これは、関数型プログラミングの特徴を Python で説明した長編ポエムです。
IQ145 の美少女は出てきませんので、過度な期待はしないでください。
【対象読者】
- 関数型言語は知らないけど関数型プログラミングの初歩を勉強したい人
(Python を知らなくてもなんとなく分かるように書いたので、PHP や Java や JavaScript の人も読んでみてください)
【連載記事】
- 第1回 関数を受け取る関数は便利だよ編 (←今ココ)
- 第2回 関数を生成する関数はすごいよ編
はじめに
「なぜ関数プログラミングは重要か」という文章があります。タイトルの通り、関数型言語がいかに役に立つかを紹介している文章です。長いですが、3 行でまとめるとこんな感じ:
- ソフトウェアがどんどん複雑になるので、モジュール化が重要
- 関数型言語は、強力なモジュール化機能を提供している
- 特に「高階関数」と「遅延評価」が重要である
しかしこの文章、内容こそ高く評価されているものの、関数型言語の良さを関数型言語のコードで説明しているので、関数型言語を知らないユーザにはちっとも伝わらないという、大きな問題点を抱えています。
関数型言語を知らない人に説明するときに、なんで関数型言語だけを使って説明しようとするんでしょうかね (他のポピュラーな言語のコードを併記すればよかったのに)。まさに「専門用語が分からなくてプログラマに質問したらより難しい専門用語で説明された」状態ですよ。関数型言語を知りたくてあの文章を読んでみても、「やっぱり関数型言語は難しい」という印象しか残らないでしょう。
そこでこのポエムでは、「なぜ関数プログラミングは重要か」で特に重要だとされている「高階関数」と「遅延評価」を、Python で説明します。関数型言語のコードを使わずに説明するので、関数型言語ユーザではない人にも理解しやすいと思います。
(おい、そこ!「日本の Python ユーザは関数型言語ユーザより少ないんじゃね?」とか言うな!)
高階関数を説明するための準備
いきなり高階関数を説明するのはハードルが高いので、その前の準備をしましょう。
関数オブジェクト
Python では、関数はオブジェクトです。
たとえば次のような関数定義の実態は、「関数オブジェクトを作成してそれを変数に代入する」という動作になっています。
## 関数オブジェクトが作成され、変数 hello に代入される
def hello(name):
print("Hello %s!" % name)
## 変数 hello の中身を表示してみると、関数オブジェクトであることがわかる
print(hello) # 実行結果: <function hello at 0x1007a3ed8>
そのため、変数 hello の中身を別の変数に代入しても、関数を呼び出せます。
## 変数 hello の中身を、別の変数に代入できるし、呼び出しもできる
say = hello # 関数オブジェクトを別の変数に代入し、
say("world") # それを呼び出す (結果は hello("world") と同じ)
また def 以外にも、lambda で関数オブジェクトを作成できます。
両者の違いは、こんな感じです:
-
defは複数の文を指定できるがlambdaは単一の式しか指定できない -
defは単独の文にしないといけないが、lambdaは式なので他の文や式に埋め込める - (他にも細かい違いはあるが、本ポエムには関係しないので省略)
## def で定義した関数は
def add(x, y):
return x + y
print(add(3, 5)) #=> 8
## lambda でも書ける (ただし単一式の場合のみ)
add = lambda x, y: x + y # return は書かなくてよい
print(add(3, 5)) #=> 8
## def は複数の文を含めるが、独立した単独の文にしないといけない
def sum(numbers):
t = 0 # この関数は複数の文を含んでいるので、
for n in numbers: # lambda では書けない
t += n
return t
## lambda は単一式しか指定できないが、そのおかげで他の文や式に埋め込める
sorted(strings, lambda s: len(s)) # 関数の引数に lambda を埋め込んだ例
重要なのは、Python では関数はオブジェクトなので、整数や文字列と同じように関数をデータとして扱えるということです。
関数をデータとして扱えるので、たとえばこんなことができます:
- 関数を変数に代入する
- 関数をほかの関数に引数として渡す
- 関数の中で新しい関数を生成して返す
## 関数をデータとして扱える(あたかも整数や文字列と同じように)
n = 123 # 変数に整数を代入する
s = "ABC" # 変数に文字列を代入する
f = hello # 変数に関数を代入する
## 関数をほかの関数に引数として渡す
otherfunc(hello)
