はじめに
Livesense Advent Calendar 2015(その2) 、13日目を担当します、ktmgです。
ふだんはSEOなどやっております。
さて、Advent Calendar 2015。
「なんかエンジニアさんたちが楽しそうなことやってるなー」とハタから眺めていたのが昨年。
今年は職種不問にしたからなんか書け、という @masahixixi さんの指令を受け、はじめて投稿させていただきました。
本記事では「非エンジニアでもできる簡単スクレイピング 」というテーマにからめて、
- Google SpreadSheetの便利な関数:9
- Chromeの便利な機能:1(Copy XPath)
をご紹介します。
素材・完成形
http://qiita.com/advent-calendar/2014/livesense
昨年の Advent Calendar を素材に、投稿記事一覧のリストをXPATHで取ってきたいと思います。
要件は以下のとおりとしました。
- Google SpreadSheet の関数だけを使用
- A1セルに入力されたURLに応じて、すべての情報が更新される
- カレンダーページのtitleを出力
- 表を出力… 投稿日, 投稿者, アイコン, URL, 記事title, タグ
- タグが2つ以上の場合、カンマ区切りで出力
- 2つ以上の記事でつけられたタグがあればリストアップ、降順ソートで表示(※中間集計列あり)
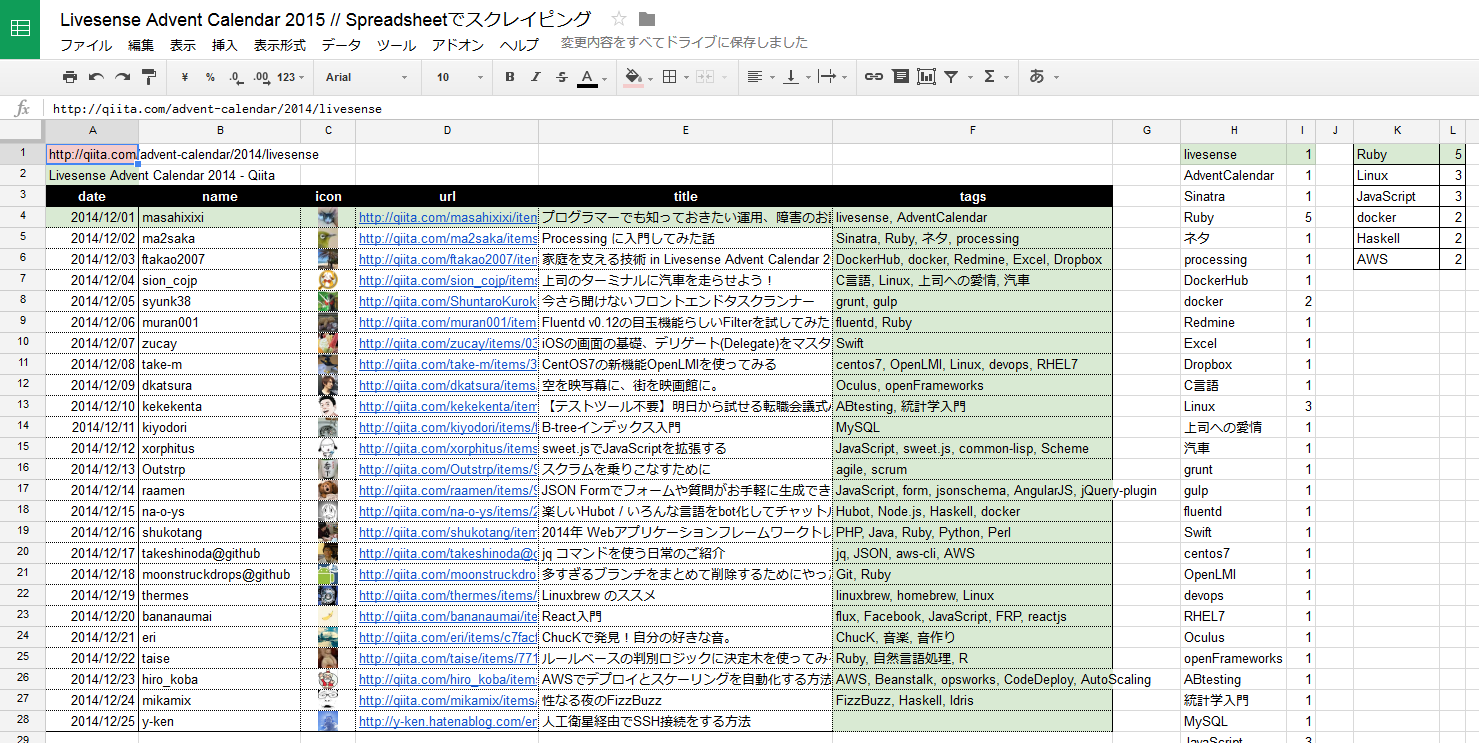
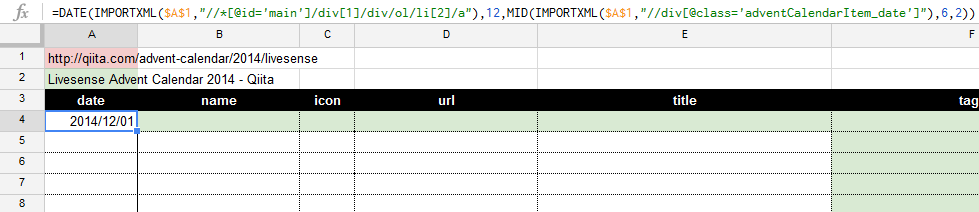
A1(赤いセル)にURLを指定します。
式が入っているのは、薄緑色のセルです。
事前準備
GoogleアカウントさえあればOK。
ログインしたら、新しいSpreadSheetを開きましょう。
