この記事は言語実装 Advent Calendar 2016の19日目の記事です。
以前からLLVMに興味があり、機会1が出来たのでLLVMをやってみた(というより使ってみた)記録です。
自分はコンパイラ・言語処理系に関してはほぼ素人でありここに書いてあることが間違っているかもしれないのでツッコんでいただけるとありがたいです。
また、他のIR(中間言語)を知らないので言語仕様的に.NETやJVMとの比較はせずあくまで自分がLLVMを見た時に感じたことを書いていきます。
対象読者
- 言語処理系の基礎は知っている
- プログラムがどうコンパイル、実行されるか
- アセンブリ言語の基礎を知っている
- 例えばfor文がどうやってアセンブリ言語で実現されているか
- C++が読める
- そんなに高度な機能は使っていない気がする(筆者自身C++チョットデキル程度)ので知らなくてもなんとかなると思います
LLVMとは
公式ページを見る限りだと「モジュール化されており再利用可能なコンパイラ、及びツールチェイン技術」と言ったところでしょうか。これだとざっくりしているので具体的に書くと
- C, C++, Objective-C等のフロントエンド
- LLVM命令の実装(アセンブリとバイトコードのリーダ、ライタ、ベリファイア)
- コードジェネレータ(アセンブラ?)
- JITコンパイラ
- LLVMコンポーネントを作成するためのAPI
こんな感じでしょうか。これらのツールを使ってソースコードを以下のように実行形式に変換していきます(以下はClangの例です)。
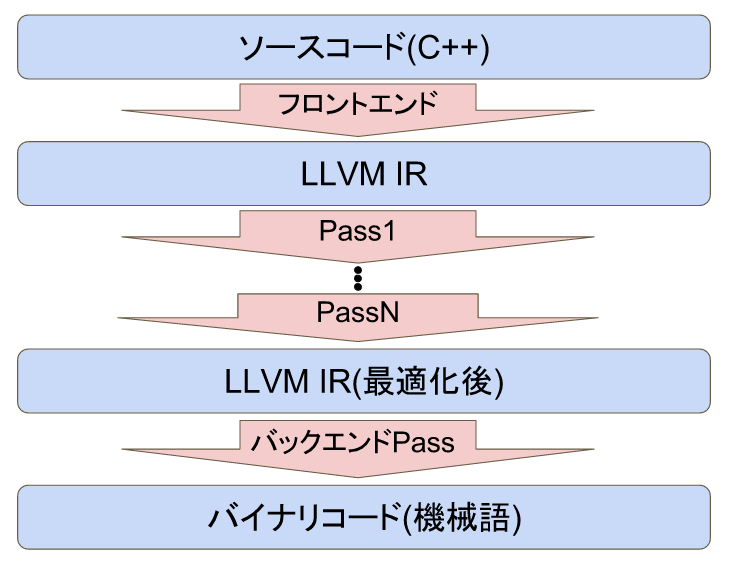
メリットとしては
- LLVM IRで吐けば最適化してくれる
- ライセンスがBSDライク
- いろいろなアーキテクチャに対応
といったところです。LLVMを採用している処理系はRust, Clang, LDC等の割とモダンな言語が多いという印象です。
ここでLLVM IRとは中間言語の一種で機械語とは異なります。この中間言語を介することで様々なアークテクチャに対応できるということです。
今回は上の図の「フロントエンド」を作成してみました2。
【Brainf*ckコンパイラ】作ってみた。
まず、手始めにBrainf*ckコンパイラを作ってみました。とは言いつつもいきなりは作れないので以下の資料を見ながら概要を把握しました。
- http://llvm.org/docs/LangRef.html
- きつねさんでもわかるLLVM 柏木 餅子, 風薬
ここからわかったことは
- 型の概念がある
- 整数、浮動小数点、ベクタ、配列など
- 長さが異なる整数は直接相互的に使うことが出来ない(変換命令は存在する)
- SSA形式である
- 詳しくはWikipediaを見て欲しいのですが(自分はあまり理解していないです)、あらゆる変数が一度のみ代入される(上書きされない)ように書かれた形式です。最適化がしやすくなるという利点があるようです。
- これ用(?)に
phi命令がある
- 変数はスタックから割り当てる(
alloca)ことで確保する- ロード(
load)、ストア(store)はallocaで返ってきたポインタ経由で行う
- ロード(
- 比較命令、ジャンプ命令、四則演算、ビット演算等は普通にある
だいたいわかった(気になった)ところで早速作っていきます。自分はUbuntuを使っているのでapt install llvmでLLVM(ツール、API)をインストールできました。
次にここを参考にまずはHello Worldを出力するプログラムを作成しました。コンパイルは以下のコマンドで出来ます。
g++ main.cpp `llvm-config --cxxflags --ldflags --libs` -ldl -lpthread -ltinfo -fexceptions -o main
ここからBrainf*ckをコンパイルできるようにしていきます。まず、Brainf*ck処理系は30000個のバイト(i8)配列とデータポインタを状態として持つのでこれらを確保します。CreateAllocaはC言語のalloca関数のようにスタックから領域を確保する命令を生成する関数です3。CreateStoreは言わずもがなポインタが指し示す先に値をストアする命令を生成する関数です。以降、特に補足がなければ関数についての解説はしないので適当に調べて欲しいです。
// i8 * MEMORY_SIZEの領域確保
memory = builder.CreateAlloca(builder.getInt8Ty(), builder.getInt32(MEMORY_SIZE), "memory");
// ポインタ領域確保
current_index_ptr = builder.CreateAlloca(builder.getInt32Ty(), nullptr, "pointer_ptr");
// *pointer_ptr = 0
builder.CreateStore(builder.getInt32(0), current_index_ptr);
次に各命令について淡々と実装していきます。仕様通りに実装すればよく特に説明することがないのでここを見てもらえれば分かるはずです(工夫したところは連続している+, -をまとめているくらい)。
ここではBrainf*ck最大の難関であろう[, ]の解説をしていきます。