## 関数の中で新しい関数を生成して返す
def create_func():
def add(x, y):
return x + y
return add
## またはこれでもよい
#return lambda x, y: x + y
ここでのまとめ:
- Python では、関数はオブジェクトなので、データとして扱える
- データとして扱えるので、こんなことができる
- 関数を変数に代入する
- 関数をほかの関数に引数として渡す
- 関数の中で新しい関数を生成して返す
関数が何を表すか
ひとくちに「関数」といっても、それが表す内容はさまざまです。
ここでは次の3つに分類してみました。
(A) 計算式/変換式 … ある値から別の値を計算します。またはある値を別の値へ変換します。
## 2倍の値を計算する (2倍の値へ変換する)
def double(x):
return x * 2
## 引数の和を計算する (引数の和へ変換する)
def add(x, y):
return x + y
## 行番号をもとにHTMLクラス名を計算する (行番号をHTMLクラス名へ変換する)
def classname(index):
if index % 2 == 0:
return "row-even"
else:
return "row-odd"
(B) 条件式/判定式 … 値が条件を満たすかどうかを判定します。満たすなら true、満たさないなら false を返します。
(注: Python では true / false ではなく True / False を使います。)
## 偶数かどうかを判定する
def is_even(n):
return n % 2 == 0 # 偶数ならTrue、奇数ならFalse
## 空行かどうかを判定する
def is_blank(line):
if not line: # Noneや空文字列ならTrueを返す
return True
if not line.strip(): # 空白や改行文字だけならTrueを返す
return True
return False # それ以外ならFalseを返す
## 恋人どうしかどうかを (テケトーに) 判定する
couples = [
("キリト", "アスナ"),
("勇者", "魔王"),
("ナルト", "ヒナタ"),
("エレン", "ミカサ"), # 異論は認めない
("お兄様", "深雪"),
("キョン", "佐々木"), # 異論は認める
]
def is_couple(boy, girl):
return (boy, girl) in couples
(C) 処理/手続き … 文字列を出力したり、ファイルを読み込んだり、などです。
## 名前を表示する処理
def hello(name):
print("Hello %s!" % name)
## ファイルを読み込んで行数を数える処理
## (注:with 文を使うと、開いたファイルが自動的に閉じられます)
def count_lines(filename):
n = 0
with open(filename) as f:
for line in f:
n += 1
print("%s lines" % n)
とはいえ、この分類は厳密なものではありません。このあとの説明で使うための、あくまで大ざっぱな分類であることをご了承ください。
また本当はここで副作用について説明したいんですが、「副作用とは何か?」と言い出すと本ポエムの範疇と筆者の能力を超えるので、ここでは説明を省略します (そういうのは専門用語大好きな頭のいい人たちがしてくれるでしょう)。
ここでのまとめ:
- 関数が表すもの
- 計算式/変換式 … ある値から別の値を計算する (変換する)。
- 条件式/判定式 … 条件が成り立つかどうかを判定する。true/falseを返す。
- 処理/手続き … 出力したりファイルを読み込んだり。
関数/手続き/サブルーチンにおける引数の役目
たとえば、「1 から 10 までを合計する関数」を作ってみます。
(注: range(1, 11) は 1 から 10 までの整数を生成します。11 までではないです。)
def total():
t = 0
for i in range(1, 10+1):
t += i
return t
簡単すぎますね。
とはいえ、通常はこう書かず、引数を使って「1 から n までを合計する関数」にするでしょう。
def total(n):
t = 0
for i in range(1, n+1):
t += i
return t
さらには、「m から n までを合計する関数」でもいいでしょう。
def total(m, n): # 引数チェックは省略
t = 0
for i in range(m, n+1):
t += i
return t
これを見ると:
- 最初の関数では内容が「1 から 10 まで」と固定されていたのに、
