自分で小さいツールを作る時に心に留めているtipsです.
書き始めたときは「どうせ書捨てだし」と思って書き始めると意外と長い間,もしくはいろんなところで使うことになったりするので,気をつけておくと後から楽になるというような小技です.大規模なソフトウェアの開発ではまた違った流儀があると思います.
メインルーチンを関数にする
関数名はなんでもいいのですが,自分は趣味で main() という名前の関数を用意し,メインルーチンは全てそこに書くようにしています.
# !/usr/bin/env python
def main():
print('hello, hello, hello!')
if __name__ == '__main__': main()
pythonの小さなサンプルコードを見たりすると関数外の部分にベタで実行コードが書かれていたりします.もちろんそれでも動くのですが,以下の2点で後々面倒になることがあります.
- グローバル変数だらけになり管理が追いつかなくなる:「どうせ小さなスクリプトだし」ではじめると最初は見通しが良くてもだんだんどこでどの変数名を使っているか分からなくなってきます.特に小さいスクリプトだと思って変数名を雑につけていたりするとうっかり同じ変数名を別の目的で使って事故ったりします
- 外部からの読み込みをするときに実行されてしまう:このコードで定義したclassを外でも使いたい,とかなったときに
import文などで外から読み込みをすると関数外の部分は実行されてしまいます.そういった部分をあとからえいやで関数にくるんでも良いのですが,中にはグローバルで実行しておかないといけないような部分(例えば定数としてつかうグローバル変数の定義とか)も一緒にくるんでデバッグに無駄な時間がかかるようになったりしがちです
これを防ぐため,変数などを含む処理を全て main() の中に押し込め,__name__ == '__main__' という条件文をおくことで外部から読み込まれた時にメインルーチンを実行しないようにしています.
virtualenvを使って実行環境を管理する
$ pip install virtualenv
$ virtualenv venv
$ source venv/bin/activate
virtualenvはpythonでも著名な実行環境分離ツールです.virtualenvの使い方はいろいろな方の解説記事があるのでそちらを参照して頂ければですが,自分は小さなツールを作るときでもなるべくvirtualenvを使うようにしています.理由としては概ね以下のとおりです.
- (まれにだが)python2とpython3を行ったり来たりすることがあるので,projectごとに決まったバージョンで動くようにしておきたい
- そのprojectで使っているパッケージがはっきりわかるようにしておく.全体の環境と混ざらないようにしておくことで,
pip freeze > requirements.txtとして仕様パッケージ一覧を保存できるようにしておくと,別環境へ(例えば手元のPCから一晩中分析をまわすサーバへ)移すときにスムーズになる
argparseでパラメータを管理する
書捨てのツールやスクリプトを書く場合,固定の値を渡すために決め打ちの変数を用意することがありますが,これをなるべくargparseを使ってコマンドラインからとってこれるようにしておきます.
# !/usr/bin/env python
import argparse
def main():
# パーサの作成
psr = argparse.ArgumentParser()
# -w / --word というオプションを追加.デフォルトは 'hello! '
psr.add_argument('-w', '--word', default='hello! ')
# -s / --size というオプションを追加,デフォルトは5で型はint
psr.add_argument('-s', '--size', default=5, type=int)
# コマンドラインの引数をパースしてargsに入れる.エラーがあったらexitする
args = psr.parse_args()
print(args.word * args.size)
if __name__ == '__main__': main()
変数を書くのに比べるとちょっとかったるいのは確かですが,一方でちょっとパラメータをいじらないといけなくなったり,データの読み込みをするファイルを変えたり,といった時にコマンドラインの引数で指定できる=コードそのものをいじらなくていいので,試行錯誤するときなどにとても便利です.default に値を指定しておけばいちいち指定しなくてもいいのも楽です.
> python t3.py -s 6
hello! hello! hello! hello! hello! hello!
> python t3.py -s 2
hello! hello!
