この記事はフューチャーアーキテクト Advent Calendar 2015の12/5です。
Rustとは、Mozillaが開発しているプログラミング言語です。
Rustは低レイヤ用のシステムプログラミング言語ですが、クロージャーやトレイトなどの今どきな機能を使えるという特徴があります。
最近、RustでもSIMDを使えるというのを知りました。
なので今日はRustのSIMDプログラミングを説明します。
SIMD
SIMD(Single Instruction Multiple Data)とは、複数のデータに対して同じ命令を適用する計算機構のことです。IntelのAVXやGPGPUの並列コンピューティングがこれに該当します。下にイメージ図を書きます。
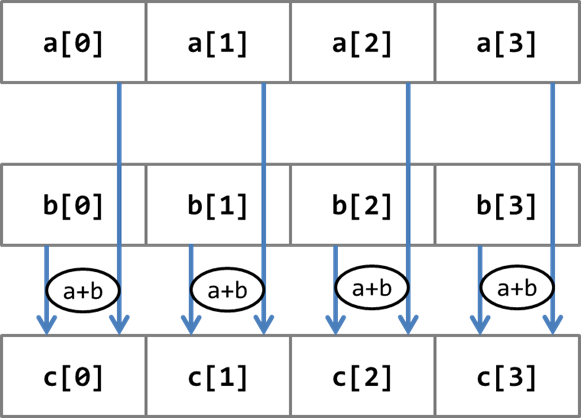
上図ではaとbの同インデックスの値を加算し、それぞれの結果をcに格納しています。このような計算をまとめて実行するのがSIMDです。
Intel CPUにはSSEやAVXという拡張機能があり、それをSIMDを使ったコンピューティングをサポートしています。
自分のCPUでSIMDが使えるかチェックする
自分のCPUにSIMDの拡張機能が搭載されているか調べてみましょう。
ターミナルを開いて「cat /proc/cpuinfo」と実行するだけです。
processor : 7
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R) Core(TM) i7-4770K CPU @ 3.50GHz
<省略>
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 fma cx16 xtpr pdcm pcid sse4_1 sse4_2 movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm ida arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid
bogomips : 6995.96
clflush size : 64
cache_alignment : 64
address sizes : 39 bits physical, 48 bits virtual
power management:
flagsのところにsse、avx、avx2などが記載されています。
なのでこのCPUはSIMDの拡張機能が使える、ということです。
SIMD with Rust
さっそく、RustでSIMDを使ってみましょう。
準備
SIMDを使うためには、crate simdをインポートする必要がります。
見たところまだ開発中のようで、SIMDはSSEしかサポートしていないようですね。AVX使えないのは残念。
Cargo.tomlに以下を書くだけです。
simd = { git = "https://github.com/huonw/simd" }
お試し実行
単精度浮動小数点f32をSIMDで加算してみましょう。
extern crate simd;
use std::ops::Add;
fn main() {
let a = simd::f32x4::new(0.01, 0.02, 0.04, 0.08);
let b = simd::f32x4::new(0.11, 0.22, 0.44, 0.88);
let dst = a + b;
println!("Result: {:?}",
(dst.extract(0),
dst.extract(1),
dst.extract(2),
dst.extract(3)));
}
結果は以下の通り。ちゃんと計算されていますね。
Result: (0.12, 0.24, 0.48, 0.96)
本当にSIMDされてるのか?
と思ったのでアセンブリを見て確認しましょう。
Rustのコンパイルにはrustcコマンドを使用します。
以下のようにオプションを指定すると、アセンブリやLLVM IRを見ることができます。
ちゃんとSSEの命令を呼んでいるか調べてみましょう。
rustc src/main.rs --emit asm -Ltarget/debug/deps -o main.s
movaps %xmm0, -24(%rsp)
movaps %xmm1, -40(%rsp)
movaps -24(%rsp), %xmm0
addps -40(%rsp), %xmm0
addpsやmovapsはSSEの命令です。
ちゃんとSIMD化してくれていることがわかりました。
速いの?
試しに、とてつもなーく長い配列のsaxpyを実行してみましょう。
適当に乱数を発生させ、それをforループで乗算とSIMDで乗算の2パターンを書いてみます。
ソース
extern crate rand;
use rand::{Rng, SeedableRng, StdRng};
fn main() {
let seed: &[_] = &[1, 2, 3, 4];
let mut rng: StdRng = SeedableRng::from_seed(seed);
// 配列のサイズ
const SIZE: usize = 1024 * 1024 * 512;
let a: f32 = rng.gen::<f32>();
let mut x: [f32; SIZE] = [0.0; SIZE];
let mut y: [f32; SIZE] = [0.0; SIZE];
let mut z: [f32; SIZE] = [0.0; SIZE];
// 乱数で初期化
for i in 0..SIZE {
x[i] = rng.gen::<f32>();
y[i] = rng.gen::<f32>();
}
for i in 0..SIZE {
z[i] = a * x[i] + y[i];
}
}
extern crate rand;
extern crate simd;
use rand::{Rng, SeedableRng, StdRng};
fn main() {
let seed: &[_] = &[1, 2, 3, 4];
let mut rng: StdRng = SeedableRng::from_seed(seed);
// 配列のサイズ
const SIZE: usize = 1024 * 1024 * 512;
let a = simd::f32x4::splat(rng.gen::<f32>());
// 初期化用
let zero = simd::f32x4::splat(0.0);
let mut x: [simd::f32x4; SIZE / 4] = [zero; SIZE / 4];
let mut y: [simd::f32x4; SIZE / 4] = [zero; SIZE / 4];
let mut z: [simd::f32x4; SIZE / 4] = [zero; SIZE / 4];
// 乱数で初期化
for i in 0..(SIZE / 4) {
x[i] = simd::f32x4::new(
rng.gen::<f32>(),
rng.gen::<f32>(),
rng.gen::<f32>(),
rng.gen::<f32>());
y[i] = simd::f32x4::new(
rng.gen::<f32>(),
rng.gen::<f32>(),
rng.gen::<f32>(),
rng.gen::<f32>());
}
for i in 0..(SIZE / 4) {
z[i] = a * x[i] + y[i];
}
}
結果
| プログラム | 実行時間 |
|---|---|
| normal | 3.682s |
| simd | 3.590s |
10241024512程度だと、あまり速度差が出ないですね。。
ビルドには「--release」オプションを指定したため、互いに結構最適化されているのかもしれません。
おわり
RustでSIMDをやってみました。
SIMDがサポートされるということは、Rustは数値計算も視野にいれて開発されているということ。
今後、いろいろな分野でRustが使われる可能性が増えるかもしれませんね。