- 二つ目の関数では「1 から n まで」と可変部分ができ、
- 三つ目の関数では「m から n まで」と可変部分が増えました。
このように、関数/手続き/サブルーチンでは引数を使うことで可変部分を作る(or 増やす)ことができます(乱暴ですが、もしテンプレートエンジンをご存知であれば、それと似てると思いませんか?)。また可変部分が多いほど、応用範囲も広くなります。
そして関数の可変部分に、数値や文字列や真偽値や配列といったデータだけでなく、計算式/変換式や、条件式/判定式や、処理/手続きを渡すと、より応用範囲が広がります。関数オブジェクトを使うと、それができます。
関数を受け取る関数 (高階関数) について
高階関数とは、関数をデータとして扱うような関数です。具体的にはこんな感じ:
- 関数を受け取るような関数
- 関数を返すような関数(関数を生成する関数)
(もちろん、「関数を受け取って関数を返すような関数」も高階関数です。)
このうち、本ポエムでは 1 つめの「関数を受け取るような関数」について説明します。
関数を受け取るような高階関数は、大ざっぱには以下のように分類できます。
- 計算式/変換式を受け取る関数
- 条件式/判定式を受け取る関数
- 処理/手続きを受け取る関数
これらを、具体例で見ていきましょう。
計算式/変換式を受け取る高階関数
次のコードを見てください。2 つの関数が別々のことを行っています。
## 整数の配列を受け取り、各要素を2倍にする関数
def doubles(arr):
newarr = []
for x in arr:
newarr.append(x * 2) # 各要素を2倍にする
return newarr
## 文字列の配列を受け取り、各要素を大文字に変換して返す関数
def uppers(arr):
newarr = []
for x in arr:
newarr.append(x.upper()) # 各要素を大文字にする
return newarr
(注:Python では、「配列」ではなく「リスト」と呼びます。「リスト」と呼んでますが連結リストではなく、他の言語でいう可変長配列 (Java の java.util.ArrayList や Ruby の Array) です。本ポエムは Python の解説が目的ではないので、他の言語ユーザのことを配慮し、あえて「配列」と呼んでいることをご了承ください。)
さて、この 2 つの関数は、違う処理を行っていますが、やっていることはよく似ています。違うのは、newarr.append() に渡す計算式/変換式だけです。
そこで、共通する部分を map() という関数にくくりだし、違う部分は関数として渡すことにします:
## 配列の各要素に計算式/変換式を適用する関数
def map(func, arr):
newarr = []
for x in arr:
newarr.append(func(x)) # 各要素に計算式/変換式を適用する
return newarr
## 整数の配列を受け取り、各要素を2倍にする関数
def doubles(arr):
def func(x): return x * 2 # 計算式/変換式を使って、
return map(func, arr) # 共通化した関数を呼び出す
## または
#return map(lambda x: x * 2, arr)
## 文字列の配列を受け取り、各要素を大文字に変換して返す関数
def uppers(arr):
def func(x): return x.upper() # 計算式/変換式を使って、
return map(func, arr) # 共通化した関数を呼び出す
## または
#return map(lambda x: x.upper(), arr)
このように、map() は「計算式/変換式を関数として受け取る高階関数」です。また map() のような高階関数を使うことで、共通する処理をくくりだせ、コードが簡潔になりました。
ここでのまとめ:
- 共通する部分を
map()という関数にくくりだす - 計算式/変換式を関数で表す
- その関数を
map()に、配列とともに渡す
なお、Pythonでは map() は標準で組み込まれているため、自分で定義する必要はありません。また Python の map() は、配列だけでなく文字列やファイルに対しても使えますが、それは本ポエムの趣旨ではないので省略します。
条件式/判定式を受け取る高階関数
次のコードを見てください。2つの関数が別々のことを行っています。
## 整数の配列を受け取り、偶数だけを選んで返す関数
def evens(arr):
newarr = []
for x in arr:
if x % 2 == 0: # 偶数だけを選ぶ
newarr.append(x)
return newarr
## 文字列の配列を受け取り、終わりが ".html" であるものだけを選ぶ関数
def shorts(arr):
newarr = []
