大人気TBSドラマ、「逃げるは恥だが役に立つ」でも話題になったインフラエンジニアという言葉ですが、今ではインターネットインフラを知らないまま開発をするのも難しい状況になっています。クラウドが一般化されたからといって単にリソースの調達が簡単になっただけで、つまりハードウェアの知識が無くても何とかやっていけるようになっただけであり、インフラの知識が要らなくなったなどということは全くなく、むしろdevopsの掛け声とともに、ソフトウェア開発者にインフラを見なければならない新たな責務が課せられたという、なかなか痺れる状況なのだろうと思います。
そういった中で、先日のさくらインターネットのAdvent Calendar最終日に「いまさら聞けないLinuxとメモリの基礎&vmstatの詳しい使い方」という記事を書かせて頂きましたが、今回はLinuxサーバの「負荷」と、ロードアベレージに関して、掘り下げて見てみます。
ところで全くの余談ですが、「逃げ恥」の平匡さんが勤める会社のシーンは、新宿にあるさくらインターネットの東京支社で撮影してまして、「この会社の命綱は俺が握っている」「クソッインフラエンジニアめ」「今すぐサーバー破壊するぞ、この社長様」の一連のやり取りも、うちの28階にあるエンジニアフロアで撮影していました。本当に本当に、インフラエンジニアは大切にしないといけませんね。
~閑話休題~インフラエンジニアめwwwwwwwwwwww pic.twitter.com/NOSSV3hRci
— ぽこすけ (@pokosuke) 2016年11月29日
サーバの負荷とは何か?
そもそも、サーバが「軽い」とか「重い」という言葉を使う機会は多いはずですが、その「負荷」についてみてみます。
まず負荷についてざっくりいうと、ブラウザやAPIを叩くプログラムなどのクライアントから、サーバへリクエストを送信して、レスポンスが返ってくるまでのタイミングが長いか短いかということです。
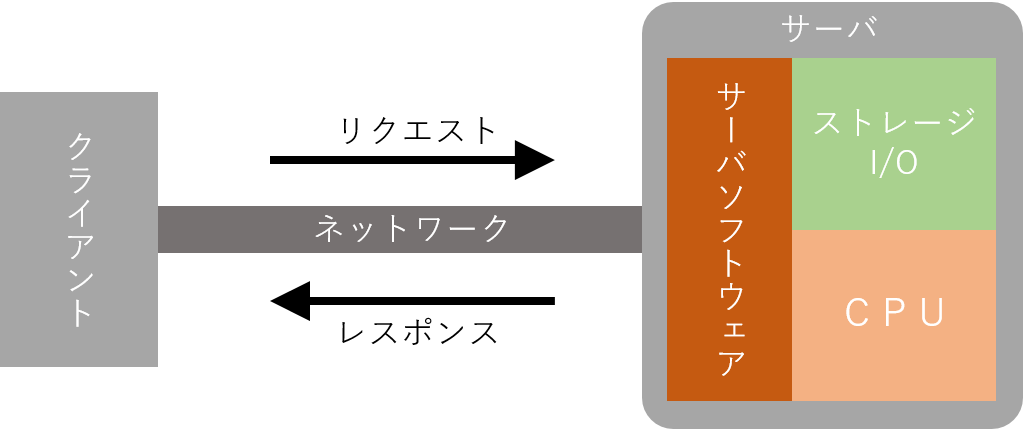
そして、負荷は大きく分けるとネットワークの負荷とサーバの負荷の2種類があります。
サーバが重いといっても、実はサーバには全く負荷がかかってなくて、途中のネットワークがあふれているだけ、ということも良くありますが、今回はサーバ自体の負荷にフォーカスして見ていきます。
サーバの負荷には、サーバソフトウェアの問題と、I/OやCPUといったリソース不足の問題の、大きく2つに分けられます。
サーバソフトウェアの問題で代表的なものは、ApacheのMaxClientsが少なすぎるとか、MySQLのmax_connectionsが少なすぎるなど、設定に起因するものです。
次にリソースの不足という観点では、おおむねI/O負荷とCPU負荷の2つであり、共にハードウェア性能(もしくは立ち上げたクラウドサーバの性能)の限界に起因するものです。
感覚をつかむため、サーバソフトウェアとリソースの関係を、銀行の窓口で表現してみます。
サーバソフトウェアは窓口の人、リソースはバックヤードの人と言い換えられます。
窓口の人の数が足りなければ、バックヤードの人が余っていても、顧客の相手が出来ずに待ち時間が延びてしまいます。
逆に窓口の人を増やしたとしても、バックヤードの人が足りなければ、バックヤードの対応が輻輳してしまいます。
つまり、リソースがある限りはリクエストを受け付けたほうがいい反面、必要以上のリクエストを受け付けてしまうとリソース不足で、逆に遅くなるということを示しています。
そのため、リソースが不足していれば増設やグレードアップを検討しなければなりませんし、リソースがあまっているのであれば最大限に利用するべくサーバソフトウェアの設定を見直して制限を緩和する必要があるため、リソースが実際にどれだけ利用されているのかを正確に把握することが重要です。
負荷を観察する
ここからは、実際にサーバへの負荷をかけて、vmstatコマンドによってその状態を観察します。
もしこの記事を見ながら手元のサーバで実験するなら、ターミナルを2つ立ち上げ、1つ目のウィンドウでvmstatを実行し、もう一つのウィンドウでコマンド投入を行ってください。
これにより、コマンドの実行による、CPUやメモリ、I/Oの状態などの変化を観察することができます。
# vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 2816 192872 269756 958144 0 0 0 2 0 0 0 0 100 0 0
0 0 2816 192872 269756 958144 0 0 0 0 1024 65 0 0 100 0 0
