結論
標準入力かファイル入力を使おう。
環境
以下説明環境をzshかつOSXとします。(全環境を調べきれない)
問題点
ImageMagickで文字が書かれた画像を出す場合は以下のようにします。
$ convert label:'Hello, World!' out.png
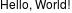
フォントや文字の大きさ、行間など、かなり細かく設定できます。
公式のUsageには文字にメタリックなエフェクトをつけたりもしています。
http://www.imagemagick.org/Usage/fonts/#metallic
label:の他にtext、caption:、-annotate、-drawなどを使っても、それぞれ微妙に意味が違いますが、文字が書かれた画像を書き出すことができます。
大抵の文字は、これで文字が画像化できたわーいで終わるのですが、一部の文字がまじると問題が起こります。
以下の文字は期待通りになりません。
$ convert label:'%w%h Hello, World!' out.png
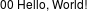
%w%hを期待しているのに、何故か生成された画像には00と表示されています。
また、以下の場合はコマンドが失敗します。
$ convert label:'% Hello, World!' out.png
convert: unknown image property "% " @ warning/property.c/InterpretImageProperties/3420.
imagemagickには特殊な意味を持つ文字が複数あるのが原因です。
imagemagickで文字列を画像化する場合は、特殊文字のエスケープを考慮しないと、思わぬ入力で想定外の画像が出来上がってしまうか、最悪生成できません。
特殊文字一覧: http://www.imagemagick.org/script/escape.php
この表をにらめっこしながらエスケープ処理をバグなく実装するのは骨が折れる作業になりそうですが、
手軽で、入力文字をそのまま画像化する方法が存在します。
それは標準入力か、ファイル入力を使う方法です。
解決手法
convertコマンドは、標準入力やファイル入力を入力文字として画像化することができます。
文字を画像化するコマンドの場合、標準入力やファイル入力を使うとエスケープが、一切必要なくなります。
標準入力の場合
$ echo -n '% Hello, World!' | convert label:@- out.png
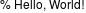
@は「これ以降はファイル入力を受け付けますよ」という記号で、-は標準入力を表しています。
ファイル入力の場合
$ echo -n '% Hello, World from file!' > hello.txt
$ convert label:@hello.txt out.png

@の後にファイル名を並べることで、そのファイルの内容を入力文字列として読み取ってくれます。
この方法は公式サイトにも記載されています。
スクリプトの例(Ruby)
#! /usr/bin/env ruby
require 'open3'
Open3.capture3("convert", "label:@-", "out.png", :stdin_data => "% Hello, World from script!")

さらなる問題
実は特殊文字問題はこれで終わりません。
例えば\tや\v \bなどのテキストデータとしての特殊文字も、?と表示されたり、最悪odコマンドの出力のようにバイナリ表示になってしまいます。(フォントによるかも?)
ASCII文字すべてを一つづつ画像化してみる、カンタンなスクリプトを実行してみます。
#! /usr/bin/env ruby
require 'open3'
[*0x00..0x7F].each do |ch|
Open3.capture3("convert", "label:@-", "out-#{ch}.png", :stdin_data => ch.chr)
end
説明が難しいので、実際に実行してみて確認してほしいのですが、
0x00-0x1Fと0x7Fで?だったり0x00000000: 00だったりすることが確認できます。
よって、これらは除外するとよさそうです。
特にヌル文字\0は途中にあればそれ以降は表示されなかったり、最後にあればコマンドが異常終了して生成できないという問題があります。
しかしながら、ヌル文字\0は文字列の終わりを意味したり、git ls-files -zなどのように文字の区切りを表していたりと、状況によって意味が異なったりするので厄介です。
最低でも最後にあるものだけは削除したいところ。
また例外として、改行コードはそのまま改行されたように表示してほしいことが多いはずなので、改行コードは除外せずそのままにします。
さらにこれは好みによるのですが、ANSIエスケープシーケンスによる色付けを削除したり、\bでちゃんと前の文字を削除もしたり、\tはスペースとして扱う等、
オプションで処理を付け加えるとよさそうです。
シェルの場合
$ echo -ne "a\tb\nc\vd" | sed -e $'s/\e\[[0-9;]*m//g' | col -b | tr -d '[\000-\011\013-\037]' | convert label:@- out.png
スクリプト(Ruby)の場合(あんまり自信ない)
#! /usr/bin/env ruby
require 'open3'
text = "a\tb\nc\vd"
# ANSI Color削除
text.gsub!(/\e\[[0-9;]*m/, '')
# BSをうまいこと処理
text.gsub!(/.[\b]/, '')
# 残った特殊文字を削除("\n"は除く)
text.tr!("\000-\011\013-\037", '')
Open3.capture3("convert", "label:@-", "out.png", :stdin_data => text)
ここまですれば、(フォントに文字さえあれば)大抵の文字は画像化できると思います。
こういうやりかたもあるよという方はご一報ください。
まとめ
- imagemagickで文字列を画像化したいときは特殊文字に気をつけよう。
- 特殊文字はエスケープできるけど、実装が面倒。
- 標準入力かファイル入力がカクジツでカンタン
- imagemagickの特殊文字を対処したあとは、テキストの特殊文字もオプションで対処しよう
- 各言語のimagemagickバインディング系はわかりません!