for x in arr:
if x.endswith(".html"): # 終わりが ".html" であるものを選ぶ
newarr.append(x)
return newarr
(注:Python では「配列」ではなく「リスト」と呼びますが、本ポエムは他の言語ユーザのことを配慮し、あえて「配列」と呼んでいることをご了承ください。)
この2つの関数も、違う処理を行っていますが、やっていることはよく似ています。違うのは、if文で指定している条件式/判定式だけです。
そこで、共通する部分は filter() という関数にくくりだし、違う部分は関数として渡すことにします:
## 配列の各要素から、条件式/判定式を満たしたものだけを選んで返す関数
def filter(func, arr):
newarr = []
for x in arr:
if func(x): # 条件式/判定式を満たした要素だけを選ぶ
newarr.append(x)
return newarr
## 整数の配列を受け取り、偶数だけを選んで返す関数
def evens(arr):
def func(x): return x % 2 == 0 # 条件式/判定式を関数にして
return filter(func, arr) # 共通関数を呼びだす
## または
#return filter(lambda x: x % 2 == 0, arr)
## 文字列の配列を受け取り、終わりが ".html" であるものだけを選ぶ関数
def htmls(arr):
def func(x): return x.endswith(".html") # 条件式/判定式を関数にして、
return filter(func, arr) # 共通関数を呼び出す
## または
#return filter(lambda x: x.endswith(".html"), arr)
このように、filter() は「条件式/判定式を関数として受け取る高階関数」です。そして filter() のような高階関数を使うことで、コードを簡潔にできました。
ここでのまとめ:
- 共通する処理を
filter()という関数にくくりだす - 条件式/判定式を関数として表す
- それを
filter()に、配列とともに渡す
なお Python では filter() も標準で用意されており、自前で定義する必要はありません。また Python 標準の filter() は、配列だけでなく文字列やファイルにも使えますが、本ポエムの趣旨から外れるので説明は省略します。
処理/手続きを受け取る高階関数
次のコードを見てください。2つの関数で別々のベンチマークを行っています。
## (Python 3 用)
try:
xrange
except NameError:
xrange = range
N = 1000000
import time
## str.join() を使った文字列連結のベンチマーク
def bench_strjoin():
start = time.time()
for _ in xrange(N):
s = str.join("", ("Haruhi", "Kyon", "Mikuru", "Itsuki", "Yuki"))
end = time.time()
print("%.3f sec" % (end - start))
## '%' 演算子を使った文字列連結のベンチマーク
def bench_percentop():
start = time.time()
for _ in xrange(N):
s = "%s%s%s%s%s" % ("Haruhi", "Kyon", "Mikuru", "Itsuki", "Yuki")
end = time.time()
print("%.3f sec" % (end - start))
(注:Python では、str.join() を使うときは "".join((...)) と書くのが普通です。
しかしこれは非 Python ユーザにはとても奇妙に見えるので、ここでは非 Python ユーザでも分かりやすい str.join("", (...)) を使っています。)
これら2つの関数をみると、次のことが分かります。
- 実行時間を計測する処理は、共通です。
- ベンチマークの内容は、共通していません。
そこで、ベンチマークを計測する benchmark() という関数を定義し、そこにベンチマークの内容 (処理) を関数として渡します。すると、次のようなコードになります:
## (Python 3 用)
try:
xrange
except NameError:
xrange = range
N = 1000000
import time
## 実行時間を計測して表示する関数
def benchmark(func):
start = time.time()
func() # ベンチマークの処理を呼び出す
end = time.time()
