Amazon Machine Learningを使って、手軽に機械学習を試してみました。
十分な予測の精度がでたとは言いがたいので、参考までにどうぞ。
利用データと目的
データ
・ある商材の2010-2015までの取引データ約4万件
・商材の属性情報は位置情報など含め約20カラム
目的
・先月分までのデータを元にモデルを作成し、今月の取引価格を予測する
Amazon Machine Learningの基本の流れ
DataSoucreとML model作成
ダッシュボードから、「Create new...Data Souce and ML model」を選択し、作成を開始します。
データはS3か、Redshiftから投入することができます。
今回は、DBのダンプからcsvを作成し、webコンソールからS3にアップロードし、データを作成しました。
使用するデータを選択すると、各カラムのデータタイプを選択します。
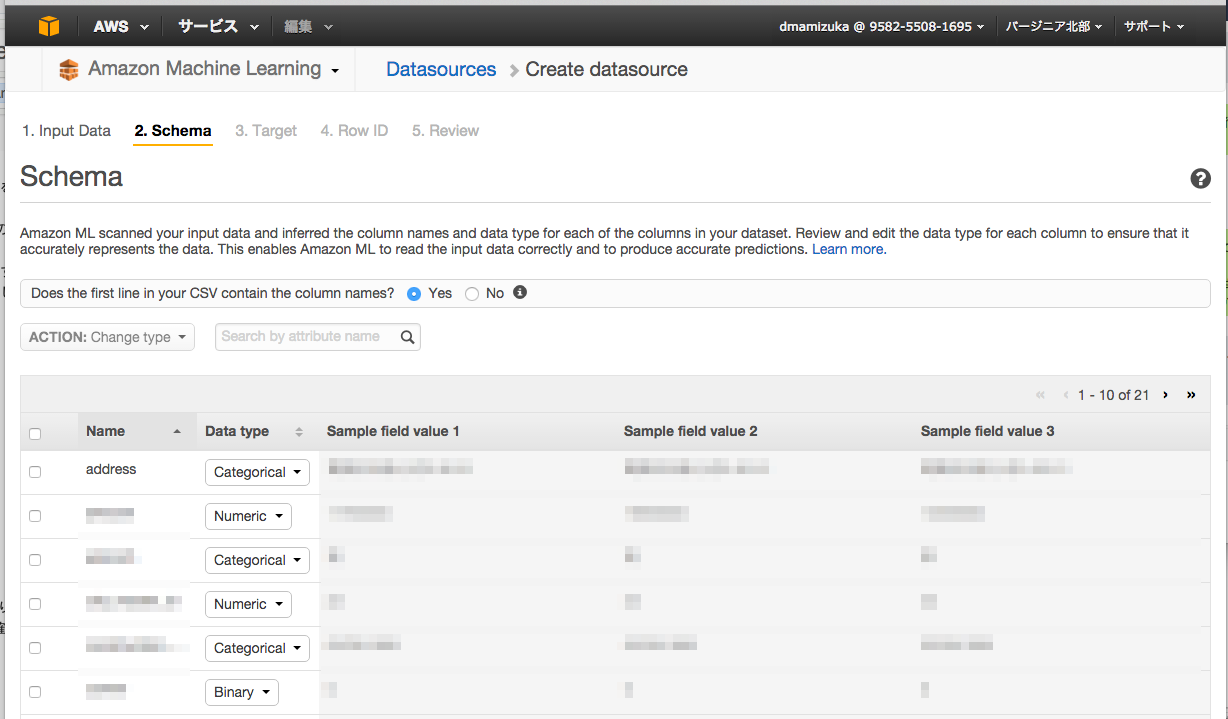
データタイプは
・Binary
・Categorical
・Numeric
・Text
の4種類から選択します
(モデルの精度に関わってくるようです、実際にid値をNumericじゃなくてCategoricalに変更したら精度が上がったりしました。Textがどう使われるかは不明です。。)
