★IDの指定の仕方に関して更新が入っています。最新の記事はこちら★
AWS LambdaでDynamoDBから取得した値に任意の集計をかける(グルーピング処理追加)
前回書いた記事「AWS LambdaでDynamoDBから取得した値の最新レコードを取得する」を、以下の集計にも対応させてみました。
- 最新値 (latest)
- 最大値 (max)
- 最小値 (min)
- 平均値 (avg)
- 合計値 (sum)
- 件数 (count)
前提&仕様
以下を前提&仕様として作成しました。
- DynamoDBのハッシュキーにID(文字列)、レンジキーに時刻(文字列)を指定しているものとする。
- データは時系列に格納されているものとする。
- 指定したカラムの集計を取るようにする。
- 集計の時間を指定できるようにする。
- 集計の種類は指定可能とする。
- ID、集計期間、集計対象のカラム、集計の種類はそれぞれJSONのインプットで指定可能とする。
結果
こちらに登録してあります。
サンプルデータ
以下のデータをDynamoDBに入れました。これについて色々と操作をしようと思います。
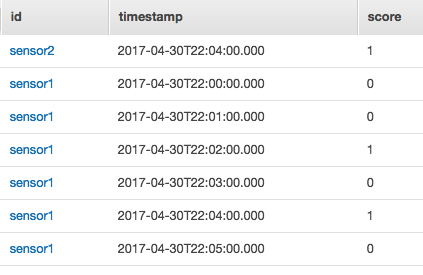
使い方
インプットデータの準備
以下のインプットデータが必要になります。
| カラム名 | 内容 |
|---|---|
| label_id | DynamoDBで指定しているハッシュキー名 |
| label_range | DynamoDBで指定しているレンジキー名 |
| id | 集計したいIDの値 |
| aggregator | 集計種別。種別は最初に書いた6種類に対応 |
| time_from | 集計対象期間(開始) |
| time_to | 集計対象期間(終了) |
| params | [個別]集計時必要になるパラメータ |
インプットデータの準備(個別部)
上述の「params」に該当する部分は以下の様なパラメータの準備が必要になります。
| 集計種別 | 必要な値 |
|---|---|
| 最新値(latest) | range: レンジキー名(共通部で指定していますが、一応他に体裁を合わせました) |
| 最大値(max) | score: 集計対象のカラム名 |
| 最小値(min) | score: 集計対象のカラム名 |
| 平均値(avg) | score: 集計対象のカラム名 |
| 合計値(sum) | score: 集計対象のカラム名 |
| 件数(count) | score: 集計対象のカラム名 |
こんな感じで指定すれば実行可能になります。
とりあえず実行してみる
とりあえず動かしてみたい人は以下の様な感じで実行すれば結果が見れます。今回はSERVERLESS FRAMEWORK上で動かしています。
「sensor1」に対して指定した時間の中での:
最新値(latest)
$ sls invoke local -f run -d '{"label_id": "id", "label_range": "timestamp", "id": "sensor1", "aggregator": "latest", "time_from": "2017-04-30T22:00:00.000", "time_to": "2017-04-30T22:05:00.000", "params": {"range": "timestamp"}}'
"{\"timestamp\": \"2017-04-30T22:05:00.000\", \"score\": 0.0, \"id\": \"sensor1\"}"
最大値(max)
$ sls invoke local -f run -d '{"label_id": "id", "label_range": "timestamp", "id": "sensor1", "aggregator": "max", "time_from": "2017-04-30T22:00:00.000", "time_to": "2017-04-30T22:05:00.000", "params": {"score": "score"}}'
"{\"timestamp\": \"2017-04-30T22:04:00.000\", \"score\": 1.0, \"id\": \"sensor1\"}"
(同じ値がヒットした場合は新しい方のデータを取得する様にしています。)
最小値(min)
$ sls invoke local -f run -d '{"label_id": "id", "label_range": "timestamp", "id": "sensor1", "aggregator": "min", "time_from": "2017-04-30T22:00:00.000", "time_to": "2017-04-30T22:05:00.000", "params": {"score": "score"}}'
"{\"timestamp\": \"2017-04-30T22:05:00.000\", \"score\": 0.0, \"id\": \"sensor1\"}"
平均値(avg)
$ sls invoke local -f run -d '{"label_id": "id", "label_range": "timestamp", "id": "sensor1", "aggregator": "avg", "time_from": "2017-04-30T22:00:00.000", "time_to": "2017-04-30T22:05:00.000", "params": {"score": "score"}}'
"0.3333333333333333"
合計値(sum)
$ sls invoke local -f run -d '{"label_id": "id", "label_range": "timestamp", "id": "sensor1", "aggregator": "sum", "time_from": "2017-04-30T22:00:00.000", "time_to": "2017-04-30T22:05:00.000", "params": {"score": "score"}}'
"2.0"
件数(count)
$ sls invoke local -f run -d '{"label_id": "id", "label_range": "timestamp", "id": "sensor1", "aggregator": "count", "time_from": "2017-04-30T22:00:00.000", "time_to": "2017-04-30T22:05:00.000", "params": {"score": "score"}}'
"6"
仕組み
最新値
以前の記事と同様、指定したレンジキーの最大値を取るようにしただけです。
max(data, key=(lambda x:x[params['range']]))
最大値 / 最小値
max関数とmin関数が使えるようにこんな実装にしています。
max_aggregator.py
max(data, key=(lambda x:x[params['score']]))
min_aggregator.py
min(data, key=lambda x: x[params['score']])
平均値
後述の合計値と件数を使っての計算になります。
sum(map(lambda x: x['score'], data)) / len(map(lambda x: x['score'], data))
合計値
sum関数使ってサクッと計算したかったのでこんな感じです。
sum(map(lambda x: x['score'], data))
件数
対象カラムの長さをとっただけです。
len(map(lambda x: x['score'], data))
AWS Lambdaでも動くのか?
現状のserverless.ymlには権限周りの設定が足りなかったようなのですが、とりあえずデプロイ後に手動で権限を正しくセットしたらうまくいきました。
とりあえずデプロイは何も問題なく完了。
$ sls deploy
Serverless: Packaging service...
Serverless: Creating Stack...
Serverless: Checking Stack create progress...
.....
Serverless: Stack create finished...
Serverless: Uploading CloudFormation file to S3...
Serverless: Uploading artifacts...
Serverless: Uploading service .zip file to S3 (10.19 KB)...
Serverless: Updating Stack...
Serverless: Checking Stack update progress...
...............
Serverless: Stack update finished...
Service Information
service: lambda-dynamodb-aggregator
stage: dev
region: us-east-1
api keys:
None
endpoints:
None
functions:
run: lambda-dynamodb-aggregator-dev-run

動きはしました。(件数を取得しています)
