近年のデータベースはよく「最新のインメモリ技術を採用して高速化」などという宣伝が出回っている。
参考: 既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.1
参考: SQL Server 2016の概要とIn-Memory OLTP の改善点(前編)
従来のデータベースだって世の中のほぼすべてのソフトウェアも最終的には(キャッシュ)メモリの中で計算処理をしているわけで、何をもってして「インメモリ技術」と呼ぶのか誤解を招いているケースが身の回りで多発していた。
ディスクDBの時代
昔、例えばOracleV2が発売した1979年では、NECからPC-8001が発売され、市販されるコンピュータのメモリは64KBとか48KBほどだった。エンタープライズ製品であればMB級のものもあるだろうとは思うがお値段も相当のものだった。
会社の業務を回すにあたって、全データが64KBに収まる前提でアーキテクチャを組むなんて考えられなかった時代なので、商用DBは必然的にデータはハードディスク等に収める前提になり、メモリはそれに対するキャッシュ・バッファとして使うアーキテクチャを取っていた。
ディスク上のDBとキャッシュ・バッファとしてのメモリをうまく活用する方法はこれまでの記事で取り上げて来たように、ページ・WAL・Undo/Redoログなどなど様々な要素が複雑に絡み合っている。
そのため、速度を稼ぐためには様々な工夫が為されてきた。
インメモリDBの時代
そのあたりのボトルネックを詳細に調査した論文がSIGMOD2008のStavros HarizopoulosらのOLTP Through the Looking Glass, and What We Found Thereである。
この論文では典型的なディスクDBの中で発生しているオーバーヘッドの詳細に踏み込んで、機能を削いだり再設計することでどこまでパフォーマンスが上がりうるかというベンチマークをとっている。
衝撃的な図を引用すると
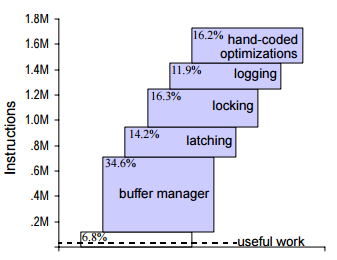
なんとデータベースの行っている作業のうち、本当に仕事に寄与しているのは6.8%で、他のほとんどのCPUパワーをバッファ管理やラッチやログやらに食われているというものである。
- データは全部メモリに置く
- ディスクからのリカバリは諦める
- シングルスレッドでトランザクションを実行する
というように様々な事を一気に諦めたら効率が20倍ほどになった、と報告している。
インメモリDBの論文
インメモリDBの考え方自体は1992年のHector Garcia-MolinaらによるMain Memory Database Systems: An Overviewの中で登場している。この論文には大まかには、ディスクDBからインメモリDBになればバッファ管理周りが不要になり、ページにとらわれないデータ構造をよりアグレッシブにCPUに最適化していくことができる旨が書かれている。
最近の論文だとVLDB2016のPer-˚Ake LarsonらによるTutorialの[Modern Main-Memory Database Systems]
(http://www.vldb.org/pvldb/vol9/p1609-larson.pdf)が短くて良くまとまっている。ページを使わないのでARIESスタイルのリカバリを使わなくなり、Undoログが要らなくなってRedoのみを保存すれば良い。
HekatonのBw-TreeやMass-Treeといったマルチコア環境向けに特化した高速B+ツリーの亜種を紹介し、更にはボトルネックがCPUに移るため従来のいわゆるボルケーノスタイルの操作抽象化がボトルネックになるのでJITコンパイルすることの必要性を論じている。
他にはカーネギーメロン大学の2016年のDatabase Systemsの講義資料も素晴らしい。最近のインメモリDBによく出てくる論文をまとめて英語の講義映像も含めて載っている。学生の演習課題がBw-Treeの実装だったりPelotonへの独自改造だったりと非常に激しい。
今日は個別の実装には触れず、ディスクDBからインメモリDBへの大きな潮流を紹介した。
伝統的なページ管理によるDBはアカデミックの分野では近年あまり注目されず、圧倒的な性能を誇るインメモリDBの論文が多い。
今後はインメモリDBとして注目しておきたいトランザクションエンジンについて説明する。