ブラウザはGoogle Chromeがおすすめです。
理由はのちほど。
作業開始
1. titleタグの取得【A2】
★IMPORTXML関数
Google SpreadSheetには、IMPORTXMLという非常に便利な関数があります。
かつては1シートあたりの呼び出し回数が50 回までという制限がありましたが、新しいスプレッドシートでは制限がなくなりました。
=IMPORTXML(URL, XPathクエリ)
=IMPORTXML(A1,"//title")
使い方はシンプルで、上記のように第二引数にXPATHを指定するだけ。
<title>タグの中身がほしい場合は、"//title" と指定します。
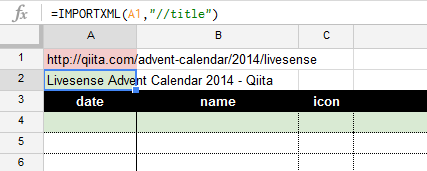
2. 日付の取得【A4】
date, name, icon, url, title はすべて、こちらの画像のエリアから取れます。

日付はほぼ固定。
ただし、今年以外のカレンダーにも対応するには、2014, 2015 といった西暦の情報が必要です。
URLからMID関数で切り取るのが楽ですが、あえてパンくずから取ってみましょう。

この 2014 を指定するXPATHを記述します。
おや、非エンジニアにもできると言っておきながら、なんだかハードルが高い?
心配はご無用です。Google Chromeのステキ機能をご紹介しましょう。
★Copy XPath
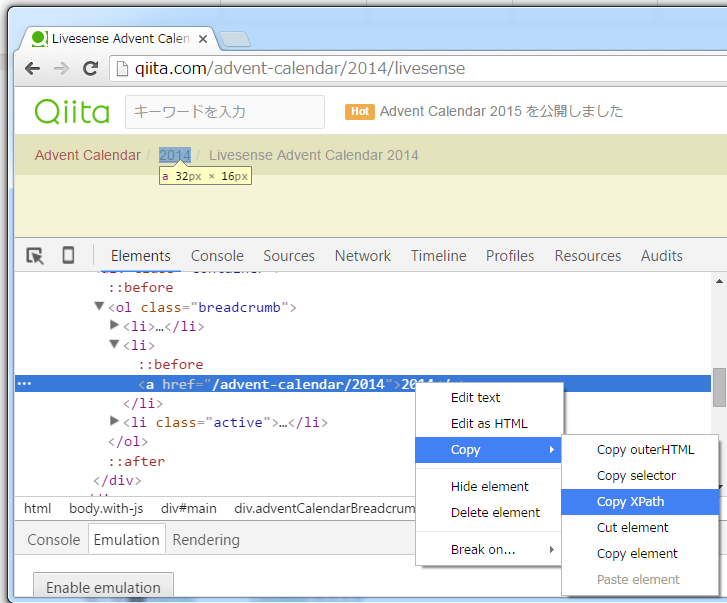
Chromeの「検証」機能(Ctrl+Shift+I)を立ち上げ、
必要な箇所を選択 → Copy → Copy XPath をクリック。
クリップボードに //*[@id="main"]/div[1]/div/ol/li[2]/a というデータが入ります。簡単!
