はじめに
この記事は、関西おうちハックのイベントにて試作した入館・入退室管理システムにて(以下の写真参照)、音声を出力するために日本語音声合成(Open JTalk)をRaspberry piで動作させるまでの方法をまとめたものです。

音量の設定
まずはサウンド周りの設定を行います。
音量だけを設定したい場合は、デフォルトで入っているGUIのalsamixerが便利です。
$ alsamixer
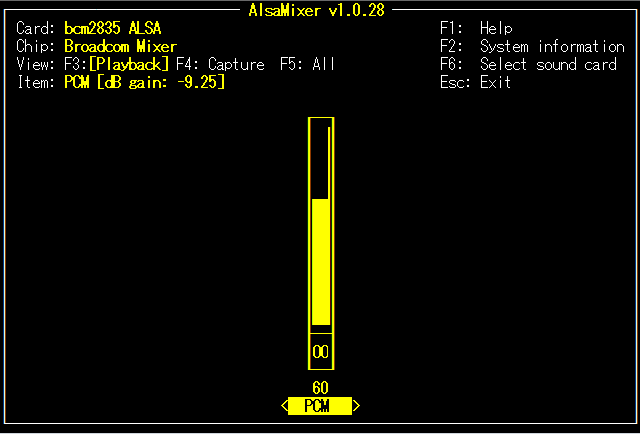
サウンド関係の設定
細かい設定は、amixerを使います。
現在の設定内容
各コントロールのid確認
$ amixer controls
と入力すると以下のような情報が表示されます。
numid=3,iface=MIXER,name='PCM Playback Route'
numid=2,iface=MIXER,name='PCM Playback Switch'
numid=1,iface=MIXER,name='PCM Playback Volume'
numid=5,iface=PCM,name='IEC958 Playback Con Mask'
numid=4,iface=PCM,name='IEC958 Playback Default'
numidはamixerで指定する各コントロールのidとなります。
上記の例ですと、PCM Playback Routeであるnumid=3が実際の出力先のコントロールを示します。
PCM Playback Volumeであるnumid=1は、ボリュームの設定を行うためコントロールのidになります。
以降では、numidは上記の設定であることを前提に記載します。
出力先設定の確認
$ amixer cget numid=3
と入力すると、現在の出力先設定が確認できます。
numid=3,iface=MIXER,name='PCM Playback Route'
; type=INTEGER,access=rw------,values=1,min=0,max=2,step=0
: values=1
現在の出力先設定は、valuesの値から1(アナログ出力)とわかります。
0だと自動、2だとHDMIという意味です。
ボリューム設定の確認
各コントロールの情報取得は、cgetとnumidを指定して行います。
ボリュームのコントロールはnumid=1なので、
$ amixer cget numid=1
と入力すると、現在のボリューム設定が表示されます。
numid=1,iface=MIXER,name='PCM Playback Volume'
; type=INTEGER,access=rw---R--,values=1,min=-10239,max=400,step=0
: values=-925
| dBscale-min=-102.39dB,step=0.01dB,mute=1
上記から、設定できるボリュームの最小値は-10239、最大値は400、現在の値は-925ということがわかります。
設定の変更
コントロールの優先度の設定
$ amixer cset numid=3 1
とすると優先する出力先を1(アナログ)に設定します。
ボリュームの設定
$ amixer cset numid=1 50%
とするとボリュームを50%に設定できます。
設定の保存
再起動時にも設定を保持したい場合は、
$ sudo alsactl store
と入力します。
スピーカーの選定
スピーカーは100均で入手したアンプなしのものと、

小型でアンプ付きのAudio Technica製 AT-SPP30を試してみました。

ボリュームは100%にして試してみました。
結論ですが、100均で入手したアンプなしでは全然音量がたりませんでした。
AT-SPP30は100均よりスピーカーの口径が大きいので100均よりは音量がありますが、やはりアンプなしでは実用には耐えられないと思います。
日本語音声合成システム(Open JTalk)のインストール
日本語音声合成システムは、Open JTalkを使用しました。
Open JTalkのデモはこちらから。
まずは本体のインストール。
$ sudo apt-get install open-jtalk
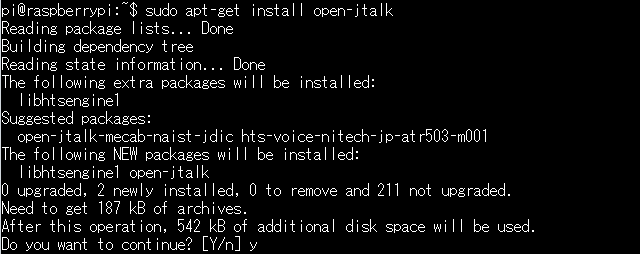
その中で、open-jtalk-mecab-naist-jdicとhts-voice-nitech-jp-atr503-m001が提案パッケージ(Suggested packages)と表示されてます。次にこの2つをインストールします。
$ sudo apt-get install open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001
これで準備は完了です。
Open JTalkを使ってみる
先ほどインストールした、hts-voice-nitech-jp-atr503-m001に含まれる音声nitech-jp-atr503-m001を使って実行してみます。
まず、しゃべらせたい言葉をvoice.txtに書きます。今回は、以下にします。
こんにちは、はじめまして。
その後、コマンドを実行して、音声ファイルを作ります。今回はtest.wavとします。
$ open_jtalk -m /usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice -x /var/lib/mecab/dic/open-jtalk/naist-jdic -ow test.wav voice.txt
成功すると、test.wavというファイルができていますので、
$ aplay test.wav
でちゃんと再生されれば成功です。
毎回、同じコマンドを打つのも面倒なので、こちらを参考にスクリプトを作成いたしました。
※元のスクリプトは古い音声フォーマットのパラメータ指定だったため、そこを変更しています。
# !/bin/sh
TMP=/tmp/jsay.wav
echo "$1" | open_jtalk \
-m /usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice \
-x /var/lib/mecab/dic/open-jtalk/naist-jdic \
-ow $TMP && \
aplay --quiet $TMP
rm -f $TMP
jsay.shに実行権をつけて、
$ chmod 755 jsay.sh
実行すれば再生されます。
$ ./jsay.sh こんにちは
女性の声に変えてみる
nitech_jp_atr503_m001は男性の声ですが、これを女性の声に変えてみます。
まずは、音声ファイルをMMDAgentのサイトから入手します。
現状(2016.4.7)での最新版であるVersion1.6を使用しました。
$ wget http://downloads.sourceforge.net/project/mmdagent/MMDAgent_Example/MMDAgent_Example-1.6/MMDAgent_Example-1.6.zip
その後、ファイルを解凍し、
$ unzip MMDAgent_Example-1.6.zip
その中の、meiフォルダ配下を/usr/share/hts-voice/にコピーします。
$ sudo cp -R ./MMDAgent_Example-1.6/Voice/mei /usr/share/hts-voice/
その後、先ほどのjsay.shの4行目の-mの指定を以下に変更します。
・・・
-m /usr/share/hts-voice/mei/mei_normal.htsvoice \
・・・
先ほどと同様に、jsay.shを実行すれば女性の声が再生されます。
$ ./jsay.sh こんにちは
最後に
この日本語音声合成をつかって、将来的にはRFIDと連携させて、"〇〇さん、いらっしゃいませ”としゃべらせてみたいと思っています。
以上です。