case '[': {
// while labelを作成(`[`)に相当
auto *whileBB = llvm::BasicBlock::Create(context, "while", mainFunc);
// whileに分岐
// LLVMではブロックの最後は終端命令(`ret`, `br`等)でなければならないので
builder.CreateBr(whileBB);
// 命令を挿入する場所をwhileBBにする
builder.SetInsertPoint(whileBB);
// 現在のポインタの指し示す先の値が0でないか
auto valptr = createGetCurrent();
auto *cond = builder.CreateICmpNE(std::get<0>(valptr), builder.getInt8(0));
// then, mergeブロックを作成
auto *thenBB = llvm::BasicBlock::Create(context, "then", mainFunc);
// ここでmainFuncがないのは`[`, `]`が入れ子になる可能性があるのでこの時点ではmergeを挿入できない
auto *mergeBB = llvm::BasicBlock::Create(context, "merge");
// 0だったらthen, そうでなければmergeに分岐
builder.CreateCondBr(cond, thenBB, mergeBB);
builder.SetInsertPoint(thenBB);
// `]`用にwhile, mergeを取っておく
loop_stack.push(BBPair(whileBB, mergeBB));
break;
}
こんなところでしょうか。注意すべきところはmergeブロックを作成する時点ではmainFuncに追加しないというところでしょうか。この辺りは生成されるIRを考えると解ると思います。スタックを使用する辺りはBrainf*ckインタプリタと同じなので割愛します。
case ']': {
if (loop_stack.size() == 0) {
throw "no '[' corresponding ']'";
}
// 対応する`[`に分岐
auto pair = loop_stack.top();
loop_stack.pop();
builder.CreateBr(std::get<0>(pair));
// mergeブロックを挿入する
auto mergeBB = std::get<1>(pair);
mainFunc->getBasicBlockList().push_back(mergeBB);
builder.SetInsertPoint(mergeBB);
break;
}
参考までに++++++[>++++++<-]>.($を出力するプログラム)のコンパイル結果のコントロールフロー図(CFG)を掲載します。このCFGは手で書いたのではなく、LLVM APIのCFGを出力する機能を利用しました。CFGにしたい関数->viewCFG()を書くだけでdotファイルを生成してビューアを開いてくれます4。
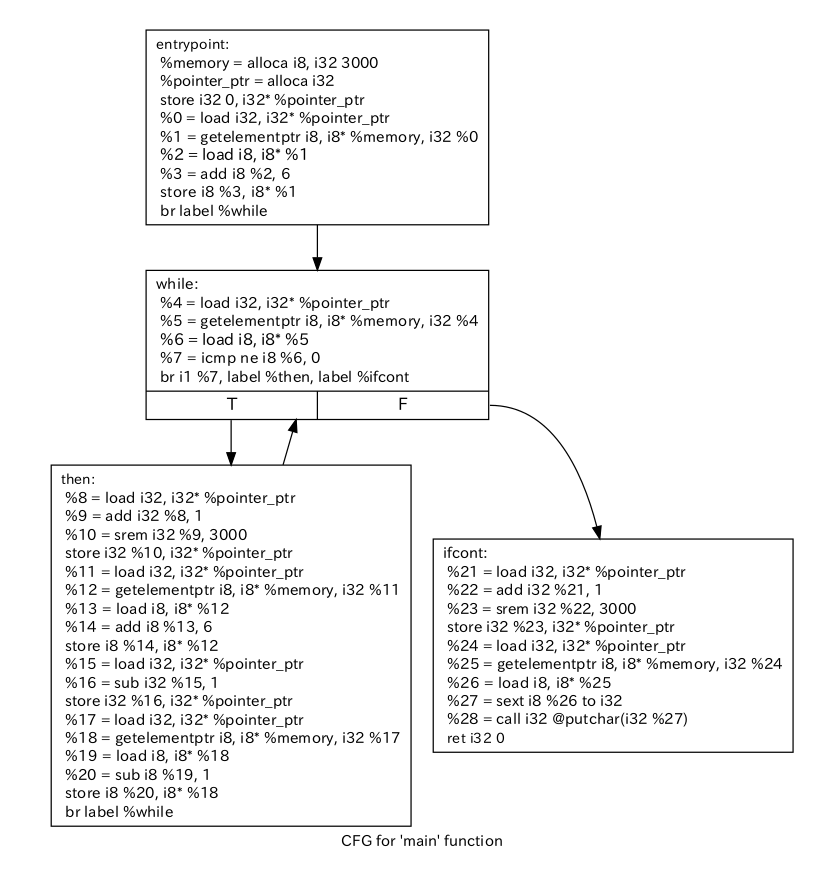
ここまで出来たら後はビットコード(LLVM IRのバイナリ表現)を生成すれば完成です。
std::error_code error_info;
llvm::raw_fd_ostream os("a.bc", error_info, llvm::sys::fs::OpenFlags::F_None);
llvm::WriteBitcodeToFile(bfc.getModule(), os);
参考にしたページではこの後に最適化をしていたのですが自分が作ったコンパイラが生成したコードを最適化をすると結果が変わってしまいました。要調査ですね…
また、せっかくなのでEmscriptenでJavaScriptにも変換してみました。EmscriptenとはC/C++等から生成されるLLVMビットコード(IR)からJavaScriptに変換するトランスレータです。主にC++等で書かれたライブラリをJavaScriptで動かす用途に使われるのですが、今回は先程のBrainf*ckコンパイラが生成したIRをJavaScriptに変換してみます。
以下のコマンドで変換できます($HOMEにSDKをインストールしたと仮定)。
$ ./bfc hello.bf # LLVM IRを生成(a.bc)
$ ~/emsdk_portable/emscripten/master/emcc a.bc # LLVM IRからJSに変換
$ node a.out.js
Hello, world!
$ ~/emsdk_portable/emscripten/master/emcc a.bc -o hello.html # HTMLに変換
【似非LISPコンパイラ】作ってみた。
Brainf*ckだけだと面白くないので、LISPコンパイラを作ってみました。とは言ってもSchemeやCommon Lispほど高機能ではないです。
-
print,cond,progn,defun等の基本的な関数は揃っている - 型は整数、文字列、整数のリスト5のみ
- 無名関数はない
- 型推論(型チェック)はない5
-