print("%.3f sec" % (end - start))
## str.join() を使った文字列連結のベンチマーク
def bench_strjoin():
def func():
for _ in xrange(N):
s = str.join("", ("Haruhi", "Kyon", "Mikuru", "Itsuki", "Yuki"))
benchmark(func)
## '%' 演算子を使った文字列連結のベンチマーク
def bench_percentop():
def func():
for _ in xrange(N):
s = "%s%s%s%s%s" % ("Haruhi", "Kyon", "Mikuru", "Itsuki", "Yuki")
benchmark(func)
## 注:for文を benchmark() に含めると、func() の呼び出しコストが
## 無視できなくなるので、ここではそうしていません。
このように、benchmark() は「処理/手続きを関数として受け取る高階関数」です。高階関数のおかげで、共通する処理をくくり出せ、コードが簡潔になりました。
これをもう少し一般化すると、「高階関数を使うことで、前処理と後処理を追加できる」と言えます。たとえば:
- 処理の前後に時間を計測する処理を追加する
- 処理の前後にファイルをオープン/クローズする処理を追加する
- 処理の前後にデバッグ用メッセージを出力する処理を追加する
などが考えられます。
ここでのまとめ:
- 共通する処理を
benchmark()という高階関数にくくりだす - 処理/手続きを関数で表す
- その関数を
benchmark()に渡す
なお前処理と後処理を追加したい場合、Python では高階関数を使わず、with 文を使うのが一般的です (後述)。
計算式でも処理でも受け取る高階関数
次のコードを見てください。2つの関数が別々のことを行っています。
## 整数の配列を受け取り、合計を返す関数
def sum(arr):
t = 0 # 初期値:0
for x in arr:
t = t + x # 合計を計算する (あとの説明のため、t+=x とはしない)
return t
## 文字列の配列を受け取り、辞書に変換して返す関数
def to_dict(arr):
t = {} # 初期値:空の辞書
for x in arr:
t[x] = x # 辞書に変換する
t = t # これは本来不要だが説明のために追加
return t
(注:Python での「辞書」は、Ruby の Hash や Java の java.util.HashMap に相当します。)
この2つの関数も、違う処理を行っていますが、やっていることはよく似ています。違うのは、初期値と、ループ内の計算式や処理だけです。
そこで、ループ内の計算式や処理を、関数にしてやります。すると、次のように共通部分を reduce() という関数にくくり出せます:
## 配列の各要素に対し、何らかの計算や処理を行い、積み重ねた結果を返す
def reduce(func, arr, initial):
t = initial # 初期値
for x in arr:
t = func(t, x) # 計算や処理を行う
return t
## 整数の配列を受け取り、合計を返す関数
def sum(arr):
def func(t, x): return t + x # 計算式を関数にして
return reduce(func, arr, 0) # 共通関数を呼びだす
## または
#return reduce(lambda t, x: t + x, arr, 0)
## 文字列の配列を受け取り、辞書に変換して返す関数
def to_dict(arr):
def func(t, x): # 処理を関数にして
t[x] = x
return t
return reduce(func, arr, {}) # 共通関数を呼び出す
このように、reduce() は「計算式や処理を関数として受け取る高階関数」です。「合計を計算する」のと「辞書へ変換する」のは、一見するとまったく違う処理のはずなのに、実は reduce() を使えば共通部分がくくりだせるというのは、とても面白いと思いませんか?
ところで、上の定義の reduce() では初期値が必須でした。しかし、一般的には reduce() では初期値を省略でき、その場合は先頭の要素が初期値として使われます。コードで示すとこんな感じ:
class Undefined(object):
pass # Pythonの pass は「何もしない」という意味
undefined = Undefined()
def reduce(func, arr, initial=undefined):
## 初期値が指定されなかったら、かわりに先頭の要素を使う
if initial is undefined: # 'is' は '==' のより厳密バージョンだと思って!
