最近Kaggleをやっていて
「100GB程度の巨大なCSVファイルに対してSQLで適当に集計(group by, join)をかける」
という処理が必要になった。
EMRとかBigQueryとか色々やりようはあると思うが、最近せっかくAzureと仲良くなりつつあるので、かねがねから気になっていた Azure Data Lake Analytics を使ってやってみることにした。
Azure Data Lake Analytics とは
- Hadoopベースのサービスで、様々なデータに対してU-SQLというSQLライクな文法によって記述されジョブを実行できる。
- データの入出力として、Azure Data Lake Store(中身はHDFS)だけでなく、Azure Blob Storage、SQL Server、その他HTTPで取得できるデータなどをシームレスに抽出・結合して利用できる。
- HDInsightとは異なってHadoopクラスタを意識する必要は無く、クエリの実行にかかった時間とジョブの実行数だけによって料金が発生する。
U-SQLは基本的にSQLに似た文法を持っているが、データの抽出・出力に関する文が存在する。
たとえば、"TSV形式の検索ログからRegion=en-gbの行だけ抽出してCSVで出力" をU-SQLで表現すると下記のようになる。
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int?,
Urls string,
ClickedUrls string
FROM "/Samples/Data/SearchLog.tsv"
USING Extractors.Tsv();
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
OUTPUT @rs1
TO "/output/SearchLog-transform-rowsets.csv"
USING Outputters.Csv();
やりたかったこと
- ローカルPCにある2つのCSVファイルを結合・集約して、ひとつのCSVファイルを出力する。
- 入力ファイルは、Kaggleの Outbrain Click Prediction のデータファイルのうち2種類で、それぞれ100GB, 300MB程度ある。
- 100GBのファイルをアップロードするのはつらいので、ファイルはなるべく圧縮されたままでやり取りしたい。
入力データ
入力データは、いずれもCSVファイルをzip圧縮した状態(.csv.zip)で提供されている。
| ファイル名 | サイズ | 主要なカラム | 内容 |
|---|---|---|---|
| page_views.csv | 約20億行、100GB | uuid, document_id | アクセスログに相当するデータで、uuid(ユーザID)とdocument_id(ページID)を紐付ける |
| documents_topics.csv | 300MB | document_id, topics_id | ページごとのトピック(内容)の関連性表すテーブル。ひとつのdocument_idに複数のtopics_idが紐付く。 |
uuid,document_id,timestamp,platform,geo_location,traffic_source
1fd5f051fba643,120,31905835,1,RS,2
8557aa9004be3b,120,32053104,1,VN>44,2
c351b277a358f0,120,54013023,1,KR>12,1
document_id,topic_id,confidence_level
1595802,140,0.0731131601068925
1595802,16,0.0594164867373976
1595802,143,0.0454207537554526
1595802,170,0.0388674285182961
出力(したい)データ
ユーザ(uuid)ごとに、アクセスしたことのあるページに関連するtopics_idをすべて列挙してカンマ区切りで結合した文字列がほしい。TSV形式で。
1fd5f051fba643 1,51,102
8557aa9004be3b 1,5,40,128
c351b277a358f0 3,70,68
Data Lake Analyticsにおけるファイル入出力について
Data Lake Analyticsでは、ファイルの入力と出力フォーマットは、それぞれU-SQLのEXRACT文、OUTPUT文の中で、Extractor,Outputterと呼ばれるクラスを指定することで指定できる。
デフォルトで利用可能な(ビルトインの)Extractor,OutputterはU-SQLのドキュメントに記載されており、下記の通り。
| 名称 | 説明 |
|---|---|
| CsvExtractor / CsvOutputter | CSVファイルの入出力 |
| TsvExtractor / TsvOutputter | TSVファイルの入出力 |
| TextExtractor / TextOutputter | Csv,Tsvを一般化したもので、パラメータで区切り文字を指定できる。 |
ドキュメントには書かれていないが、実はファイル名の末尾を".gz"などにすると圧縮ファイルとして扱ってくれるという機能がある。
ただし、下記の点に注意する必要があった。
- zipファイルの入力には対応していない
- 入力としてgzipファイルを利用する場合、1ファイルが4GB以下になるように分割しなければならない。
- 圧縮ファイルの出力ができない?