defun、cond、setqに型を指定する
-
- マクロはない
- GCはない
と、このようにないないづくしですがお許しください6。
さて、コンパイラを作成するにあたって字句、構文解析をする必要があるのですがこの記事では割愛させていただきます。また、意味解析(ここでは型チェックや識別子の解決)もコード生成時に行うので省略します。
コード生成するにあたってまず、main関数を作成します。
auto *funcType = llvm::FunctionType::get(builder.getInt32Ty(), false);
current_func = mainFunc = llvm::Function::Create(funcType, llvm::Function::ExternalLinkage, "main", module);
main_entry = llvm::BasicBlock::Create(context, "entrypoint", mainFunc);
builder.SetInsertPoint(main_entry);
ここでcurrent_funcも設定しておきます。これはif式などでブロックを追加するのに必要になります。
次に生成したコード側で使用する構造体、関数の定義を登録します。
// consセルの定義
// C言語で書くとこうなる
// typedef struct _ilist {
// int32_t car;
// struct _ilist *cdr;
// } ilist;
auto struct_type = llvm::StructType::create(context, "ilist");
std::vector<llvm::Type*> members {
builder.getInt32Ty(),
llvm::PointerType::getUnqual(struct_type),
};
struct_type->setBody(members);
ilist_ptr_type = llvm::PointerType::getUnqual(struct_type);
// 関数の定義を追加
// int puts(char*)
std::vector<llvm::Type*> putsArgs { builder.getInt8PtrTy() };
putsFunc = define_function("puts", putsArgs, builder.getInt32Ty());
// 以下同様
最後に環境(変数名と値(LLVM::Value*)がstd::mapで保持されています)を初期化します。
root_env = cur_env = new Environment();
これで準備が終わりました。いよいよコード生成に入ります。
void Compiler::compile(std::vector<Object*> &ast) {
for (auto &object : ast) {
compile_expr(object);
}
// 終了コード0を返す(return 0;)
builder.CreateRet(builder.getInt32(0));
}
llvm::Value* Compiler::compile_expr(Object* obj) {
std::type_info const & id = typeid(*obj);
// objがCons型だったら
if(id == typeid(Cons)) {
auto list = (Cons*)obj;
// listの0番目がSymbolのインスタンスであると決めつけてキャスト(Symbolでなかったら例外が飛ぶ)
auto name = regard<Symbol>(list->get(0))->value;
if(name == "print") {
// 引数も同様にコード生成する
auto str = compile_expr(list->get(1));
builder.CreateCall(putsFunc, str);
return str;
}
// こんな感じのコードが続く…
上のコード片から分かる通りLISPの式を再帰でたどってコード生成していきます(Visitorパターンではありません…)。上で型チェックはしないと書いたのですが型が不定だとコード生成できないのでregard<...>によって強制的に型を変換しています。ここで話が脱線するのですが、型変換についてLLVMではそれ用の関数が用意されていて自分が参考にしたきつね本でも使っていたのですが、このコンパイラは以前に作成したLISPインタプリタを流用しており今更それ用に修正するのは面倒だったのでLLVMのキャストは無視しています。現時点ではこれでも全く困っていないので恐らく使わなくても問題無いような気がします。詳しくは http://llvm.org/docs/ProgrammersManual.html#the-isa-cast-and-dyn-cast-templates をご覧ください。
ここで聡明な方はお気づきかもしれませんが上のコードではprintの引数の型について何も触れてないです。つまり本来は文字列を要求しているのに整数を渡すことができてしまいます。型チェックをしていないことによってこのような不具合(?)が出てきます。実際はアセンブル(ターゲットコード生成)時に型のエラーが出るので実際に動くことはないのですが、実用的なコンパイラを作成するならば型チェックはすべきです。