t = undefined
for x in arr:
if t is undefined:
t = x
else:
t = func(t, x)
## ただし配列が空ならエラー (戻り値が undefined になってしまうので)
if t is undefined:
raise TypeError("reduce() of empty sequence with no initial value")
return t
## 初期値が指定されていれば、いままで通り
else:
t = initial
for x in arr:
t = func(t, x)
return t
## 注: `t = initial` と `return t` は if 文の外にくくりだせますが、
## 初心者への分かりやすさを優先したいのでこのままで。
この場合、sum() は初期値を省略して次のように書けます (引数名も変えています)。
def sum(arr):
return reduce(lambda a, b: a + b, arr)
こう書くと、2つの引数をとる「+」演算子が、あたかも n 個の引数をとるかのように見なせます。
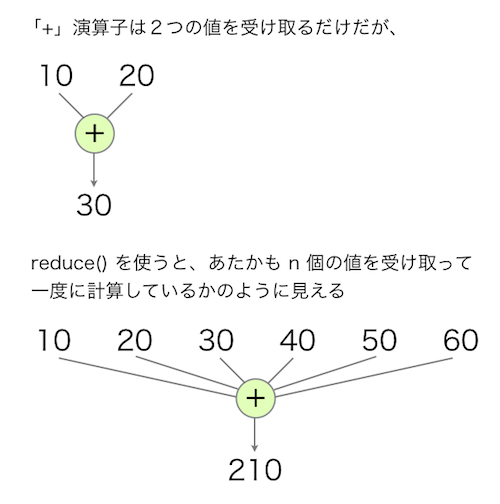
もちろん、reduce() の中身は2つの引数をとる「+」演算子を何回も繰り返しているだけなんですが、見方によっては n 個の引数をとる演算子を 1 回だけ使っているように見えるというのが面白いですね。
ここでのまとめ:
- 共通する処理を
reduce()という関数にくくりだす - 計算式や処理を関数として表す
- それを
reduce()に、配列とともに渡す
なお Python では reduce() も標準で用意されており、自前で定義する必要はありません (ただし Python 3 では from functools import reduce が必要)。
高階関数を組み合わせる
高階関数は、単体でも十分便利ですが、組み合わせることでさらに便利になります。
## 1 から 10 までを出力する (1 <= x < 10+1)
nums = range(1, 10+1)
for x in nums:
print(x)
## 1 から 10 までのうち、奇数だけを選択して出力する
nums = range(1, 10+1)
for x in filter(lambda x: x%2 == 1, nums):
print(x)
## 1 から 10 までのうち、奇数だけを選択して、二乗して出力する
nums = range(1, 10+1)
for x in map(lambda x: x*x, filter(lambda x: x%2 == 1, nums)):
print(x)
## 1 から 10 までのうち、奇数だけを選択して、二乗して、合計する
from functools import reduce # python3
nums = range(1, 10+1)
total = reduce(lambda t, x: t+x,
map(lambda x: x*x, filter(lambda x: x%2 == 1, nums)))
print(total)
## または
from functools import reduce # python3
nums = range(1, 10+1) # 1 から 10 までのうち、
nums = filter(lambda x: x%2 == 1, nums) # 奇数だけを選択して、
nums = map(lambda x: x*x, nums) # 二乗して、
total = reduce(lambda t, x: t+x, nums) # 合計する
print(total)
ただ正直に言うと、Python の lambda はあまり書きやすくないですね。こういうのは Ruby や Groovy や Scala のほうがずっと自然に書けます。
## Ruby ならこんなに自然に書ける
print (1..10).select {|x| x%2 == 1 }.map {|x| x*x }.reduce {|t,x| t+x }
この Ruby のコードを見ると、処理が順番に流れていくのが視覚的によくわかります。
もし UNIX を使っている人なら、これがパイプ処理によく似ていることに気付くでしょう。実はパイプ処理との比較をするなら遅延評価の説明をすべきなんですが、それは後日とさせてください。
ループ vs 高階関数
先ほどの、高階関数を組み合わせたコードを再掲します。
## 高階関数を組み合わせたコード
from functools import reduce # python3
total = reduce(lambda t, x: t+x,
map(lambda x: x*x, filter(lambda x: x%2 == 1, nums, 0)))
## または
nums = filter(lambda x: x%2 == 1, nums) # 奇数だけを選択して、