- Outputterは圧縮に対応していない?少なくともgzip,bzipを試してみたが無理だった。
- ヘッダ行を読み飛ばせない
- KaggleのCSVファイルは、1行目がヘッダ行(カラム名)になっているが、TextExtractorはヘッダ行のあるCSVを受け付けない。読み飛ばすオプションは無く、パースできないとジョブがエラーになる。
いちおう、C#を使ってカスタムExtractor/Outputterを実装することが可能なので、自分で実装すればいいという話だが、それだけのためにVisual Studioをインストールするのがダルかったので、今回はローカルPCで適当に前処理/後処理を挟むことで対応した。(この前処理/後処理をAzure Functionsでやることも考えたが、時間の都合で諦めた。)
実際の手順
データファイルの前処理(変換)とアップロード
前処理として、次の処理をする。
- 1行目(ヘッダ行)を削除
- zipを展開してgzipで圧縮
- サイズが4GB以上になるpage_viewsについては、出力ファイルを1億行ごとに分割(1ファイル約1.5GBになる)
ローカルPC(Ubuntu)にて実行
unzip -p documents_topics.csv | sed 1d | gzip -c documents_topics.gz
unzip -p page_views.csv.zip | sed 1d | split -l 100000000 --filter='gzip -c > $FILE.gz' page_views.parts.
こうやって作成した page_views.parts.*.gz, documents_topics.gz を、AzureポータルからBlobストレージにアップロードする。
H-SQLスクリプトを書く
ポイントとしては
- BLOB Storageに置いたファイルは、
wasb://から始まるURLで参照できる。 - EXTRACT FROMに続くファイル名はカンマ区切りで複数指定できる
- 出力時のOutputterに
quoting: falseを指定しないと、すべての項目が"でクオートされたファイルが出力される。 - 集約関数
ARRAY_AGGで、該当のtopic_idをカンマ区切り文字列に変換 (MySQLでいうGROUP_CONCATに相当)
@page_views =
EXTRACT
uuid string,
document_id int,
timestamp int,
platform int,
geo_location string,
traffic_source int
FROM
@"wasb://testdata@myblobstore/page_views.parts.aa.gz",
@"wasb://testdata@myblobstore/page_views.parts.ab.gz",
@"wasb://testdata@myblobstore/page_views.parts.ac.gz",
@"wasb://testdata@myblobstore/page_views.parts.ad.gz",
@"wasb://testdata@myblobstore/page_views.parts.ae.gz",
@"wasb://testdata@myblobstore/page_views.parts.af.gz",
@"wasb://testdata@myblobstore/page_views.parts.ag.gz",
@"wasb://testdata@myblobstore/page_views.parts.ah.gz",
@"wasb://testdata@myblobstore/page_views.parts.ai.gz",
@"wasb://testdata@myblobstore/page_views.parts.aj.gz",
@"wasb://testdata@myblobstore/page_views.parts.ak.gz",
@"wasb://testdata@myblobstore/page_views.parts.al.gz",
@"wasb://testdata@myblobstore/page_views.parts.am.gz",
@"wasb://testdata@myblobstore/page_views.parts.an.gz",
@"wasb://testdata@myblobstore/page_views.parts.ao.gz",