大枠の解説は終えたので、個々の機能をどう実現しているかを解説していきます。
組み込み関数
組み込み関数とはユーザが定義する関数とは違い、予め用意されている関数のことです。このコンパイラでは文字列を出力するprintや整数を出力するprintnなどがあります7。これらを1から実装するのは流石に阿呆らしいのでlibcのものを利用します。これらの定義は先ほど行いました。コード生成時にはその関数を呼び出す命令を生成します。
if(name == "print") {
auto str = compile_expr(list->get(1));
builder.CreateCall(putsFunc, str);
return str;
}
else if(name == "printn") {
auto num = compile_expr(list->get(1));
builder.CreateCall(printnFunc, num);
return num;
}
printnなんてlibcにねーぞ、と思われたかもしれませんがputs以外はlib.c(紛らわしくてすみません)に関数を書いてClangでLLVM IRを生成してからリンクしています。なにかずるいような感じがしますが楽できるところは楽した方が良いですよね?
typedef struct _ilist {
int32_t car;
struct _ilist *cdr; // cdrがNULLだったらnilとして扱う
} ilist;
void printn(int n) {
printf("%d\n", n);
}
void printl(ilist *xs) {
printf("(");
for (ilist *cur = xs; cur->cdr; cur = cur->cdr) {
printf("%d", cur->car);
if (cur->cdr->cdr) {
printf(" ");
}
}
printf(")\n");
}
ilist* cons(int32_t car, ilist *cdr) {
// TODO: fix memory leak
ilist *list = malloc(sizeof(ilist));
list->car = car;
list->cdr = cdr;
return list;
}
ところで、cons関数に// TODO: fix memory leakという不穏なコメントがありますがこれはmallocしたメモリ領域を開放していないのでメモリリークが起こってしまいます。これはGC(Garbage Collection: 要らなくなったメモリ領域(=ゴミ)を自動的に開放する機構)を実装することで解決できるのですがそこまで勉強が進んでないので今回は割愛させていただきます。
上のコードにあるilistもlib.cで定義されています。compiler.cppで定義されているものと重複してしまうのですが変更なんて無いだろうということで妥協しています。スマートに共有できる知見をお持ちの方はご教授していただきたいです…
setq
setqは変数を定義するための特殊形式です。3番目の引数を評価(コード生成)した後、領域を確保、格納しています。LLVM IRはSSA形式なのでcompile_exprの返り値をvalに代入してそれをそのまま他の命令の引数に使えます。このあたりはBrainf*ckコンパイラと同じですね。
else if(name == "setq") {
auto val = compile_expr(list->get(3));
// 変数名は評価しない
auto val_name = regard<Symbol>(list->get(2))->value;
// 型を得る
auto type = get_llvm_type(regard<Symbol>(list->get(1)));
// 領域を確保し、値を格納
auto var_pointer = builder.CreateAlloca(type, nullptr, val_name);
builder.CreateStore(val, var_pointer);
// 現在の環境に登録する
cur_env->set(val_name, var_pointer);
return val;
}
あと何気にreturn val;としていますが、こうすることでsetqした値をそのまま他の引数に使えたりします。C言語で言う、a = b = 1のようなものです。例えば以下はLISPプログラムとそれをコンパイルした結果です8。
(setq int a 1)
(setq int b (setq int c (+ a 1)))
(printn b)
(printn c)
define i32 @main() {
entrypoint:
%a = alloca i32
store i32 1, i32* %a
%0 = load i32, i32* %a
%1 = add i32 %0, 1
%c = alloca i32
store i32 %1, i32* %c ; (setq int c (+ a 1))
; (+ a 1)の結果である%1が使われている
%b = alloca i32
store i32 %1, i32* %b ; (setq int b ...)
