元は scikit-learnで線形モデルとカーネルモデルの回帰分析をやってみた - イラストで学ぶ機会学習に書いていましたが、ややこしいので別記事にしました。
データセットはsklearn.datasets.load_diabetes を使います。
糖尿病患者442名のデータが入っており、基礎項目(age, sex, body mass index, average blood pressure)と6つの血液検査項目を入力とし、1年後の進行状況を予測ターゲットにします。
データを見る
まずやるべきはデータの性質を調べることです。
import pandas as pd
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
diabetes = datasets.load_diabetes()
train_data = diabetes.data[:-20]
test_data = diabetes.data[-20:]
train_target = diabetes.target[:-20]
test_target = diabetes.target[-20:]
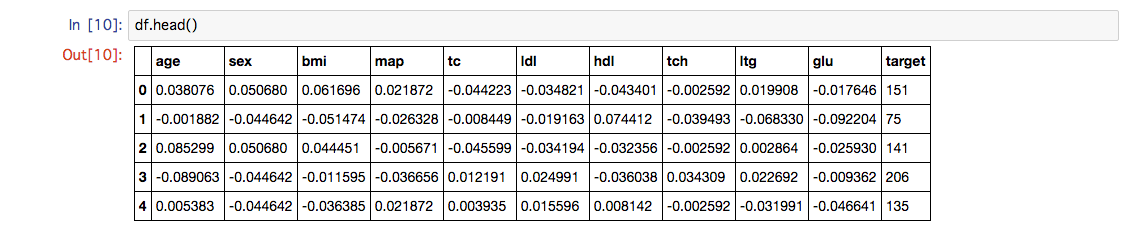
df = pd.DataFrame(diabetes.data, columns=("age", "sex", "bmi", "map", "tc", "ldl", "hdl", "tch", "ltg", "glu"))
df['target'] = diabetes.target
入力データは正規化されていることがわかります。
seabornでいくつかのデータをプロットしてみます。
import seaborn as sns
sns.jointplot(x="age", y="target", data=df)
sns.jointplot(x="sex", y="target", data=df)
sns.jointplot(x="ltg", y="target", data=df)
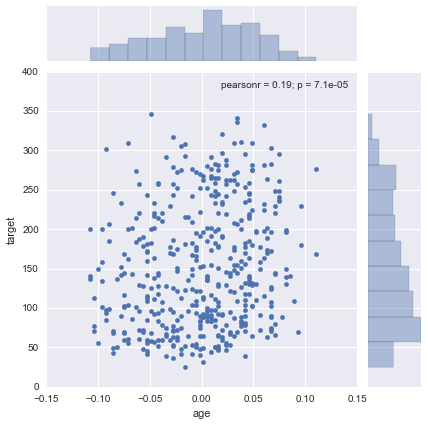
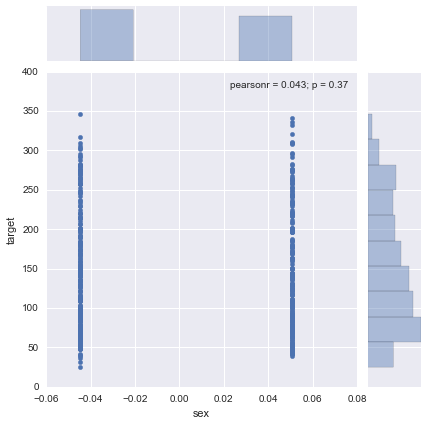
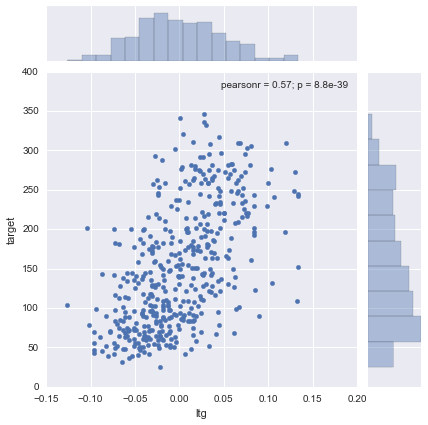
ltgにはある程度の相関が見られますが、ageやsexにはあまり相関が見えません。
線形モデルでの回帰
from sklearn import linear_model
from sklearn.kernel_ridge import KernelRidge
from sklearn.gaussian_process import GaussianProcess
regr = linear_model.LinearRegression()
regr.fit(train_data, train_target)
print(regr.score(test_data, test_target))
スコアは 0.58 でした。
カーネルモデルでの回帰
散布図を見ると、カーネルモデルではフィッティングしづらそうですが、一応やってみます。
k_ridge = KernelRidge(alpha=1.0, kernel='rbf')
k_ridge.fit(train_data, train_target)
print(k_ridge.score(test_data, test_target))
スコアは 0.20 でした。