@"wasb://testdata@myblobstore/page_views.parts.ap.gz",
@"wasb://testdata@myblobstore/page_views.parts.aq.gz",
@"wasb://testdata@myblobstore/page_views.parts.ar.gz",
@"wasb://testdata@myblobstore/page_views.parts.as.gz",
@"wasb://testdata@myblobstore/page_views.parts.at.gz",
@"wasb://testdata@myblobstore/page_views.parts.au.gz"
USING Extractors.Csv();
@docs_topics =
EXTRACT
document_id int,
topics_id int,
confidence_level float
FROM @"wasb://testdata@myblobstore/documents_topics.csv.gz"
USING Extractors.Csv();
@user_topics =
SELECT
uuid,
string.Join(",", ARRAY_AGG(DISTINCT topics_id)) AS topics_ids
FROM
@page_views AS pv
JOIN @docs_topics AS dt ON pv.document_id == dt.document_id
GROUP BY uuid
;
OUTPUT @user_topics
TO @"wasb://testdata@myblobstore/user_topics.tsv"
USING Outputters.Tsv(quoting:false);
ジョブとして実行する
Data Lake Analyticsの画面から"新しいジョブ"を選択し、U-SQLを入力する。
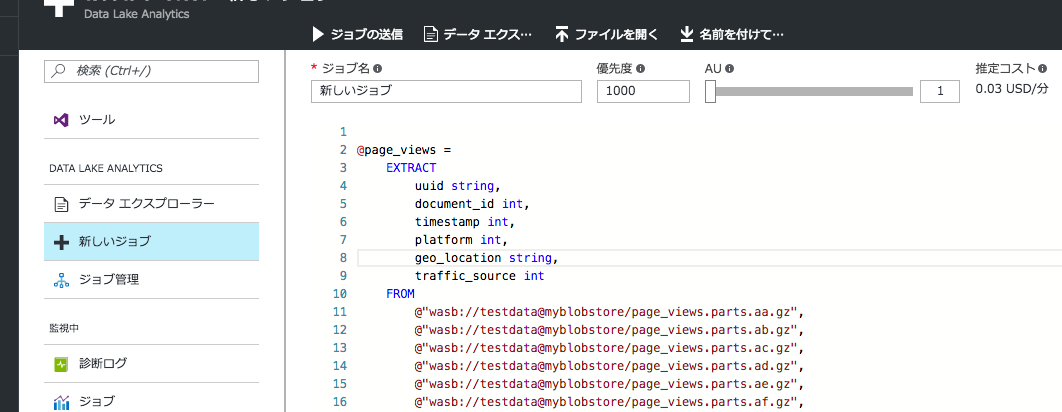
- 優先度 ... 複数ジョブを投げた場合の実行順に影響する? デフォルト値1000のまま
- AU ... 最大並列数。これを増やすと時間あたりの課金額が増えるが、並列実行可能な場合は全体の実行時間が減る。よく分からない場合は1にすべき。
"ジョブの送信"を押せば、ジョブの実行が即座に始まる。
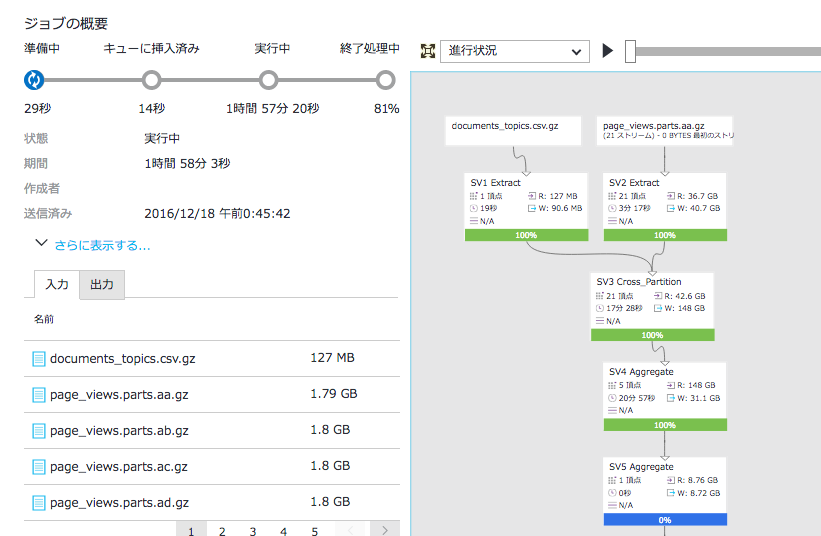
結果の取得
ジョブの実行が完了したら、出力された"user_topics.tsv"をダウンロードする。
結果として、今回の実行はAU=1で13時間ほどかかった。
時間による課金額は、AU数1 × 102円 x 13 = 1326円 くらいとなる。(この他に、ジョブ完了1回につき2.6円がかかる。)
AU数について
AU(分析単位)による課金額の増加について、少し分かりにくかったので書いておく。
ジョブ送信時には、AUは「同時に実行可能な計算プロセスの最大数」と記載されているので、
「実際に使ったCPU時間x単位時間あたりの課金額」
が課金されるような誤解をするかもしれないが、実際には
「実際に使ったCPU時間にかかわらず、設定したAUx全体の処理にかかった実時間」
が課金される。
したがって、たとえばほとんど並列実行できないような処理をAU=10などで投げると、処理時間は変わらずAUだけが増えるので、AU=1で設定した場合に比べて単純に10倍のコストがかかることになり、とても無駄である。
実際に使ったCPU時間分だけ請求されると勘違いして無闇にAU数を増やすととんでもない金額を請求される可能性があるので、注意が必要。
(時間が予測できない場合は、AU=1から始めて1ずつ増やしていくなどしたほうがよさそう。)
感想
Azure Data Lake Analyticsを使って、CSVファイルの結合・変換などをU-SQLで記述して実行できることを確認した。
今回はBLOBストレージを使ったが、データの規模が大きい場合は Data Lake Store(HDFS) を使えば入出力を並列化でき、オーバーヘッドが小さくなるのだと思う。
ファイルの入出力フォーマットに若干制約が多いし、単純な処理だけをするには料金が高めなので、ただサクっとファイルtoファイルの変換処理をしたいだけの用途にはあまり向いていなさそう。
U-SQLによる記述はわかりやすくてよい。