; 同じく%1が使われている
%2 = load i32, i32* %b
call void @printn(i32 %2)
%3 = load i32, i32* %c
call void @printn(i32 %3)
ret i32 0
}
LLVMの命令は一部の除き返り値(という言い方でいいのかな?)を持ち、それを生成する関数も値をラップしたクラスであるLLVM::Value*を返すのでcompile_exprでそれをそのまま返せば、上手い具合に値を取り回すことができます。このあたりの仕様のおかげでコンパイラが作りやすかったです(中間言語ではあたり前かもしれませんが)。他の機能についても同様に値を返しています。
defun
defunは関数を定義する特殊形式です。これはLISPコードと生成コードを見ていただければどういうものか理解いただけると思います。
(defun twice (x) (int) int (+ x x))
(printn (twice 1))
define i32 @main() {
entrypoint:
%0 = call i32 @twice(i32 1)
call void @printn(i32 %0)
ret i32 0
}
define i32 @twice(i32 %x) {
entrypoint:
%x1 = alloca i32
store i32 %x, i32* %x1
%0 = load i32, i32* %x1
%1 = load i32, i32* %x1
%2 = add i32 %0, %1
ret i32 %2
}
生成コードは割と素直な感じで読みやすいと思います。
else if(name == "defun") {
auto func_name = regard<Symbol>(list->get(1))->value;
auto args = regard<Cons>(list->get(2));
auto arg_types = regard<Cons>(list->get(3));
auto ret_type = regard<Symbol>(list->get(4));
auto body = regard<Cons>(list->tail(5));
std::vector<llvm::Type*> llvm_args;
// 各型引数についてLLVM::Type*に変換して...
EACH_CONS(arg_type, arg_types) {
llvm_args.push_back(get_llvm_type(regard<Symbol>(arg_type->get(0))));
}
llvm::ArrayRef<llvm::Type*> llvm_args_ref(llvm_args);
auto func_type = llvm::FunctionType::get(get_llvm_type(ret_type), llvm_args_ref, false);
// 関数を作成
auto func = llvm::Function::Create(func_type, llvm::Function::ExternalLinkage, func_name, module);
Environment *env = new Environment();
// 各引数に名前をつける
auto arg_itr = func->arg_begin();
EACH_CONS(arg, args) {
auto arg_name = regard<Symbol>(arg->get(0))->value;
arg_itr->setName(arg_name);
arg_itr++;
}
cur_env->set(func_name, func);
cur_env = cur_env->down_env(env);
// エントリーポイントを作成し、insert pointを対象の関数に設定
auto entry = llvm::BasicBlock::Create(context, "entrypoint", func);
builder.SetInsertPoint(entry);
// 各引数について関数内で使えるように新しくstoreする
// なぜこんな意味不明なことをしているかというとvs_table.lookupで取った値が何故かallocaと同じように使えなかったからです。
// きつね本を探しても無かった… これも知っている人は教えて欲しいです…
auto &vs_table = func->getValueSymbolTable();
auto arg_type = arg_types;
EACH_CONS(arg, args) {
auto arg_name = regard<Symbol>(arg->get(0))->value;
auto alloca = builder.CreateAlloca(get_llvm_type(regard<Symbol>(arg_type->get(0))), 0, arg_name);
builder.CreateStore(vs_table.lookup(arg_name), alloca);
env->set(arg_name, alloca);
arg_type = (Cons*)arg_type->cdr;
}
auto prev_func = current_func;
current_func = func;
// 関数の中身をコード生成し、その結果をret
auto result = compile_exprs(body);
builder.CreateRet(result);
current_func = prev_func;
cur_env = cur_env->up_env();
// insert pointをmain関数に戻す
builder.SetInsertPoint(main_entry);
}
概略を説明すると、
- 関数の定義を作成(最初にやったようなことです)
- 引数名を設定
- insert pointを設定
- 各引数について関数内で使えるように新しくstoreする
- コメントにも書いたのですが、
vs_table.lookupでとった値をallocaでとった値と同じように使おうとするとクラッシュしてしまいます(気がする)。
- コメントにも書いたのですが、
- 関数の中身のコード生成
-
compile_exprsは各式についてcompile_expr呼んでいるだけです
-
演算子(+や=)
これは説明するまでもなく整数同士の演算です。
else if(name == "+") {
auto n1 = compile_expr(list->get(1));
auto n2 = compile_expr(list->get(2));
return builder.CreateAdd(n1, n2);
}
// 同じようなコードなので略
else if(name == "=") {
auto n1 = compile_expr(list->get(1));
auto n2 = compile_expr(list->get(2));
return builder.CreateICmpEQ(n1, n2);
}