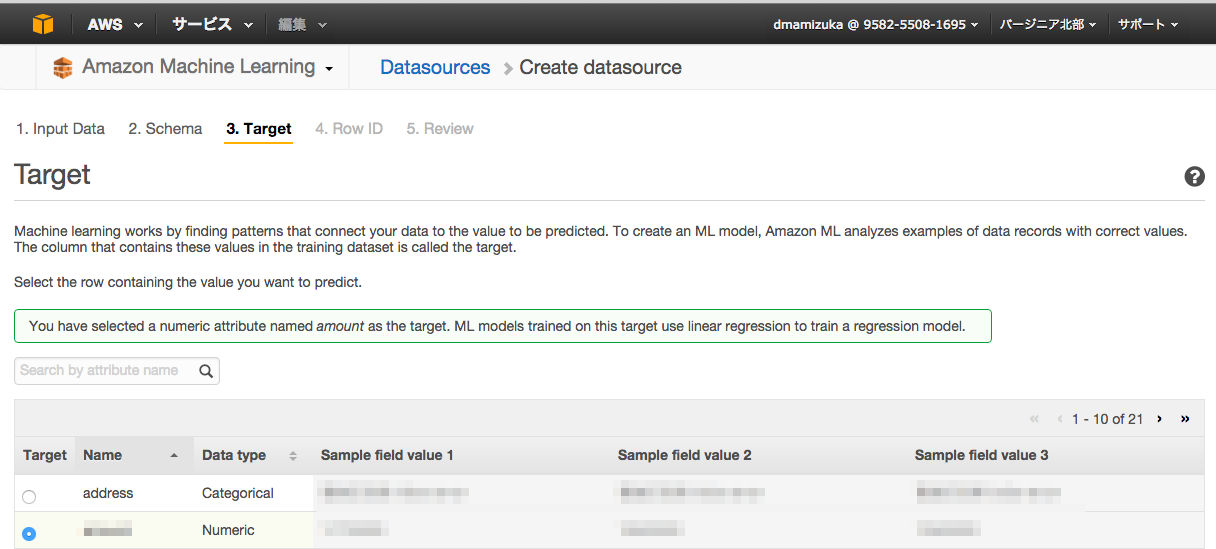
予測をするターゲットを選択すると自動的に利用するアルゴリズムが選択されます。
今回はNumericを予測するので、線形回帰が自動選択されました。
Model作成
投入データのうち何%を学習に使い、何%を評価に使うかなど、Modelの設定をすることができます。defaultの設定を使うという選択肢があったので、今回はdefaultでやってみました。
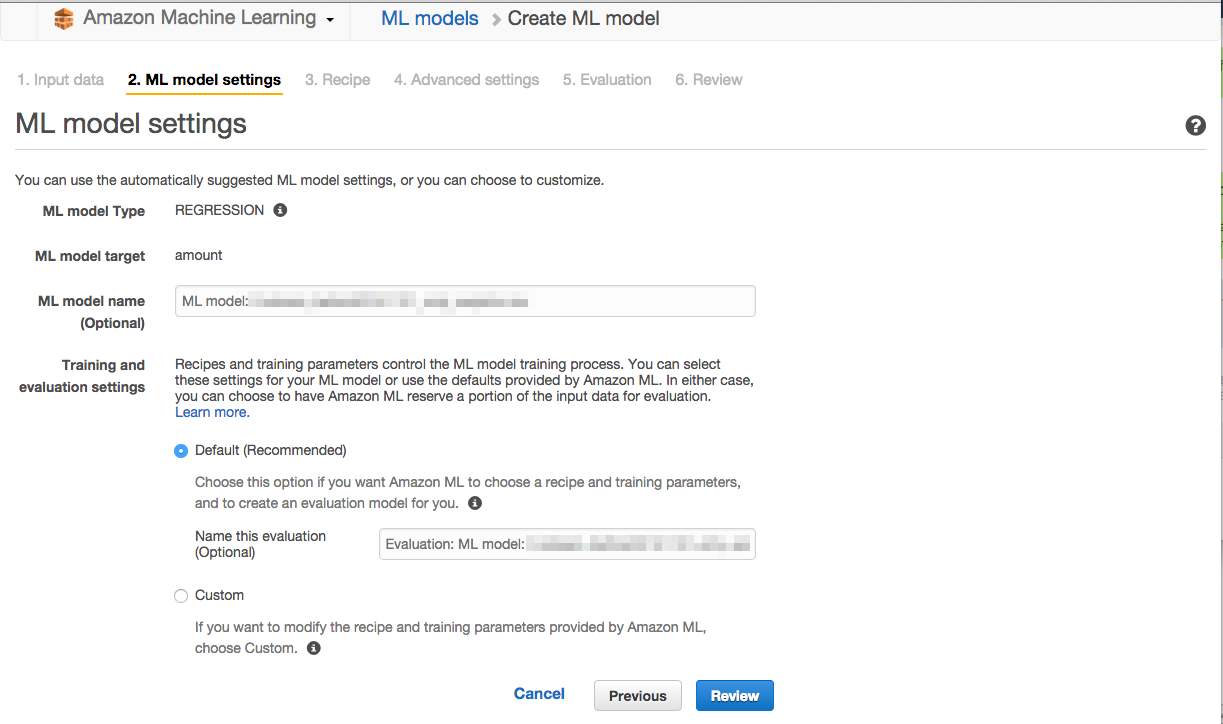
設定がおわると、モデルの作成が始まります。
投入データ量によるのでしょうが、今回は10分ほどで作成が終わりました。
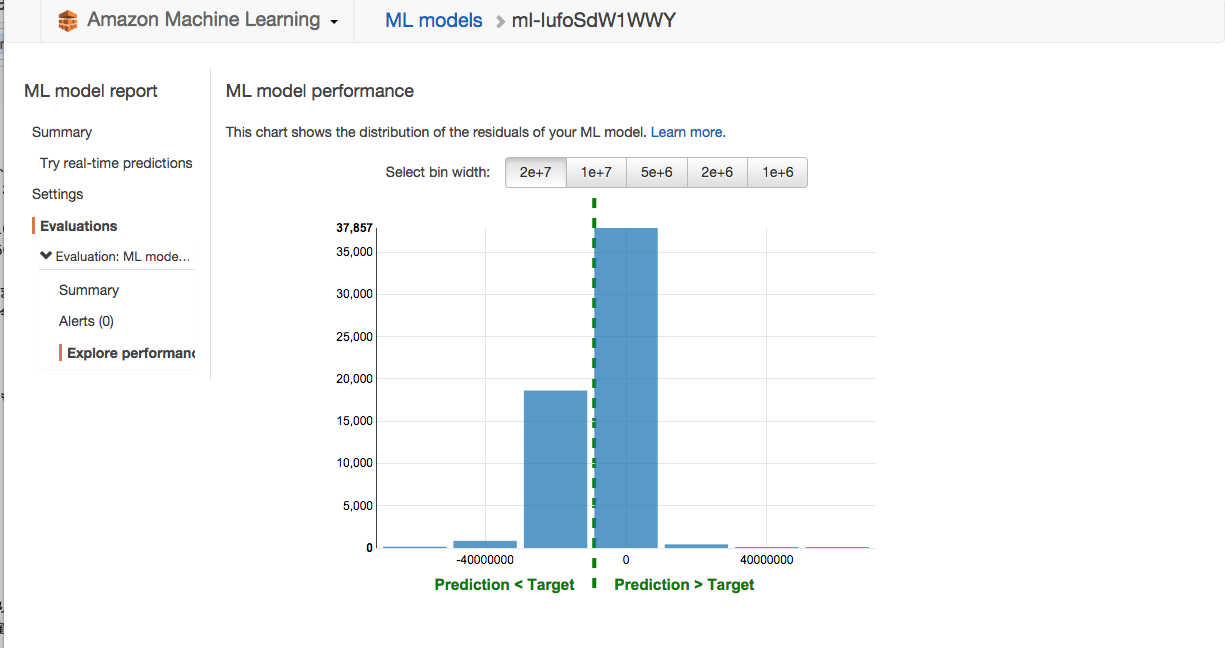
Modelの評価
モデルを作成すると、自動的に評価も実行してくれます。
実際の値からの外れ具合をプロットしてくれます
予測の実行
1データずつ与える方法(リアルタイム予測)と複数データをバッチで処理する方法(バッチ予測)があります。
今回はバッチ予測を使用しました。
バッチ予測は、S3やRedshiftからのデータをもとにDatasourceを作りそれを使用して予測をするという流れになります。
モデルの作成時に使わなかった今月分の取引データ約1000件をバッチで処理し、
価格を予測しました。
結果
実際の取引価格との平均誤差が30%とあまり有用なモデルにはなりませんでした、
一応精度向上に効果があったこととしては、
・DataSource作成時のデータタイプを適切に設定する(id系はnumericじゃなくてclass)
・投入するデータを選定する(取引希望価格が価格予測の参考になるかもと思い、投入してみたことがありましたが、実取引価格のみのほうが精度が高かったです。)
などが有りました。
感想
スクリプトを1行も書かなくていいので、手軽に開始するには良いなと思いました。
下に記載しますが料金も手軽で、とりあえずやってみるのには最適化と思います。
一方でちゃんとした精度を出すためには、そもそもアルゴリズムの選定(Amazon Machine Learnigでは対応していないアルゴリズムが多数あります)やパラメータの設定など手がかかりそうだなと思いました。
(参考)料金
アルゴリズム生成:0.42 USD/時
バッチ予測:予測 1,000 件当たり 0.10 USD
リアルタイム予測:予測 1 件当たり 0.0001 USD
※ご利用の際はAWSの料金説明をご確認ください