0 0 2816 192872 269756 958144 0 0 0 0 1018 64 0 0 100 0 0
さて、Linuxは複数のプロセスを同時に実行することができますが、これは限られた数のCPUコアを時分割という方法で区切って、擬似的に実現しています。
たとえば、1個のCPUコアを持つLinuxマシンで10個のプロセスを実行する際には、実行キューといわれる待ち行列の中に10個のプロセスがリストアップされ、単位時間内に10回の切り替え(コンテキストスイッチといいます)を行って、すべてのプロセスが実行されているように見せかけています。
この実行キューに入っているプロセスの数をvmstatのprocsにあるrの数値で取得することができます。
また、実行中にもかかわらずディスクやネットワークなどのI/Oで待ち状態に入って、実際には実行できていないプロセスの数をprocsにあるbの数値で取得することができます。
そして、procsのrとbを足した数がロードアベレージになります。
このほかの項目は以下のとおりです。
| procs | r - 実行待ちのプロセス数 b - I/O待ちのプロセス数 |
| memory | swpd - スワップの使用量 free - 空きメモリ容量 buff - バッファキャッシュの使用量 cache - ページキャッシュの使用量 |
| swap | si - スワップインした回数の秒間平均 so - スワップアウトした回数の秒間平均 |
| io | bi - HDDから読み込んだブロック数の秒間平均 bo - HDDへ書き込んだブロック数の秒間平均 |
| system | in - 1秒あたりの割り込み回数 cs - 1秒あたりのコンテキストスイッチの回数 |
| cpu | us - カーネル以外が使用したCPU使用率 sy - カーネルが使用したCPU使用率 id - アイドル状態の割合 wa - I/Oウェイトにかかった割合 st - Xenなどで、別のDOMが使用したCPU割合 |
ロードアベレージ
Linuxサーバの負荷というと、まずロードアベレージの把握を考える方も多いと思います。
先ほどの項目で述べたとおり、ロードアベレージとはLinuxカーネルがCPUリソースを割り当てたプロセスの数と、I/O待ち状態が原因でCPUが利用されていないプロセスの合計を示しており、負荷状況を把握することができます。
I/O負荷が全く無い状態を仮定すると、1プロセスがCPUを100%占有している際にはロードアベレージが1となり、2プロセスで100%占有している場合は2となります。
ちなみに、CPUのコア数が1個の場合はロードアベレージが1になるとCPUが100%使用されている状態であり、コア数が16個の場合はロードアベレージ16になるとCPUが100%使用されている状態となります。
逆に、CPUの負荷がかかっていないのにロードアベレージが上昇している場合には、I/Oがボトルネックになっていることを示します。
実際に、ロードアベレージの変化を見るために、負荷プログラムを使って無限ループを発生させてみましょう。
以下のプログラムを、loadtest.pl という名前で保存し、chmod +x loadtest.pl を実行して、実行権限を付与してください。
# !/bin/perl
my $nprocs = $ARGV[0] || 1;
for( my $i=0; $i<$nprocs; $i++ ){
my $pid = fork;
die $! if( $pid < 0 );
if( $pid == 0 ){
while(1){
if( $ARGV[1] ){
open(IN, ">/dev/null");
close(IN);
}
}
}
}
wait;
このプログラムに4という引数を付与して実行すれば、4並列で無限ループを行い、ロードアベレージは4まで上昇しますが、まずは同時実行数1で負荷をかけて挙動を見てみます。
ちなみに、サーバにおいて他のソフトウェアが実行されている場合は、数字が変わってしまうのでご注意ください。
# ./loadtest.pl 1
vmstatをみると、procsのrは1となっており1プロセスが実行中であることが分かります。また、cpuのusにあるユーザプロセスにおけるCPU使用率は100%になっていますが、csで示されるコンテキストスイッチ数は10前後と比較的少ない値であり、ほぼCPUを1プロセスで占有できていることが分かります。なおメモリの使用量やI/Oの数には特に変化が見られません。
procs -----------memory----------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1593760 44468 165836 0 0 0 0 1004 12 100 0 0 0 0