本当にそのままなので特に解説することはないのですが、比較だけ、アセンブリの感覚だと比較した結果はフラグレジスタに格納されるのですが、LLVM IRでは他と同じように比較結果が返り値(i1: 1bitの整数、つまり真偽値)になります。br命令はこの結果を引数に取ります。
progn
1つの式しか置けないところに複数の式を置くのに使う特殊形式です。compile_exprsを呼ぶだけです。
cond
condは条件分岐を実現するための特殊形式です。C言語のif..else if..elseに相当します。condを使用したLISPコードとそのコンパイル結果を下記に掲載します。
(setq int a 2)
(print (cond string
((= a 0) "zero")
((= a 1) "one")
((= a 2) "two")
("other")))
@0 = private unnamed_addr constant [5 x i8] c"zero\00"
@1 = private unnamed_addr constant [4 x i8] c"one\00"
@2 = private unnamed_addr constant [4 x i8] c"two\00"
@3 = private unnamed_addr constant [6 x i8] c"other\00"
define i32 @main() {
entrypoint:
%a = alloca i32
store i32 2, i32* %a
%0 = load i32, i32* %a
%1 = icmp eq i32 %0, 0
br i1 %1, label %then, label %else
then: ; preds = %entrypoint
br label %endcond
else: ; preds = %entrypoint
%2 = load i32, i32* %a
%3 = icmp eq i32 %2, 1
br i1 %3, label %then1, label %else2
then1: ; preds = %else
br label %endcond
else2: ; preds = %else
%4 = load i32, i32* %a
%5 = icmp eq i32 %4, 2
br i1 %5, label %then3, label %else4
then3: ; preds = %else2
br label %endcond
else4: ; preds = %else2
br label %endcond
endcond: ; preds = %else4, %then3, %then1, %then
%condtmp = phi i8* [ getelementptr inbounds ([5 x i8], [5 x i8]* @0, i32 0, i32 0), %then ], [ getelementptr inbounds ([4 x i8], [4 x i8]* @1, i32 0, i32 0), %then1 ],
[ getelementptr inbounds ([4 x i8], [4 x i8]* @2, i32 0, i32 0), %then3 ], [ getelementptr inbounds ([6 x i8], [6 x i8]* @3, i32 0, i32 0), %else4 ]
%6 = call i32 @puts(i8* %condtmp)
ret i32 0
}
上のコードに対応するCFGを下記に掲載します。

次にcondに対してどうコード生成したかを解説します。
else if(name == "cond") {
auto ret_type = regard<Symbol>(list->get(1));
using BB_Value = std::pair<llvm::BasicBlock*, llvm::Value*>;
// elseのブロックと値を保持する
BB_Value elseBB;
auto mergeBB = llvm::BasicBlock::Create(module->getContext(), "endcond");
std::vector<BB_Value> thenBBs;
EACH_CONS(val, list->tail(2)) {
auto cond_expr_pair = regard<Cons>(val->get(0));
// 余りもの
if (cond_expr_pair->size() == 1) { // else
// 返り値にするためにelseBBにセットする
elseBB.second = compile_expr(cond_expr_pair->get(0));
// endcondにジャンプ
builder.CreateBr(mergeBB);
break;
} else { // then
auto cond = compile_expr(cond_expr_pair->get(0));
auto thenBB = llvm::BasicBlock::Create(module->getContext(), "then");
auto _elseBB = llvm::BasicBlock::Create(module->getContext(), "else");
// 一番最後のelseブロックを保持
elseBB.first = _elseBB;
// condが1(true)だったらthenにジャンプ
builder.CreateCondBr(cond, thenBB, _elseBB);
// thenブロックを挿入
current_func->getBasicBlockList().push_back(thenBB);
builder.SetInsertPoint(thenBB);
// thenの式を処理
auto thenValue = compile_expr(cond_expr_pair->get(1));
// phi命令用にこの時点での最後のブロックを取得し、thenBBsに値とともに追加 <--------- (a)
auto lastThenBB = builder.GetInsertBlock();
thenBBs.push_back(BB_Value(lastThenBB, thenValue));
// endcondにジャンプ
builder.CreateBr(mergeBB);
// elseのブロックはこのタイミングで追加する
current_func->getBasicBlockList().push_back(_elseBB);
builder.SetInsertPoint(_elseBB);
}
}
// endcondブロックを追加
current_func->getBasicBlockList().push_back(mergeBB);
builder.SetInsertPoint(mergeBB);
// phi命令を生成
auto phi = builder.CreatePHI(get_llvm_type(ret_type), 2, "condtmp");
for (auto thenBB : thenBBs) {
// 今までのthen節の最後のブロックと値を追加