> python t3.py -w 'hoge '
hoge hoge hoge hoge hoge
tqdmで進捗を表示する
for文で何万回というループをまわして処理待ちをする時,今だいたいどこらへんまで進んだのか?というのを確認したくて思わず if i % 1000 == 0: print('now =', i) みたいなコードを書いてしまったりしますが,そのためのライブラリを使うと簡単かつよりリッチな情報を得ることができます.個人的には tqdm というライブラリを使っています.
# !/usr/bin/env python
from tqdm import tqdm
import time
def main():
for i in tqdm(range(100)):
time.sleep(0.02)
if __name__ == '__main__': main()
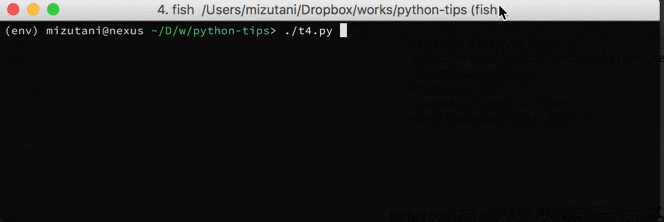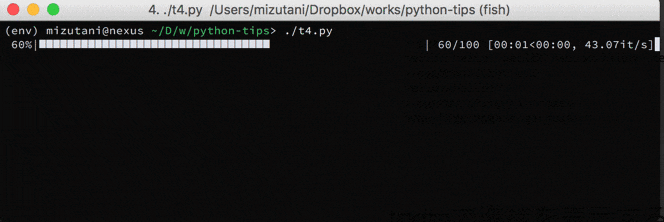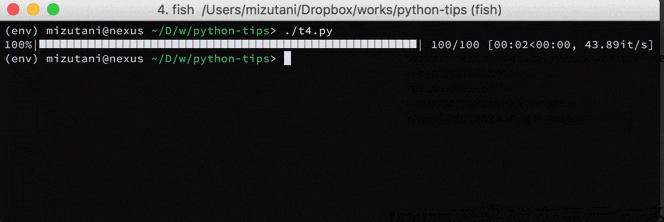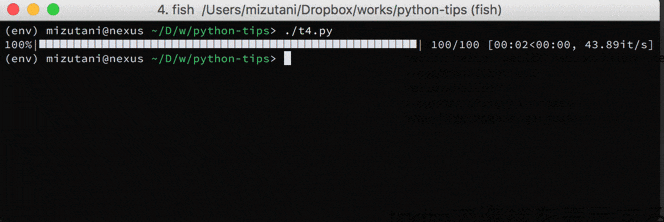
これを使うと今何件ぐらい処理が進んだのか,毎秒どのくらいの件数が処理されているのか,終端が分かる場合は何割ほど処理されたのか,がわかるようになっています.使い方もイテレータを tqdm(iter(...)) というように囲むだけなので,お手軽です.
ログを取る関数を用意する
小さいスクリプトを書く時,処理の途中経過や結果をついついprintで出力してしまいますが,途中で時刻を入れたかったり標準出力への結果が流れてしまったときのためにファイルに書き込んでおきたかったりしてきます.本来は loggingモジュールを使うのが筋かもしれませんが,自分が書くようなスクリプトの場合だと自前で書いてしまった方が速い&小回りが効く場合があるので以下のlog()みたいな関数を用意することが多いです.
# !/usr/bin/env python
import datetime
def log(*args):
msg = ' '.join(map(str, [datetime.datetime.now(), '>'] + list(args)))
print(msg)
with open('log.txt', 'at') as fd: fd.write(msg + '\n')
def main():
log('generated', 5, 'items')
if __name__ == '__main__': main()
$ python t5.py
2017-09-04 12:39:38.894456 > generated 5 items
$ cat log.txt
2017-09-04 12:39:38.894456 > generated 5 items
おわりに
コード内に書くタイプのtipsはまとめたものをgistにはりつけて置きました.
この他に「こういう小技もあるよ!」みたいなのあればぜひ教えてください.