はじめに
これは昔(2010年頃)自分が使っていた高速化技法について書いたものです.
今となってはレガシーだったり,通用しないものもあるかもしれませんが,こういう知識も無くなってしまったり,自分も忘れてしまう気がしたので,メモ代わりに書いておきます.
ただ言えることは,「最適化はするな」ということです.最適化すると,保守性が大幅に失われる危険性があります.そして,これから書く項目を1つ1つ行って,高速化できたとしても,せいぜい2倍程度です.ただその2倍程度の速度も欲しい!そのためには悪魔に魂と保守性を売る!という方はご覧ください.これらの高速化は割といろいろな言語に当てはまることも多いですが,大体C++で書くことを念頭に置いていただければ,幸いです.あと,個人的には競技プログラミングだったり,計算科学をやっていた時期に見つけた経験則なので間違ってる場合もあります.
コンパイルオプションをこだわれ
危険度:☆
応用性:☆☆☆
$ g++ -O3 -mtune=native -march=native -mfpmath=both main.cpp
一番リーズナブルのくせに効果の高いやつです.
-O3:gccの基本の最適化オプションです.普通にコンパイルすると-O2レベルですが,その一段上です.
-mtune=native -march=native:gccが吐き出すバイナリファイルをコンパイルしているローカルマシンに最適化してくれます.(大体そんなイメージ)
-mfpmath=both:普通の浮動小数点演算とsseを使った小数点演算を使ったコードを吐くようになります.
あんまり資料自体は漁ったことがないのですが,高速化が必要なときはとりあえずやっておくおまじないのようなオプションです.個人的には,-mtune=native -march=nativeが一番効いた経験が多く,体感1.2倍くらいの速度になることが多いオプションです.
-mfpmathはあまりお世話になることが少ないオプションではあります.これが効いたことがあったのはmplayerとかffmpegとかの映像系で浮動小数点演算の多いライブラリ系でした.自分で組んだものにそういうものが少なかったのであまり早くなった記憶はないです.
-O3は割と危険です.個人的な経験だけでいうと,-O3オプションをつけたらビルドできなくなったプロダクトがあったり,ビルドはできても,いきなりコアダンプ吐いてプログラムが強制終了することもありました.それくらい,危険なオプションだったり,逆に指定すると遅くなることもちらほらありました.
上の3つのオプションは,gccが入っていれば,割と楽に試せるのでお勧めです.しかし,動作確認はきっちりしたほうが良いです.先ほど書きましたが,プログラムが動かなくなったこともあったので,少々注意が必要なオプションです.
コンパイラを変えろ
危険度:☆
応用性:☆☆
早い話がIntel Compilerを使え.ということです.速くなります.昔はLinux版は非商用に限り無料だったはずなんですが,今調べてみると出てきませんね・・・
ただ注意するべき点もあり,「ノウハウが少ない」という欠点があります.コンパイルできなくてハマって失敗しても,それほど知見が共有されていないので,意外に手間取ることも多いです.あとMakefileやソースが対応していないことがあります.昔,最新のintel compilerを入れたら,まだffmpegが対応しておらず,コンパイルできなくて,Makefileとソースコードをいじった記憶があります.
これは今はどうかわかりませんが,C++の拡張構文の対応が遅いことがあります(昔はそうだった).そのため,モダンなコードを書いていると,intel compilerが非対応なことによってC++の古い構文を強制されることもあり,可読性が下がることもあるのでご注意ください.
ファイルは一括で読み込め
危険度:☆
応用性:☆☆
大体のイメージなのですが,
int main()
{
ifstream ifs("file.txt");
while(!ifs.eof()){
int n;
ifs >> n;
/* 何らかの処理 */
}
}
というようなコードを
int main()
{
ifstream ifs("file.txt");
vector<int> data;
while(!ifs.eof()){
int n;
ifs >> n;
data.push_back(n);
}
for(int i:data){
/* 何らかの処理 */
}
}
と書き換えます.上のコードは若干読み込み方がまだ雑ですがありますが,それでも早くなる時は早くなります.基本的にファイルIOをつかさどる部分は局所化しておいたほうが良いことが多いです.なぜか?と言われるとちょっと説明できないのですが,たぶんIO待ちのせいで内部のパイプラインがストールするのでしょうか?あまり解説もないので正確なことは言えませんが,困ったときには一括で読むことを考えると早くなることがあります.
問題があるとすると,読み込み部分のコードが煩雑になることがあります.これも仕方のないことなのですが,最初に"1行読み込んで,1行処理する"という処理を書いていた場合,下の形式に書き換えるのが意外に面倒だったり,バグを生み出すことがあります.その意味では少し注意の必要なテクニックの1つです.
これは逆の出力もしかりで,「ファイルに一括で書き込め」ということも言えます.これも同じように一括でファイルに書き出すほうが速いです.