phi->addIncoming(thenBB.second, thenBB.first);
}
// 最後にelseBBのブロックと値を追加
phi->addIncoming(elseBB.second, elseBB.first);
// これを返すことによってcondが式として値を持つようになる
return phi;
}
…
文章で説明できる自信がなかったのでコメントで説明しました。
ここで初めて出るphi命令は、SSAのφ関数を実現するためのものです。と言ってもよくわからないと思いますが(自分も完全には理解してないです)、誤解を恐れずに言うと分岐したブロックが持つ単一の値(condの返り値)をまとめる命令でしょうか。例えば上のCFGの一番下の箱でphi命令を使っていますが、その引数である[ getelementptr inbounds ([5 x i8], [5 x i8]* @0, i32 0, i32 0), %then ]でまとめるブロック(%then)と値(@0)を指定しています。また、すでにお気づきかもしれませんがphi命令がある箱に繋がれている矢印はその引数に対応しています。
プログラム中の(a)について、lastThenBBはthenBBではいけないのかと思われるかもしれません。確かにcondがネストしていなければ、最後のブロックはthenBBになるので問題が無いですが、then節の中にcondがあると新たにブロックが挿入されてしまうのでphi命令に渡すブロックが違うものになってしまいターゲットコード生成時にエラーになります。
ブロック名は被らないように名前を付けてくれる(then1等)ので気にする必要はないです。
car, cdr
carはリストの最初の要素を取り出し、cdrは最初以外のリストを取り出す組み込み関数です。これらはlib.cには書かずに直接コード生成しています。LISPは連続したデータを配列ではなくリストとして持っているのでcdrも簡潔に書けます(その代わりn番目の要素のアクセスがO(n)だったりするが…)。
else if(name == "car") {
auto xs = compile_expr(list->get(1));
// ilistの1番目の要素(car)を取り出す
return builder.CreateExtractValue(builder.CreateLoad(xs), 0);
}
else if(name == "cdr") {
auto xs = compile_expr(list->get(1));
// ilistの2番目の要素(cdr)を取り出す
return builder.CreateExtractValue(builder.CreateLoad(xs), 1);
}
ユーザが定義した関数呼び出し
関数定義と違い、こちらはシンプルです。というか関数を取得するところ以外は組み込み関数と同じです。
else {
// 関数を取得
auto func = cur_env->get(name);
if (!func) {
throw std::logic_error("undefined function: " + name);
}
// 引数を評価する
auto args = list->tail(1);
std::vector<llvm::Value*> callee_args;
EACH_CONS(arg, args) {
callee_args.push_back(compile_expr(arg->get(0)));
}
llvm::ArrayRef<llvm::Value*> callee_args_ref(callee_args);
// call命令を生成
return builder.CreateCall((llvm::Function*)func, callee_args_ref);
}
リテラル(数値や文字列)
LISPコード中の数値や文字列は以下のように扱っています。
else if(id == typeid(Symbol)) { // 識別子(変数)
auto var_name = regard<Symbol>(obj)->value;
// 変数の参照を得て
auto var = cur_env->get(var_name);
if (!var) {
throw std::logic_error("undefined variable: " + var_name);
}
// ロードする
return builder.CreateLoad(var);
}
else if(id == typeid(Nil)) { // nil
// nil関数を呼ぶ
return builder.CreateCall(nilFunc);
}
else if(id == typeid(String)) { // 文字列
// グローバル変数として登録する
return builder.CreateGlobalStringPtr(regard<String>(obj)->value.c_str());
}
else if(id == typeid(Integer)) { // 整数
// 即値として扱う
return builder.getInt32(regard<Integer>(obj)->value);
} else {
throw std::logic_error("unknown expr: " + obj->lisp_str());
}
nil関数はlib.cで定義されています。nilと書くたびにオブジェクトを生成するのはバカバカしいのでグローバル変数として持っておいてそのポインタを返しています。今のところconsを操作する関数はないので使いまわしても問題無いです。
ilist NIL = {0, NULL};
ilist* nil() {
return &NIL;
}
ここまでで一応動くものが出来ました。
$ cat examples/fizzbuzz.lisp
; forに相当するものがないので再帰で
(defun fizzbuzz (n) (int) string
(cond string ((> 101 n) (progn
(print
(cond string
((= (mod n 15) 0) "FizzBuzz")
((= (mod n 3) 0) "Fizz")
((= (mod n 5) 0) "Buzz")
((itoa n))
))
(fizzbuzz (+ n 1))))
((print "finish"))))
(fizzbuzz 1)
$ ./compile examples/fizzbuzz.lisp
(:defun :fizzbuzz (:n) (:int) :string (:cond :string ((:> 101 :n) (:progn (:print (:cond :string ((:= (:mod :n 15) 0) "FizzBuzz") ((:= (:mod :n 3) 0) "Fizz") ((:= (:mod
:n 5) 0) "Buzz") ((:itoa :n)))) (:fizzbuzz (:+ :n 1)))) ((:print "finish"))))
$ ./a.out
1
2
Fizz
4
Buzz
Fizz
7
8
Fizz
Buzz
11
Fizz
13
14
FizzBuzz
.