ダブルクオートがSpreadSheetの引数とぶつかってしまうため、そこだけシングルクオートに変更してください。
=IMPORTXML($A$1,"//*[@id='main']/div[1]/div/ol/li[2]/a")
これで無事、"2014" という文字列が取得できました。
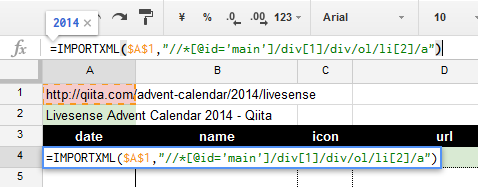
慣れてきたら手打ちで書いてみるのもおすすめです。
id名やclass名を指定することで、より短い記述にすることができます。
さて、日付の続き。
せっかくSpreadSheetを使うので、文字列ではなく、DATE関数を使ってシリアル値にしてあげると美しいと思います。
=DATE(IMPORTXML($A$1,"//*[@id='main']/div[1]/div/ol/li[2]/a"),12,MID(IMPORTXML($A$1,"//div[@class='adventCalendarItem_date']"),6,2))
★ARRAYFORMULA関数
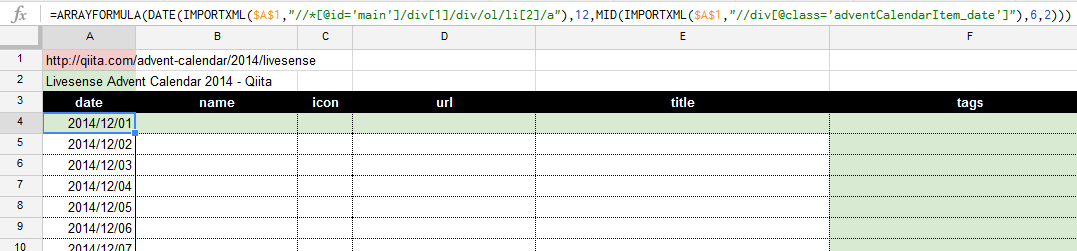
しかしここで、2日目以降の日付が取得できていないことに気づきます。
記述したXPATHに該当するデータが複数ある場合、通常、IMPORTXMLは配列数式のかたちですべてを展開してくれるのですが、取ってきたデータを加工してしまうと、配列が展開されず、式を入力したセルにのみデータが反映されます。
このようなケースで、展開を明示的に指示したい場合、ARRAYFORMULA 関数を使います。
数式の編集中に Ctrl+Shift+Enter を押すことでも入力できます。
=ARRAYFORMULA(配列数式)
=ARRAYFORMULA(DATE(IMPORTXML($A$1,"//*[@id='main']/div[1]/div/ol/li[2]/a"),12,MID(IMPORTXML($A$1,"//div[@class='adventCalendarItem_date']"),6,2)))
これで、25日までのすべての日付が取得できました。(A5以下の白いセルには式を入力していません)
※1日~25日まで埋まっていないカレンダーの場合、日付がずれますが、その対応は行わないこととします> <
3. ユーザー名の取得【B4】
=IMPORTXML($A$1,"//div[@class='adventCalendarItem_author']/a/img/@alt")
次はユーザー名。
こちらは簡単で、<img>タグのaltを使用しました。
alt, src, href など、タグの属性を指定する場合は@を使います。
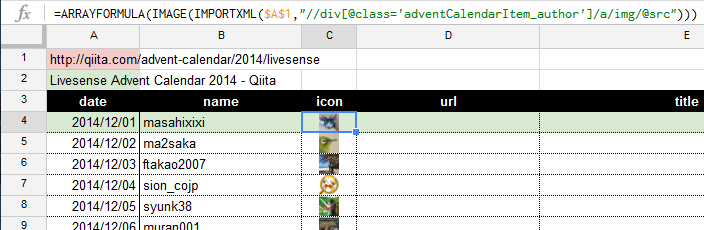
4. アイコンの取得【C4】
=IMPORTXML($A$1,"//div[@class='adventCalendarItem_author']/a/img/@src")
画像のURLを取得します。
ただこれだけでは面白くないので、IMAGE関数を使って、アイコンをそのまま表示してみましょう。
★IMAGE関数
=IMAGE(URL, [モード], [高さ], [幅])