nums = map(lambda x: x*x, nums) # 二乗して、
total = reduce(lambda t, x: t+x, nums, 0) # 合計する
これと同じことを、for 文を使って手続き的に書いてみました。
## for 文を使って手続き的に書いたコード
total = 0
for x in nums:
if x%2 == 1:
total += x*x
うーん、どう見ても for 文のほうが簡潔で分かりやすい…
これら両方のコードを比べると、次のことがわかります:
| 手続き的に書いたコード | 高階関数を使ったコード |
|---|---|
| ループや条件分岐や計算式が 1 つのかたまりになっている | 処理を細かく関数に分けて、それらを組み合わせている |
| 配列の要素をひとつずつ順番に扱う | 配列全体をまとめて扱う (「配列全体から選択する」「配列全体を二乗する」「配列全体を合計する」など) |
| 動作が高速(ループが1回だけだし、関数呼び出しも使ってないので) | 動作は遅め (ループが、flter と map と reduce で実質的に 3 回分必要だし、関数呼び出しの回数も多いため) |
特に大事なのは 1 番目と 2 番目です。関数型プログラミングでは、このような考え方やものの見方をします。
3 番目に挙げた動作速度について補足すると、関数の組み合わせはたしかにループで書いたのより遅くなりますが、その遅さが問題になるかどうかはまた別の話です。ベンチマークでは遅くなるけど体感では別に変わらないというケースや、速度のボトルネックが I/O など別の部分にあるケースのほうがずっと多いでしょう。
残念なお知らせ
残念ながら、関数を受け取るような高階関数は、Python ではそれほど頻繁には使われません。なぜなら、高階関数で書けることが、別の方法でもっと自然に書けることが多いからです。
たとえば map() や filter() は、内包表記 (comprehension) で書いたほうが自然です。
## map() は
newarr = map(lambda x: x * x, arr)
## リスト内包表記でこう書ける
newarr = [ x * x for x in arr ]
## filter() は
newarr = filter(lambda x: x % 2 == 0, arr)
## リスト内包表記でこう書ける
newarr = [ x for x in arr if x % 2 == 0 ]
特に map() と filter() を組み合わせる場合は、内包表記の読みやすさが際立ちます。
## map() と filter() の組み合わせは
newarr = map(lambda x: x * x, filter(lambda x: x % 2 == 0, arr))
## リスト内包表記でこう書ける
newarr = [ x * x for x in arr if x % 2 == 0 ]
reduce() は、合計値を計算するなら sum() という関数が使えるし、文字列の配列を辞書に変換するなら辞書の内包表記が使えます。
## たとえばこれは
total = reduce(lambda t, x: t + x, arr, 0)
## どう考えてもこっちのほうがいい
total = sum(arr)
## たとえばこれは
def func(t, x):
t[x] = x
return t
dictionary = reduce(func, strings)
## 辞書内包表記を使ったほうがいい
dictionary = { x:x for x in strings }
また前処理と後処理を追加するなら、with 文を使うべきです。
try:
xrange # Python2 用
except NameError:
xrange = range # Python3 用
N = 1000000
import time
from contextlib import contextmanager
@contextmanager # '@' は関数デコレータ (解説は後日)
def benchmark():
start = time.time()
yield # 'yield' はジェネレータ用 (解説は後日)
end = time.time()
print("%.3f sec" % (end - start))
with benchmark():
for _ in xrange(N):
s = str.join("", ("Haruhi", "Kyon", "Mikuru", "Itsuki", "Yuki"))
with benchmark():
for _ in xrange(N):
s = "%s%s%s%s%s" % ("Haruhi", "Kyon", "Mikuru", "Itsuki", "Yuki")
