概要
前回 は Microsoftの Recommendations API の仕様や基本的な使い方を調べた。
今回はもうすこし詳しく、各種ビルドタイプの使い方や、評価値の意味を見てみる。
ビルドタイプ
Recommendationビルドタイプ
- User-to-Item, Item-to-Item のレコメンデーションが可能なモデルをビルドする。
- アルゴリズムは Matrix Factorization1
- (商品xユーザ)の表から行列分解によって商品ごとの特徴,ユーザごとの特徴 をそれぞれ抽出し、未知の商品xユーザの組み合わせの相性を推定する。
- 行列分解によるアルゴリズムの特徴として、"Coldアイテム" (=追加されたばかりで誰も購入しておらず情報が無い商品) にも自然に対応できるという利点がある。
FBT (Frequently Bought Together) ビルドタイプ
- Item-to-Item のレコメンデーションが可能なモデルをビルドする。
- User-to-Item には対応しない。
- ある商品に対して「どの商品と同時に買われたか」を特徴とし、距離関数によって類似する商品を探す。
- 「同時に買われた」というデータを起点としているので、Coldアイテムには対応できない。(誰にも買われていない商品は推薦されない。)
RecommendationモデルとFBTモデルの違い
- Recommendationモデルがユーザと商品の関係を元に推薦を行うのに対して、FBTは商品同士の共起関係を元に推薦を行う。
- 同じ Item-to-Item でも性質が異なるので、何を推薦したいのかによって使い分ける。
- Recommendation の Item-to-Item: 「この商品を買った人はこんな商品も買っています」
- FBT の Item-to-Item: 「この商品とよく一緒に買われている商品」
Rankビルドタイプ
- 商品に付与した特徴量を、有効性で順位付けする。
- レコメンデーションを行うモデルを作るわけではない。
- このビルドの結果から有効な特徴量を特定して、それらの特徴量だけを使ってRecommendationモデルをビルドすることで性能向上を図る、といった使い方をする。
モデルの性能指標
モデルの評価について、Rcommendations APIでは2種類の指標を提供している。
これらはRecommendations UIの[OFFLINE METRICS]で見られるほか、もちろんAPIで取得することもできる。
Precision-at-K
- 推薦された商品を、スコア順に上位K件で切ったときの適合率(Precision)の平均を出力する。(K=1..5)
- 「適合率」は情報検索の分野で用いられる評価指標で、推薦された商品のうち有効であった(ユーザが実際に買った)商品の割合を表す。
- この値が高いほど、少ない推薦枠で有効な推薦をできる可能性があると考えられる。
- K=1からK=5まであるうちのどれを見ればよいかについては
- 推薦枠の大きさが分かっているなら、その大きさで見る (たとえば一度に推薦できるアイテム数が4個の場合は、K=4のPrecision)を見ればよい。
- 推薦枠の大きさが決まっていなかったり、とにかく見込みの高いのをなるべく上位にしてほしい場合は、K=1からK=5までの平均値を見ればよい。
Diversity
- モデルが推薦した商品が、どれだけ分散しているか(一部の商品に偏っていないか)を評価する。
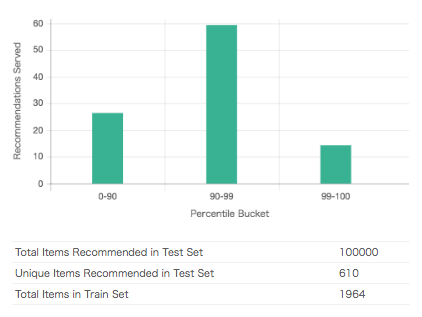
- すべての商品を人気順(売上数順?)に並べて、下位90%, 90〜99%, 99%以上 の3つのグループに分け、それぞれのグループごとに、推薦された回数の割合を求める。
- たとえば下の図では99-100の割合が15%程度であり、つまりすべての推薦枠の15%が、売り上げ上位1%の商品だけで占められていることになる。
- もしいずれかのグループの割合が100%とか0%に近い場合は、非常に偏った推薦をしていることになり、改善する必要があるかもしれない。
評価値を見る
Recommendationモデルにおいて最も重要なパラメータとして、モデルの次元数(Number of Model Dimension) と イテレーション数(Number of model Iterations) がある。
| 名前 | 説明 | 値(デフォルト値) |
|---|---|---|
| NumberOfModelIterations | モデルの構築を繰り返し実行する回数で、計算時間とモデルの精度に影響する。この数を大きくするとモデルの精度は向上するが、計算時間が増える。 | 10〜50の整数値 (40) |
| NumberOfModelDimensions | モデルがデータから発見しようとする特徴量の数に関係する。この数を増やすと、より粒度の細かい結果が得られるが、大きくしすぎるとモデルが商品間の相関関係を見つけにくくなる。 | 10〜40の整数値 (20) |
これらのパラメータが性能にどう影響するのか、評価値を使って見てみよう。
使う評価値は、Precision at KのK=1〜5における平均(いわゆるAverage Precision at 5)を使うことにする。
次元数は10〜40、イテレーション数は10〜50の範囲で設定できるので、それぞれを10刻みで変化させた計20通りの組み合わせに対して、それぞれモデルをビルドして評価値を取得することにする。
これもRecommendations UIでポチポチやってもよいが、20通りもやるのは中々つらい作業なので、PythohでAPIを叩いてやってみた。
コードはこちら。
https://gist.github.com/kokumura/0ee89a3020135ddddb20107e42b41128
実行すると数時間かけてモデルのビルドと評価を実行し、metricsディレクトリの下に評価値の入ったJSONファイルを16個出力する。
このファイルをjqとかで適当に整形し、結果をExcelなどに貼り付けて適当にグラフを描いたものがこちら。
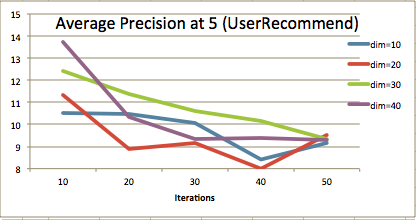
全体的に、イテレーション数の低い部分では評価値が高く、イテレーション数を増やすと評価値が低くなっている。
ドキュメントには「イテレーション数を増やすと精度(accuracy)が向上する」と書かれているが、精度とPrecisionは必ずしも連動しないということだろうか。
このケースでは、単純に評価値の大小だけで考えれば(40次元,イテレーション10回)が最適ということになるが、イテレーション数の少ない部分ではモデルが安定していないように見えるので、イテレーション30〜40くらいで挙動の安定している30次元のほうが良いかもしれない。
もちろん、システムに組み込んで運用する場合には、オフライン評価値だけでなくユーザの反応(クリック率など)を見て、実際の性能と評価値とが連動しているかどうかを確認することも重要である。
まとめ
- Azure の Recommendations API を使うと、APIを呼ぶだけでレコメンド機能を簡単に導入できることを確認した。
- モデルのタイプは2種類(Recommendations,FBT)あり、それぞれ特性が異なる
- Precision at K, Diversity の2つの指標を使ってモデルを評価できる。
-
"Matrix Factorizationとは" http://qiita.com/ysekky/items/c81ff24da0390a74fc6c ↩