=ARRAYFORMULA(IMAGE(IMPORTXML($A$1,"//div[@class='adventCalendarItem_author']/a/img/@src")))
IMAGE 関数の使い方は簡単で、URLを指定するのみ。
[モード], [高さ], [幅]は省略できます。
DATE関数と同じく展開が阻害されてしまうので、数式をさらにARRAYFORMULA関数で囲みました。
5. URL、記事タイトルの取得【D4, E4】
URLは
=IMPORTXML($A$1,"//div[@class='adventCalendarItem_entry']/a/@href") 、
記事タイトルは
=IMPORTXML($A$1,"//div[@class='adventCalendarItem_entry']/a") 。
もう慣れてきましたね。
6. 記事につけられたタグの取得【F4】
ここで応用編。
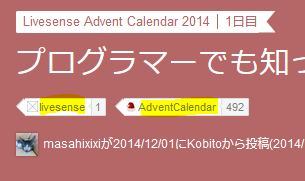
記事についたタグの情報を取ってきたいのですが、この情報はこれまで参照してきたA1セル(カレンダー)にはありません。
取ってきたいのは、各記事ページの上部にあるこれらのタグ。
すでに各記事のURLは取得済みのため、tagsのF列では、IMPORTXMLの第一引数をD列に指定します。
=IMPORTXML(D4,"//div[@class='tagIcon_name']")

… おっと。
タグは取得できたものの、2つ以上ある場合、下に展開されてしまいました。
★JOIN関数
展開したくない配列数式は、JOIN 関数でまとめてしまいましょう。
JOIN関数は、指定した区切り文字を使用して、1次元配列の要素を結合してくれます。
今回は「, 」を区切り文字に指定しました。
=JOIN(区切り文字, 値または配列1, [値または配列2, ...])
=IFERROR(JOIN(", ",IMPORTXML(D4:D28,"//div[@class='tagIcon_name']")),"")
Qiita以外のサイト(外部ブログ等)でAdvent Calendarに参加するケースも見受けられたため、IFERROR関数で「エラーの場合は空白」の処理を加えています。
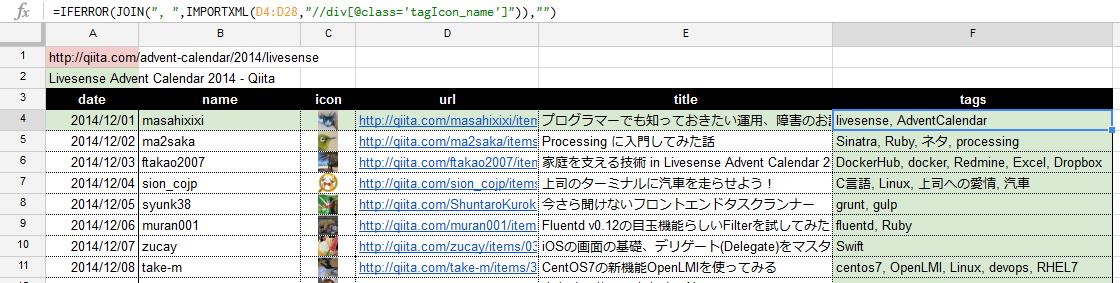
整形完了。
記事のタグがカンマ区切りで取得できました。
7. タグを集計【H1, I1】
うん、ちょっと息切れしてきました。
ここからやや軽めに流させてください。
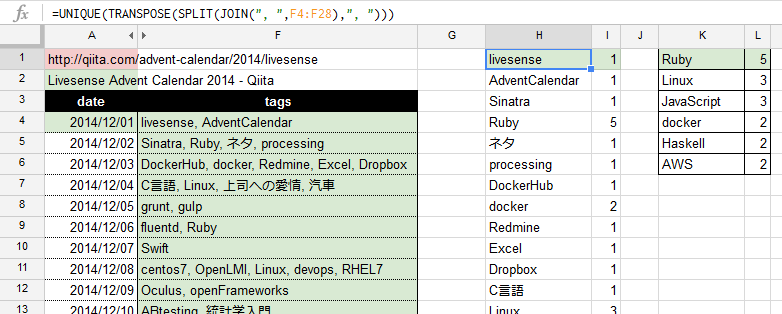
まず、先ほども使ったJOIN関数で、すべての記事のタグ(F4:F28)をひとつの配列に入れてしまいましょう。
livesense, AdventCalendar, Sinatra, Ruby, ネタ, processing, DockerHub, … みたいな状態です。
★SPLIT関数
=SPLIT(テキスト, 区切り文字, [各文字での分割])
結合したものを、今度はすぐに展開。
SPLIT 関数は、指定した文字列の前後でテキストを分割し、同じ行に展開してくれます。