でも,実際のところ競技プログラミングとかではあまり見ないテクニックだったりします.というのも大容量ファイルを扱うような系にしか置きません.そのため,計算科学のような,処理するデータのIOがボトルネックになるような場合にのみ,このテクニックが必要になることがあります.
ヘッダにすべてのクラスを実装しろ
危険度:☆☆
応用性:☆☆☆
たぶん嘘テクです.全てのコードを1つのソースに書くほうがプログラムのほうが速い.ということを昔,どこかで読んだことがありました.
普通C++でプログラムを書くとき,
.h:定義
.cpp:実装
を書くことが多いと思います.そうではなく,ヘッダファイルに実装まで全部書いたほうが速い.という話です.ざっくりいうと分割コンパイルするなということです.
よくよく調べてみると,翻訳単位の問題のようです.
分割コンパイルとリンケージ
http://www.cc.kyoto-su.ac.jp/~hxm/cstext/prog06.html
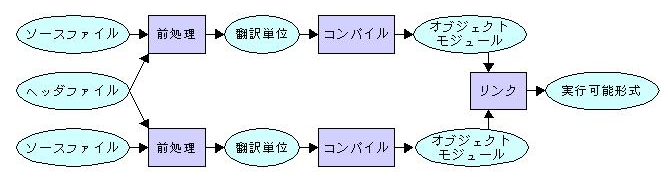
※リンク先から引用
この画像を見てもらうと分かりますが,分割コンパイルする場合,ソースコードをコンパイルし,オブジェクトファイルを生成します.そして,複数のオブジェクトをリンカでつなぎこみます.そのため,オブジェクトをまたいだソースコードの呼び出しは最適化されない.ということが分かります.
私がc++を書いてた頃は,このオブジェクトをまたいだ呼び出しは,iccの-ipoオプションで最適化され,重宝した記憶があります.しかし,gccにもltoというオプションでオブジェクトの翻訳単位を超えた最適化をするようです.
GCCの最適化オプション
https://cpplover.blogspot.jp/2013/07/gcc.html
ちょっと検証してみました.
#include<iostream>
using namespace std;
int f(int n){
int c = 0;
for(int i=1;i<=n;i++){
c += i;
}
return c;
}
int main(){
int n = 100000;
int p;
for(int i=0;i<n;i++){
p = f(n);
}
cout << p << endl;
}
#ifndef __TEST_H__
#define __TEST_H__
int f(int n);
#endif
#include"test.h"
int f(int n){
int c = 0;
for(int i=1;i<=n;i++){
c += i;
}
return c;
}
#include<iostream>
#include"test.h"
using namespace std;
int main(){
int n = 100000;
int p;
for(int i=0;i<n;i++){
p = f(n);
}
cout << p << endl;
}
1.cppは1つのソースコードで実装していますが,2.cppはソースコードを分割して,分割コンパイルしました.コンパイルは以下のようにしました.
$ g++ -O2 -o 1.out 1.cpp
$ g++ -O2 -c 2.cpp
$ g++ -O2 -c test.cpp
$ g++ -O2 -o 2.out test.o 2.o
時間計測の結果,
| 実行バイナリ | 実行時間[sec] |
|---|---|
| 1.out | 9.632 |
| 2.out | 10.140 |
となりました.という感じです.若干速くなってます.割と簡単にできる技ではあるのですが,コンパイル時間が長くなる.という厄介な点があります.コンパイルの翻訳単位が大きくなるので,コードを最適化する範囲が大きくなるので,時間がかかるようになります.
deleteするな
危険度:☆☆
応用性:☆☆☆
「メモリ解放しないでください.」
この一言に尽きます.実際こういうサイトがありまして,
C++ オブジェクトを new/delete するコスト
http://www.ohfuji.name/?p=360
Time(new) is 2.065sec.
Time(delete) is 2.35sec.
Time(function call) is 0.26sec.
というデータがあります.処理自体には0.26秒ですが,newには2.065秒,deleteは2.35秒かかってます.deleteの分だけ遅くなります.競技プログラミングや,その他,プログラミングコンテストは,コンテストが行われている時間が重要です.その時間にいかにCPUで処理を回すか.そう考えたとき,答えに結びつく処理ではないdeleteに時間をかける意味はないです.プログラムが終了された時に,OSに勝手にメモリの解放をしてもらうほうが無難です.逆に言えば,普通のサーバーでメモリリークが厳しい分野には使えないテクニックです.