1 0 0 1593760 44468 165836 0 0 0 0 1005 11 100 0 0 0 0
1 0 0 1593760 44468 165836 0 0 0 0 1004 11 100 0 0 0 0
1 0 0 1593760 44468 165836 0 0 0 0 1004 7 100 0 0 0 0
ちなみに、このまましばらく放置しておくと、ロードアベレージは1に収束します。
# top
top - 18:40:44 up 7:51, 2 users, load average: 0.86, 0.23, 0.08
Tasks: 88 total, 2 running, 86 sleeping, 0 stopped, 0 zombie
Cpu(s): 49.9%us, 0.0%sy, 0.0%ni, 49.9%id, 0.0%wa, 0.0%hi, 0.2%si, 0.0%st
Mem: 4055032k total, 775648k used, 3279384k free, 57708k buffers
Swap: 2097640k total, 0k used, 2097640k free, 573796k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28275 root 20 0 25568 504 176 R 99.8 0.0 0:06.57 loadtest.pl
次に、同時実行数4で負荷をかけてみます。負荷テストプログラムを^Cで終了させてから、4という引数を付けて実行します。
# ./loadtest.pl 4
vmstatをみると、procsのrは4となっており、cpuのusにあるユーザプロセスにおけるCPU使用率が100%になっていることが分かります。先ほどより大きく上昇しているのはsystemのcsの値であり、プロセス数が増えたために頻繁にCPUが切り替えられています。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 0 1745708 9896 57452 0 0 73 3 334 41 31 0 68 0 0
4 0 0 1745700 9896 57452 0 0 0 4 1007 517 100 0 0 0 0
4 0 0 1745700 9896 57452 0 0 0 0 1004 506 100 0 0 0 0
4 0 0 1745700 9896 57452 0 0 0 0 1004 509 100 0 0 0 0
ちなみに、このまましばらく放置しておくと、ロードアベレージは4に収束します。
# top
top - 18:43:11 up 7:53, 2 users, load average: 3.68, 1.98, 0.36
カーネル負荷を発生させる
先ほどの例では単純にループしてCPUに負荷をかけるだけでしたが、次はループの中でシステムコールを呼び出してみます。
次に、先ほどの負荷プログラムに引数を追加して実行します。引数に1と指定することで、先ほどの負荷プログラムはopen/closeシステムコールを呼び出します。
先ほどの負荷テストプログラムを^Cで終了させてから、4と1という引数を付けて実行します。
# ./loadtest.pl 4 1
vmstatを実行してみると、usのユーザプロセスにおけるCPU使用率が45~47%で、syのシステム(カーネル)におけるCPU使用率が53%~55%であり、カーネル内の処理が行われていることがわかります。
ちなみに、それ以外の値はsystemのcsが増加していますが、ユーザプロセスからカーネルを呼び出す際にはコンテキストスイッチを行う必要があるため、一つ前の試験の値の、おおむね倍程度になっていることが分かります。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 0 1745312 9904 57524 0 0 52 2 524 175 51 0 49 0 0
4 0 0 1745312 9904 57524 0 0 0 0 1004 925 47 53 0 0 0
4 0 0 1745312 9904 57524 0 0 0 0 1006 930 47 53 0 0 0
4 0 0 1745320 9904 57524 0 0 0 0 1004 915 45 55 0 0 0
値が確認できれば、負荷テストプログラムを^Cで終了させておきます。
CPUとロードアベレージに関するまとめ
ここまでのことをまとめると以下のとおりです。
- CPUに負荷をかけると、cpuのusやsyが上昇する