このように、Python にはいろんな便利機能が提供されているため、関数を受け取るほうの高階関数はそれほど使われてはいません (まったく使われていないわけではなく、sorted(arr, key=fn) や re.sub(pattern, fn, string) などでは使われています)。
特に reduce() は、Python2 ではビルトイン関数だったのに、Python3 ではライブラリから import しないと使えなくなりました。これは事実上の格下げであり、「Python では reduce() より他の手段を使え」という意図が見えます。
とはいえ、関数を生成するほうの高階関数は今でもよく使われます。これについては次回のポエムで説明します。
Python固有の話
-
すでに説明しましたが、Python では配列のことを「リスト」と呼び、またハッシュテーブルのことを「辞書 (Dictionary)」と呼んでます。Python でのリストは配列のことであって連結リストのことではありません。
-
map()やfilter()は、Python2 では配列 (リスト) を返していましたが、Python3 ではジェネレータを返します(つまり遅延評価されます)。Python3 でも配列がほしい場合は、list(map(...))やlist(filter(...))のようにします。 -
reduce()は、Python3 からはfrom functools import reduceをしないと使えなくなりました。これは、reduce()より内包表記やループを使えという意図でしょう。 -
関数型言語では、演算子をあたかも関数のように扱えることが多いです。Python では、
operatorモジュールを使うと同様なことができます。
import operator
## '==' 演算子に相当
operator.eq(1+1, 2) #=> True
## '+' 演算子に相当
operator.add(1, 2) #=> 3
練習問題
解答例はコメント欄に書きます。
【問題 1 】 map() と filter() と reduce() を、自分で定義してみましょう。
【問題 2 】 "3.4.10" のようなバージョン番号を、[3, 4, 10] のような整数の配列に変換する関数 parse_version() を、map() を使って定義してみましょう。使い方はこんな感じ:
print(parse_version("3.4.10")) #=> [3, 4, 10]
(ヒント:文字列を分割するには "3.4.2".split(".")、また文字列を整数に変換するのは int("123") を使います。)
【問題 3 】 文字列の配列から、正規表現に一致したものだけを選び出す関数 grep() を、filter() を使って定義しましょう。使い方はこんな感じ:
arr = grep(r'\d+', ["ABC", "F102", "X10Y", "ZZZ"])
print(arr) #=> ["F102", "X10Y"]
(ヒント:正規表現は import re; m = re.search(r'..pattern..', string) を使います。)
【問題 4 】 配列の要素の中から、指定した比較方法での最大値を返す関数 max_by() を、reduce() を使って定義してみましょう。使い方はこんな感じ:
members = [
("Haruhi", "C"), # ハルヒは C
("Mikuru", "E"), # みくるは E
("Yuki", "A"), # 有希は A
]
def getvalue(x): # おっぱいを返す
return x[1]
## おっぱいがいちばん大きいのは誰か?
ret = max_by(getvalue, members)
print(ret) #=> ("Mikuru", "E")
(追記 2015-02-08:問題が間違ってた!すまん!)
まとめ
関数を受け取るほうの高階関数について、Python を使って説明しました。
- Python では関数をデータとして扱える
- 関数を変数に代入したり、
- 関数を別の関数に渡したり、
- 関数の中で関数を生成して返したりできる
- 関数の大ざっぱな分類
- (A) 計算式/変換式を表す
- (B) 条件式/判定式を表す
- (C) 処理/手続きを表す
- 関数をデータとして扱う関数を高階関数という
- 関数を受け取る関数
- 計算式/変換式として受け取る (例:
map()) - 条件式/判定式として受け取る (例:
filter()) - 処理/手続きとして受け取る (例:
benchmark())
- 計算式/変換式として受け取る (例:
- 関数を返す関数 (生成する関数) … 次回で説明
- 関数を受け取る関数
おわりに
関数型言語ポエムが流行したおかげで、今までになく関数型言語に注目が集まっています。これはまたとないチャンスなので、この機に乗じて Python や Ruby の関数言語的な機能を宣伝して漁夫の利を狙いたいです。