この判定基準を閾値と呼んでいるようです。
コード
閾値を0.0から0.45まで0.05区切りで変化させて、適合率と再現率の推移を観察してみます。
precision_rates = []
recall_rates = []
thresholds = [t / 20 for t in range(10)]
for threshold in thresholds:
sentiments.restore('../8_ML/72_sentiment.txt') # 未学習のsentimentsをリストアします.
score = sentiments.cross_validation(model=LogisticRegression(), threshold=threshold)
precision_rates.append(score['precision_rate'])
recall_rates.append(score['recall_rate'])
print(thresholds)
print(precision_rates)
print(recall_rates)
plt.plot(thresholds, precision_rates, label="precision", color="red")
plt.plot(thresholds, recall_rates, label="recall", color="blue")
plt.xlabel("threshold")
plt.ylabel("rate")
plt.xlim(-0.05, 0.5)
plt.ylim(0, 1)
plt.title("Logistic Regression")
plt.legend(loc=3)
plt.show()
出力結果
閾値を上げるというのは、絶対確実なときだけ予測するということなので、閾値が上がれば上がるほど、適合率は上がっていきますね。逆に、絶対確実なときだけしか予測しないということなので、再現率の方は下がっていきます。