経緯
研究室の論文管理が煩雑なので(WEBに載せる必要がある,報告書に書く必要がある,科研費の申請の書類に必要,しかもそれらはフォーマットが違ったりする←∑(゚д゚lll)ガーン んじゃ,pubmedから情報を収集するフォーマットと,それを簡単に編集できるプログラムを書いたらいいんじゃない?と思い,ちょいと取り組んで見ることにした。
PubMed(ぱぶめど)は、アメリカ国立医学図書館の国立生物工学情報センター(NCBI)が運営する医学・生物学分野の学術文献検索サービス(Wikipedia)
まずはイメージしよう
モックアップで書いてみた
イメージをしてみた。Google翻訳に近い感じ。左にPubmed IDを入れるてSearchボタンを押すと,一覧が結果にして現れる。html且つmicrodataも入れられたら素晴らしい。が,まずは単純に書きだすことを考えよう。モックアップ作成ツール -Mockup Designer使い方等の紹介
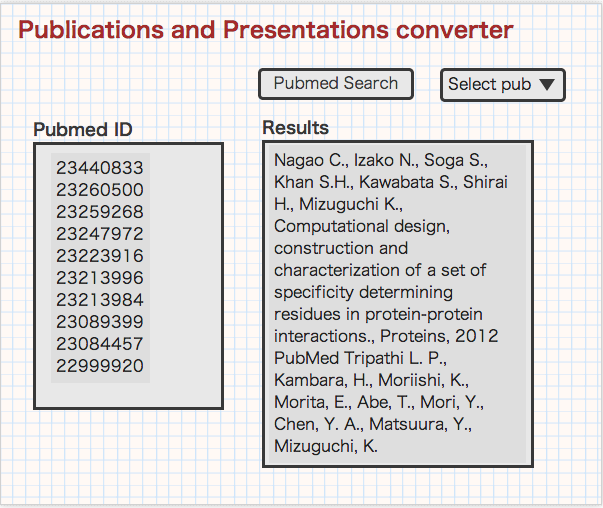
こんな感じで目的のページや何やらにコピペ出来ればいいんじゃない?というかこんなに字は大きくなくて良いのだけど(^_^;)
ちなみに右上のSelect pubからSerect Presentationとかで
入力形式を指定出来れば良いのではないだろうか。
どこからデータを取得しようか
xml形式でデータを取ってこられるって聞いたことがあるぞ。
BioHackathonで
Rare Diseaseグループで関連のプログラムを書いていた時に確かpubmedからxmlでデータを取得したとMさんから聞いたことがあるぞ。
というわけで調べたり,記録を辿ったり(Mさんが書かれたプログラムを見たり)してみた。
どうやらwebAPIで提供されているらしい。
関係ないですが,上のサイトの方が作られたTwitterのグーグルライクアプリBossKitterが面白いです。新規ツイートがもしかしてで表示されるところとかツボ。
さて本題に戻ろう。
これらの紹介にもあった通り,NCBIのURLにアクセスして,
http://eutils.ncbi.nlm.nih.gov/entrez/eutils/esummary.fcgi?db=pubmed&id=22674858,22434880
id=の後にPubmed IDを入れるとxmlを返してくれる。(一部抜粋)
<eSummaryResult>
<script />
<DocSum>
<Id>22674858</Id>
<Item Name="PubDate" Type="Date">2012 Oct</Item>
<Item Name="EPubDate" Type="Date">2012 Jul 10</Item>
<Item Name="Source" Type="String">Proteins</Item>
<Item Name="AuthorList" Type="List">
<Item Name="LastAuthor" Type="String">Mizuguchi K</Item>
<Item Name="Title" Type="String">
Computational design, construction, and characterization of a set of specificity determining residues in protein-protein interactions.
</Item>
<Item Name="Volume" Type="String">80</Item>
<Item Name="Issue" Type="String">10</Item>
<Item Name="Pages" Type="String">2426-36</Item>
<Item Name="LangList" Type="List">
<Item Name="NlmUniqueID" Type="String">8700181</Item>
<Item Name="ISSN" Type="String">0887-3585</Item>
<Item Name="ESSN" Type="String">1097-0134</Item>
<Item Name="PubTypeList" Type="List">
<Item Name="RecordStatus" Type="String">PubMed - in process</Item>
<Item Name="PubStatus" Type="String">ppublish+epublish</Item>
<Item Name="ArticleIds" Type="List">
<Item Name="DOI" Type="String">10.1002/prot.24127</Item>
<Item Name="History" Type="List">
<Item Name="References" Type="List" />
<Item Name="HasAbstract" Type="Integer">1</Item>
<Item Name="PmcRefCount" Type="Integer">0</Item>
<Item Name="FullJournalName" Type="String">Proteins</Item>
<Item Name="ELocationID" Type="String">doi: 10.1002/prot.24127</Item>
<Item Name="SO" Type="String">2012 Oct;80(10):2426-36</Item>
</DocSum>
もしかしたら,もっと良い方法があるかもしれないのだが,とにかく,このxmlを解析すれば,必要なデータを取ってこられるはずだ。
ウェブ上で動かすとなると,どの言語が適切か,よく考えよう。今日はもう帰るので,Qiitaの皆さん,良きアイデアがありましたら,教えてください☆