newするな
危険度:☆☆☆
応用性:☆☆
前の話と若干矛盾はしていますが,newしないでください.できる限りnewは避けてください.競技プログラミングしかり,このような高速なプログラムを動かすコンピュータというのは限られます.そういうことを考えたとき,プログラムのポータビリティ性などは無視してよいです.そのため,メモリをできるだけ,削減したり,小さなメモリで動くような工夫などは不要です.プログラムを動かすマシンにのみチューニングすればよいです.そう考えると,処理Aに割り当てられるメモリ量は,ここが上限.というのは大体決まってきます.そうしたときにはnewするより,配列でとってしまうほうがメリットがあります.1つは,メモリのnew毎に待ち時間が発生しないこと.2つめはメモリの局所性が生かせること.キャッシュがメモリからロードする際に,ロードするメモリアドレスの近辺のデータをまとめて取ってきます.そのような動作をするため,出来る限り,メモリ領域は連続した領域を使うほうがキャッシュのヒット率があがり,高速に動作します.そうした場合,毎回,newして断片化したメモリ領域を使うより(もしくは連続が保証されていない領域を使うより),起動時に一気にメモリを確保して使いまわすほうがベターだったりします.そして,これはもう1つメリットがあるのですが,これは後述します.
1GB以上メモリを使うプログラムは組むな
危険度:☆
応用性:☆☆☆
これは本当に経験則なのですが,「1GB以上のメモリを使うプログラムは一気に動作速度が落ちる.」という個人的なジンクスがあります.これもおそらくなのですが,どうしても1GB以上のメモリを使うようになると,ハッシュの効率が悪いようです.C++では一部の計算結果をmapのなかにキャッシュデータとして管理するのが,非常に楽で速いです.しかし,1GB程度の大規模なハッシュになってくると,どうやらmapのデータの引き当て速度の劣化がひどくなり,そして,多くのデータを抱えているせいでキャッシュミスや,木の再構築に時間がかかるせいで,全体的な速度が遅くなる傾向にあるようです.そのため,出来るだけメモリ領域は1GB程度に抑えておくほうが,無難だなーと思うことが多々あります.
再帰するな
危険度:☆☆☆
応用性:☆
遅いので,再帰しないでください.理由はこの辺に書いています.
スタックと割り込み ―― プログラムが動く仕組みを知ろう
http://www.kumikomi.net/archives/2008/07/15stack.php?page=4
上記リンクを引用すると,関数呼び出しには以下の要素がスタックに詰まれます.
関数リターン時の戻り先アドレス
引き数
ローカル変数
テンポラリ変数(計算の途中結果を保存するためにコンパイラが生成する変数
それらのデータをスタック上にプッシュ・ポップするだけコストがかかります.そして,関数を呼び出すたびに関数フレームがメモリ領域が割り当てられ,キャッシュヒットも悪くなります.したがって,出来るだけ関数を呼ばないようにすると早くなります.-O2でコンパイルしたプログラムと,-O3でコンパイルしたプログラムをgprofileで計測してみると分かりますが,一部の関数のエントリポイントがなくなってたりします.脱関数化するというのも1つの高速化の手段ではありますが,それはコンパイラのオプションに任せて,再帰関数は手で直すほうが正確です.
ただプログラミングの難易度が上がります.2,3度やると割と分かるようになるのですが,最初できるようになるまで私もかかりました.したがって,何度か組んでみると良いかもしれません.
doubleは使うな
危険度:☆☆☆☆
応用性:☆
表題の「double使うな」は言い過ぎですが,本当に「doubleの精度が必要?」ということは頭に置いておいたほうが良いと思います.ざっくりとですが,doubleは1e+15~1e-15ぐらい.floatは1e+6~1e-6ぐらいの精度がある.ということを頭に入れておくと分かりやすかったりします.数値計算を主に行うようなプログラムであれば,30~40%速くなることもあるので,すごく雑な考え方ですが,doubleをfloatに置換しても結果が変わらなかったら,やってみてもいいんじゃないでしょうか.ただ高度に複雑な数式を扱っていると,その限りではないので,よく考える必要があります.
GCは自分で組め
危険度:☆☆☆☆☆
応用性:☆
あまり言いたくはないですが,「手を出さないほうが身のため」です.このチューニングをするのは,最終段階なので,手を尽くした後になります.今までのは,少し元のプログラムの原型を残しながら行うことができるのですが,これはかなりコードの構成が変わり,保守しにくくなります.これを行うとnewとdeleteを最小限に抑えることが出来るので,速度の向上が見込めます.
const int size = 5;
vector<Task> tasks = { Task(), Task(), Task(), Task(), Task()};
vector<bool> gc = { False, False, False, False, False};
int unused_min_index = 0;
int get_index(){
for(int i=unused_min_index;i<size;i++){
if(!gc[i]){
return i;
}
}
}
//new代わり
int index = get_index();
gc[index] = True;
Task* t = &tasks[index];
unused_index = index+1;
//delete代わり
gc[index] = False;
unused_index = min(unused_index,index);
ポイントとなる部分として,GCで管理したい実体のTaskと,そのindexを同時に管理する必要があります.それがずっとついて回ることになるのでかなり厳しいです.そのため,Taskの定義の中にindexを持たしてしまうほうがベターだったりします.