- ユーザプロセスだけで負荷が発生している場合には、usが上昇してsyは変化しない
- 多くのプロセスを並行して実行させると、systemのcsが上昇する
- カーネルの呼び出し(システムコール)を行うと、syが上昇するとともに、csの値も増加する
- 実行中のプロセスの数がprocsのrに表示される
- procsのrと、ロードアベレージの値は、同じ値へと近づく
I/O負荷を上昇させてみる
先ほどまではCPUへの負荷をかけていましたが、次はI/Oに対する負荷をかけてみます。
なお先ほどに引き続きvmstatを実行し続けておきます。
ddを使用してファイルへの書き込みを行います。このとき、ページキャッシュが利用されないように、directオプションを付与します。
# dd if=/dev/zero of=test bs=1M count=512 oflag=direct
512+0 records in
512+0 records out
536870912 bytes (537 MB) copied, 4.0191 s, 134 MB/s
ddを実行中にvmstatを確認すると、I/O書き込み(ioのbo)が増大し、I/Oウェイト(cpuのwa)も95%~96%と大きく跳ね上がっていることが分かります。
またI/O待ち(procsのb)のプロセス数が1となり、ddがI/Oによってブロックされています。
procs -----------memory----------- ---swap-- -----io----- --system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 1745204 9304 57556 0 0 0 0 14 12 0 0 100 0 0
0 1 0 1744080 9308 57564 0 0 4 126976 340 391 0 6 7 87 0
0 1 0 1744080 9312 57572 0 0 4 129024 326 399 0 5 0 95 0
0 1 0 1744080 9312 57572 0 0 0 132096 325 397 0 4 0 96 0
0 1 0 1744080 9316 57572 0 0 0 125952 315 382 0 4 0 96 0
0 0 0 1744956 9316 57572 0 0 0 10240 51 49 0 1 74 25 0
なおアイドル(cpuのid)は0%となっていますが、決してCPUの空き率が0%なわけではありません。CPUの使用率はあくまでもus+syであり、上記の例では、CPUは4~6%程度しか利用されていないことになります。
I/Oウェイトとは、I/OがボトルネックになってCPUが有効に使えていない状況を示すだけで、実際にCPUが使用されているわけではありません。
I/O負荷とCPU負荷を同時に発生させてみる
先ほどの例ではI/O負荷を発生させましたが、CPUはほとんど使用されていませんでした。
その為、CPUに負荷をかけた状態でddを実行するとどうなるかを試してみます。
CPUの負荷は、先ほどの負荷プログラムによって発生させます。今回は4つ並列で負荷をかけてみます。
# ./loadtest.pl 4
するとvmstatの表示でCPU使用率が100%になることが分かります。
procs -----------memory---------- ---swap-- ----io----- --system-- ------cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 1744948 9608 57576 0 0 0 0 25 28 0 0 100 0 0
4 0 0 1742304 9748 58956 0 0 0 0 226 171 18 1 81 0 0
4 0 0 1742304 9748 58956 0 0 0 0 1005 509 100 0 0 0 0
4 0 0 1742304 9748 58956 0 0 0 0 1005 507 100 0 0 0 0
次に、別の端末から先ほどと同様にddを実行します。
# dd if=/dev/zero of=test bs=1M count=512 oflag=direct
512+0 records in
512+0 records out
536870912 bytes (537 MB) copied, 3.87792 s, 138 MB/s
すると、CPU使用率は100%であるにもかかわらず、特に書き込みの速度は変わりません。これから推測できるのは、CPU負荷が高いからと言って必ずしもI/Oが遅くなるわけではなく、CPU負荷とI/O負荷は別物であるという事です。