★TRANSPOSE関数
SPLITにより同じ行に展開された配列ですが、このあとで同じ列の重複を削除するUNIQUE関数を使いたいため、TRANSPOSE 関数を使い、行と列を入れ替えます。
=TRANSPOSE(配列または範囲)
★UNIQUE関数
そして UNIQUE 関数。重複を削除し、指定したソース範囲内の一意の行を返します。MS Office Excelにもぜひ入れてほしい関数のひとつです。
=UNIQUE(範囲)
配列をこねくりまわし、ようやくタグの一覧がH列に揃いました。
=UNIQUE(TRANSPOSE(SPLIT(JOIN(", ",F4:F28),", ")))
隣のI列で、COUNTIFを行います。
=ARRAYFORMULA(COUNTIF(TRANSPOSE(SPLIT(JOIN(", ",F4:F28),", ")),INDIRECT("H1:H"&COUNTA(H:H))))
8. タグを集計 つづき【K1】
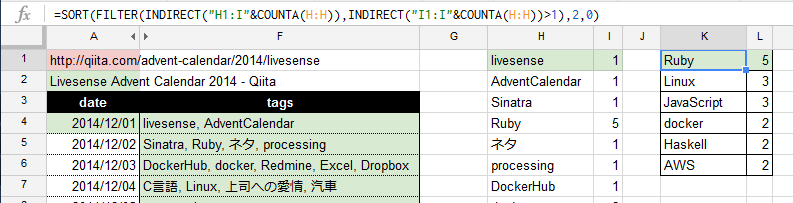
いよいよ次で最後。1枚のカレンダーの中で、2回以上使用されたタグを抽出します。
★FILTER関数
FILTER 関数は、ソース範囲をフィルタ処理して、指定した条件を満たす行または列のみを返します。
ここでは、COUNT > 1 の条件に合致する行のみをフィルタしました。
SpreadSheetは同時に複数のメンバーが編集できるのが魅力のひとつですが、フィルタの設定も共有されてしまうのがたまに面倒だったりしますよね。そんなときは、FILTER関数を使って一時的な作業用シートを作ってしまうのも便利です。全体をコピーするよりも、かなり動作が軽くなります。
=FILTER(範囲, 条件1, [条件2, ...])
★SORT関数
2以上のタグを、降順に並び替えます。SORT 関数は、範囲に指定したテーブルを、指定の列の昇順/降順で並び替えてくれる関数です。
今回は「2列目を、0(降順)で」と指定しました。
=SORT(範囲, 並べ替える列, 昇/降, [並べ替える列2, 昇順2, ...])
これで完成! おつかれさまでした。
=SORT(FILTER(INDIRECT("H1:I"&COUNTA(H:H)),INDIRECT("I1:I"&COUNTA(H:H))>1),2,0)
リブセンスのAdvent Calendar、昨年のトレンドは以下の通りとなりました。
| Tags | num |
|---|---|
| Ruby | 5 |
| Linux | 3 |
| JavaScript | 3 |
| docker | 2 |
| Haskell | 2 |
| AWS | 2 |
今年は何か変わっているでしょうか?
クリスマスが過ぎたらこっそりチェックしてみようと思います。
「企業・団体」のカレンダーごとに特色を探してみるのも面白いかもしれません。
おわり!
作業過程を記事にまとめるって、なかなかに重労働ですね。
知っているつもりだった関数も、ヘルプを読んだら新しい発見があるなど、勉強になりました。
機会をくれた @masahixixi さん、ありがとう。
明日は @zucay さんの記事です。
お楽しみに!