.
.
finish
動きましたね :)
ハマった所
覚えている範囲で書いてみます。
- 先ほど説明した、
SetInsertPoint(thenBB)がcondがネストしていない状態では普通に動くので不要だと思っていて、いざFizzBuzzを動かそうとしたらエラーが出てしばらく悩みました。 - LLVM IRを出力するときにクラッシュする
- ポインタ型を剥がさず(
loadで参照先を取れます)に使っていたのが原因でした。
- ポインタ型を剥がさず(
感想
コンパイラは初めて作成したのですがLLVMを使うと思いの外、楽でした9。Webで調べると日本語の情報もまあまああるのですが若干古かったり、またBrainf*ck等の簡単なものしかなかったような気がしたのでBrainf*ckよりかは実用的なLISPコンパイラで解説を書いてみました。
もっとLLVMの深いところや理論的なところも書いてみたかったのですが勉強不足ゆえ、(本質を説明していない)LLVMのTips集みたいな感じになってしまいました。この辺りは勉強していきたいですね。
まとめ
LLVMを使用して、Brainf*ckコンパイラとLISPもどきのコンパイラを作成しました。LLVMで何か作成する際に参考にしていただけると幸いです。
あと、宣伝になるのですがC91で頒布する予定の合同誌に本記事を寄稿したのでぜひぜひ手にとっていただければと思います(僕はいないですが)。 木曜日 西み18b 「揚羽高校情報処理部」 で頒布します。CTFや競プロ、3D、機械学習のプロが書いていたりするので内容は濃いだろうと思います。
参考
- きつねさんでもわかるLLVM 柏木 餅子, 風薬
- http://llvm.org/docs/LangRef.html
- https://github.com/llvm-mirror/llvm
- http://llvm.org/docs/doxygen/html/index.html
- https://www.ibm.com/developerworks/jp/opensource/library/os-createcompilerllvm1/
- https://www.google.co.jp
- http://www.wilfred.me.uk/blog/2015/02/21/my-first-llvm-compiler/
- http://qiita.com/k2ymg/items/653c5b22b74a091be604
- http://postd.cc/an-introduction-to-llvm-in-go/
- https://peta.okechan.net/blog/llvm%E3%81%AB%E3%82%88%E3%82%8B%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0%E8%A8%80%E8%AA%9E%E3%81%AE%E5%AE%9F%E8%A3%85
- http://d.hatena.ne.jp/mjt/20111009/p2
-
Passの最適化、バックエンドはやっていないです ↩
-
ネットで調べているとたまに
IRBuilderを使わずに命令や値のクラスをnewしているコードを見かけるのですがビルダーを使ったほうが楽なので使えるなら使ったほうがいいです(ビルダーで作れないものもありますが) ↩ -
dotビューアがインストールされている必要があります。Ubuntuの場合
sudo apt install xdotでインストールできます。 ↩ -
一応言い訳をしておくと、自分の勉強不足、まとまった時間を取るのが難しかった、作り始めたのが3ヶ月前で(飽き性なので)意識が別の方に向かっていったことが重なって残念なLISPコンパイラができました。 ↩
-
なぜ型ごとに出力関数があるかというと型チェックをしていないのでコンパイル時に引数の型がわからないからです… ↩
-
例が少々不自然なのは、
setqの引数の結果が次の式の引数((setq int b ...))に使われるということを強調したかったからです。即値(即値同士の計算も含む)だと直接引数に置かれてしまうんですよね… ↩ -
以前、Cコンパイラを作成しようとして挫折したので… ↩