動作環境を把握せよ
危険度:☆
応用性:☆
動作させる環境によってプログラムの組み方が変わることがあります.競技プログラミングを例として挙げると,
- 3時間以内に問題が5問程度出題され,その中で解答するプログラムを解く形式.(ICPC形式)
- 問題発表時に問題の大枠のみ公開され,3カ月程度の開発期間を経て,大会の時に,具体的な問題を制限時間内に解く形式.(高専プロコン形式)
という2つがあります.(今はどうかわからないですが)
例えば,前者はGoogleCodeJamやJOI,ICPCやパソコン甲子園等が挙げられます.こういう出題形式の中で,「問題で与えられた数独を解け」という問題が出たとします.
そして,他社は高専プロコンのような形式で,「数独を解く」という課題のみ(制限事項等)が公開され,「実際にどんな数独を解くか」(どのマスにどの数字が入るか)というのは大会の時にしか解らない.という形式があります.
前者と後者では微妙にプログラムの設計が変わってきます.
どういうことか図で説明します.
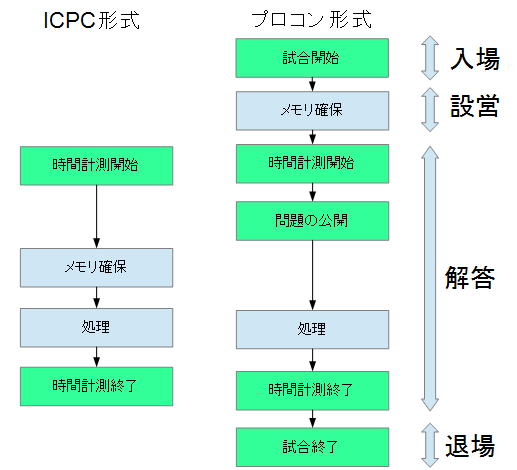
仮に,「数独を解く」のにメモリが10MB~30MB必要だと仮定します.
これをICPC形式で解こうと思うと別の要因が絡んできます.それは,「実行時間の制限」です.こういう形式のプログラミングコンテストではプログラムの実行時間が決まっています.その場合,テストケースによっては30MBのメモリ領域は不要の場合も多いです.そのため,このようなICPC形式の場合,メモリを都度取るような構成にしていても速度に関して問題が発生しないことが多いです.
しかし,一方で高専プロコン形式の場合,少し事情が変わってきます.何かというと高専プロコンの場合,「入場」「(コンピューターの)設営」「(問題の)解答」「退場」の4ステップを踏みます.(「設営」とはコンピュータを設置したりするための時間です.) そのため,問題の解答の前にプログラムを起動することが出来ます.ここで,メモリの確保と問題の入力を分ける構成にしておけば,最大で30MBのメモリを確保するための時間を「問題の解答」の時間の外に出すことが出来て,その分の時間を処理側に回すことが出来ます.「newするな」で書いたもう1つのメリットが,これです.プログラムの起動時に,最初に配列の領域確保するような仕掛けにしておくと,このようなメモリ確保時間の短縮がすんなりできます.これは高速化とは少し違いますが,このようなプログラムのライフサイクルにまで注目すると,高精度化や,高速化の糸口になることがあります.
要所要所で必要になるかもしれないスキル
プログラムを高速化する話
http://www.slideshare.net/KMC_JP/ss-45855264
京大マイコンクラブの高速化の話.かなり濃い・・・けど使い道が結構難しい.実際にどれくらいの人に役に立つのか分からないが,一部ではかなり効果を発揮する技法.
プログラムを高速化する話
http://www.cc.u-tokyo.ac.jp/support/kosyu/X01/shiryou-1.pdf
東大の講義資料です.スパコンを扱う人だったりすると,キャッシュのアクセスやメモリのアクセス順序の最適化までしないと速度が出なかったりします.ここまでやれると本当にすごいのですが,実際のところ最適化してしまうと本当に読めなくなりますし,保守性が落ちすぎて仕様変更に耐えられなくなるので,普通の人にはお勧めしないです.
物理でマシンを触らないと,もう無意味なんじゃないかな?と思ってます.そのため,仮想化やコンテナが流行ってる昨今では,そこまでやっても効果があるのかな?というのは疑問です.検証したことないのですが,ちょっとそういうデータがあるなら見てみたいです.
まとめ
今まで使ってきた高速化技術を備忘録的に書いておきました.今となっては,「あーそういうことやってた時期もあったなー」とか,思い出しながら書いてます.書いてみると意外に量がありますね.何か,間違い等あったらコメントでご指摘お願いします.