はじめに
Coursera Machine Learningの課題をPythonで: ex3(ロジスティック回帰で手書き数字認識)に触発されて書きました。
昨年scikit-learnにNeural Networkが実装されたこともあり、本記事では、課題ex4をPythonで書いてみます。
ex4の概要
ex4は、ニューラルネットワークを用いて手書き数字を認識するタスク。データセットはex3に引き続きMNISTのサブセットということで、20x20ピクセルのグレースケール画像が5000枚、これがMatlab/Octaveの.matというデータ形式で与えられています。
前編
まずは5000枚の画像を読み込み、ランダムに選ばれた100枚を表示します。
(Coursera Machine Learningの課題をPythonで: ex3(ロジスティック回帰で手書き数字認識)を参考にしました)
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as scio
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
# scipy.io.loadmat()を使ってmatlabデータを読み込み
data = scio.loadmat('ex4data1.mat')
X = data['X'] # X は 5000x400 行列
y = data['y'].ravel() # y は 5000 x 1 行列、ravel()を使って5000次元ベクトルに変換
sel = np.random.randint(0,len(X),100)
fig = plt.figure()
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=None)
for i in range(0,100):
ax = fig.add_subplot(10,10,i+1)
ax.axis('off')
ax.imshow(X[sel[i]].reshape(20,20).T, cmap = plt.get_cmap('gray'))
plt.show()
実行結果はこちら

中編
続いて、以下のように25個のユニットを持つ隠れ層を1層持つニューラルネットワークを実装します。
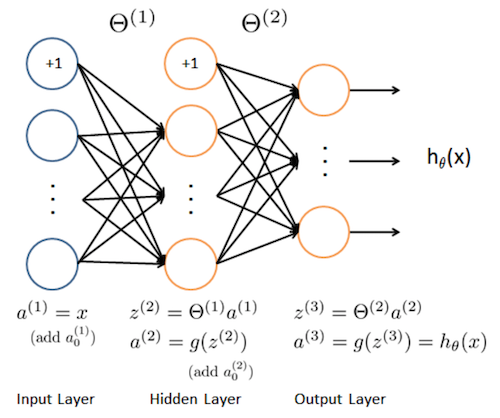
とは言っても、scikit-learnのMLPClassifierを使うだけなのでコードはシンプルです。
#1 hidden units (size 25)
model = MLPClassifier(hidden_layer_sizes=(25, ), solver="sgd",
random_state=0,max_iter=1000,
alpha = 0.0001, tol=1e-9)
model.fit(X, y)
model.score(X, y)
引数は色々取ることができます。詳しくはこちら(公式)。
実行すると、訓練データでの正答率は 0.96579 と表示されました。
Courseraでは伝達関数にシグモイド関数を使っていますが、MLPClassifierではデフォルトだとReLU(ランプ関数)が使われます。
こちらの方が一般的に精度が高いようなので、Courseraの課題とは違いますがReLUを利用しました。もしシグモイド関数を使いたい場合は、activation='logistic'と引数を指定すればOKです。
(因みに上記のコードのままシグモイド関数を使った場合の正答率は 0.91859 となりました。結構下がりましたね。。)
後編
課題の最後に、隠れ層を可視化してみるコーナーがあります。
こちらはCoursera上では宿題ではありませんが、以下、pythonで書いてみます。
fig, axes = plt.subplots(5, 5)
vmin, vmax = model.coefs_[0].min(), model.coefs_[0].max()
for coef, ax in zip(model.coefs_[0].T, axes.ravel()):
ax.matshow(coef.reshape(20, 20), cmap=plt.cm.gray, vmin=.5 * vmin,
vmax=.5 * vmax)
ax.set_xticks(())
ax.set_yticks(())
plt.show()
隠れ層を見るには、学習後のcoefにアクセスすればOKです。
隠れ層の全てのユニットを同じスケールで可視化するために、vminとvmaxにmodel.coefs_[0]の最小値と最大値をセットしました。
実行結果はこちら

ほとんど使われていないユニットもあることがわかります。
おまけ
また、Coursera Machine Learningの課題をPythonで: ex3(ロジスティック回帰で手書き数字認識)から認識を間違えたデータを表示するコードもお借りして、表示してみました。
wrong_index = np.array(np.nonzero(np.array([model.predict(X) != y]).ravel())).ravel()
wrong_sample_index = np.random.randint(0,len(wrong_index),25)
fig = plt.figure()
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.5, hspace=0.5)
for i in range(0,25):
ax = fig.add_subplot(5,5,i+1)
ax.axis('off')
ax.imshow(X[wrong_index[wrong_sample_index[i]]].reshape(20,20).T, cmap = plt.get_cmap('gray'))
ax.set_title(str(model.predict(X[wrong_index[wrong_sample_index[i]]].reshape(1,-1))[0]))
plt.show()
※ ax.set_title部分のみ、scikit-learnのバージョン0.18に対応して少しだけ書き換えました。具体的には、1次元配列を渡すことが奨励されないようになったことを受け、サンプルデータをreshape(1, -1)とreshapeしました。
実行結果はこちら

人間が見てもけっこう惜しいものがあって、面白いです。
しかしチューニングが必要ですね。