全体像
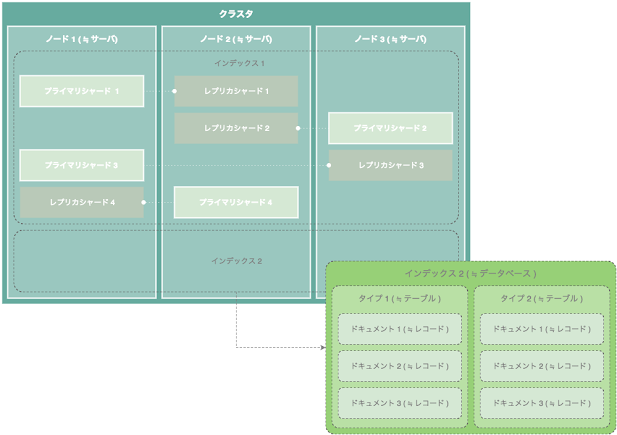
物理的なインデックス
Elasticsearch の物理的なインデックスは、クラスタ、 ノード、シャードの 3 つの要素から構成されている。
クラスタ ( ≒ ElasticSearch サーバー群 )
複数のノード ( ElasticSearch サーバー ) を一つの ElasticSearch として動作させることができます。クラスタ構成にすることで、大量のデータを複数のノードに分散して保持することが可能です。クラスタは同一のプロセス名 (デフォルトでは elasticsearch ) を指定することで構成できます。
ノード ( ≒ ElasticSearch サーバー )
Elasticsearch の 1 プロセス ( ≒ サーバー ) に相当します。基本的には 1 サーバーに、1 プロセス動作しますが、複数のノードを起動することも可能です。
シャード
各インデックスを分割したものです。シャードにはプライマリシャードとレプリカシャードが存在します。
プライマリシャード
インデックスの書き込みと参照処理で使用されます。プライマリシャードにデータを保存し、レプリカシャードにデータをコピーします。
レプリカシャード
プライマリシャードのコピーです。インデックスの参照処理で使用されます。プライマリシャードが消えてしまった場合は、該当の レプリカシャードが昇格されフェールオーバーに使用されます。
論理的なインデックス
Elasticsearch の論理的なインデックスは、インデックス、タイプ、ドキュメント の3つの要素から構成されています。
インデックス ( ≒ データベース )
RDB のデータベースに相当します。インデックスはドキュメントの集合です。Elasticsearch はインデックス単位でドキュメントを管理することができます。各インデックスを横断して検索することもでき、任意のインデックスのみ検索対象にすることもできます。
タイプ ( ≒ テーブル )
RDB のテーブルに相当します。インデックスに登録するドキュメントを分類するものです。各タイプを横断して検索することもでき、任意のタイプのみ検索対象にすることもできます。
ドキュメント ( ≒ レコード )
ドキュメントは、RDBMS の 1 レコードに相当します。ドキュメントは複数のフィールドから構成され、各ドキュメント異なった構造を持つことができます。