ちなみに、負荷プログラムとddの両方が実行されている状態のvmstatを見ると、先ほどはI/Oウェイトが95%~96%と非常に高かったにもかかわらず、今回はI/Oウェイトが0%であり全く発生していないことが分かります。
procs -----------memory---------- ---swap-- -----io----- --system-- ------cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 0 1741692 9812 58956 0 0 0 0 1006 514 100 0 0 0 0
4 1 0 1741064 9812 58956 0 0 0 134144 1270 861 92 8 0 0 0
4 1 0 1741064 9812 58956 0 0 0 148480 1294 887 96 4 0 0 0
4 1 0 1741064 9812 58956 0 0 0 146432 1290 878 94 6 0 0 0
4 0 0 1741692 9816 58956 0 0 0 95232 1193 760 95 5 0 0 0
つまり、負荷プログラムがCPUを利用していたことから、I/O負荷によってCPUが有効に使えないという事態を回避できたわけです。
よく、I/Oインテンシブなソフトウェアと、CPUインテンシブなソフトウェアを、ひとつのサーバ内に同居させるとリソースの有効活用になる、というのを感覚的につかんでもらえるのではないでしょうか。
なお、上記の状態では実行中プロセスが4、I/O待ちプロセスが1になっており、この状態が続くとロードアベレージは5になります。
I/O負荷に関するまとめ
- CPU使用率とI/O負荷は別々のものである
- 大量の書き込みを行うと、ioのbiやboが上昇する
- CPU使用率が低い状態でI/O負荷が高まると、I/Oウェイトが上昇する
- CPU使用率が高い状態であればI/O負荷が高まってもI/Oウェイトは上昇しない
CPU使用率
次に負荷の原因がユーザプログラムにあるのか、システムにあるのか、はたまたI/Oにあるのかを、vmstatを使用して切り分けします。
先ほどの負荷プログラムをもう一度起動してみましょう。
# ./loadtest.pl 4
vmstatで確認すると、CPU使用率のうちusが100%となっているため、ユーザプロセス内の負荷であることが分かります。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
~略~
4 0 90376 1712576 7088 27240 0 0 0 0 1004 508 100 0 0 0 0
4 0 90376 1712576 7088 27240 0 0 0 0 1005 510 100 0 0 0 0
つまり、I/Oは全く使用しておらず、システムコールなども使用していませんので、ユーザプロセス内で計算処理を行っているなどの状況と考えられ、CPUの高速化で状況が改善できます。
次に、先ほどの負荷プログラムに引数を追加して実行します。引数に1と指定することで、先ほどの負荷プログラムはopen/closeシステムコールを呼び出します。
# ./loadtest.pl 4 1
この状態のvmstatを見ると、次はユーザとシステムの両方でCPUが使用されていることが分かります。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 90300 1709972 7336 27968 0 0 0 0 1004 914 45 55 0 0 0
4 0 90300 1709972 7336 27968 0 0 0 0 1004 915 45 55 0 0 0
つまり、I/Oは全く使用しておらず、キャッシュの効果がある状態でファイル操作を行っていたり、ネットワーク処理を行っていたりという状況が考えられます。このような場合にはCPUの高速化のほか、ネットワーク設定の改善、OSのチューンナップなどで状況が改善できます。
さいごに
vmstatコマンドは非常に奥ゆかしいコマンドであり、Linuxの動作を理解するためには必須のものといえます。
また、I/OウェイトとCPU負荷の関係性を正しく理解することも大変重要です。
サーバ会社的には高性能なサーバをたくさんの借りていただくほうが収益にはつながりますが(笑)、インフラエンジニアのプライド的には、正しいサーバの状況把握をして、適切なリソース確保と、快適なサーバ環境の構築してもらえるほうがいいので、ぜひ参考にしてもらえれば幸いです。