AWS re:Invent 2016のキーノートにてAmazon Athenaが公開されたので、使ってみました。
Amazon Athenaとは
公式ページに詳しく載っていますが、簡単に言うとS3を標準SQLでクエリ可能にしたサービスです。
早速使ってみる
AWSコンソールログイン後のサービス一覧にはまだ追加されていませんでしたが、公式ページから使ってみます。
検索する
サービスに入るとsampledbがすでにセットされているので、まずは検索をかけてみます。
ログイン後の画面は完全にSQL管理画面ですね。
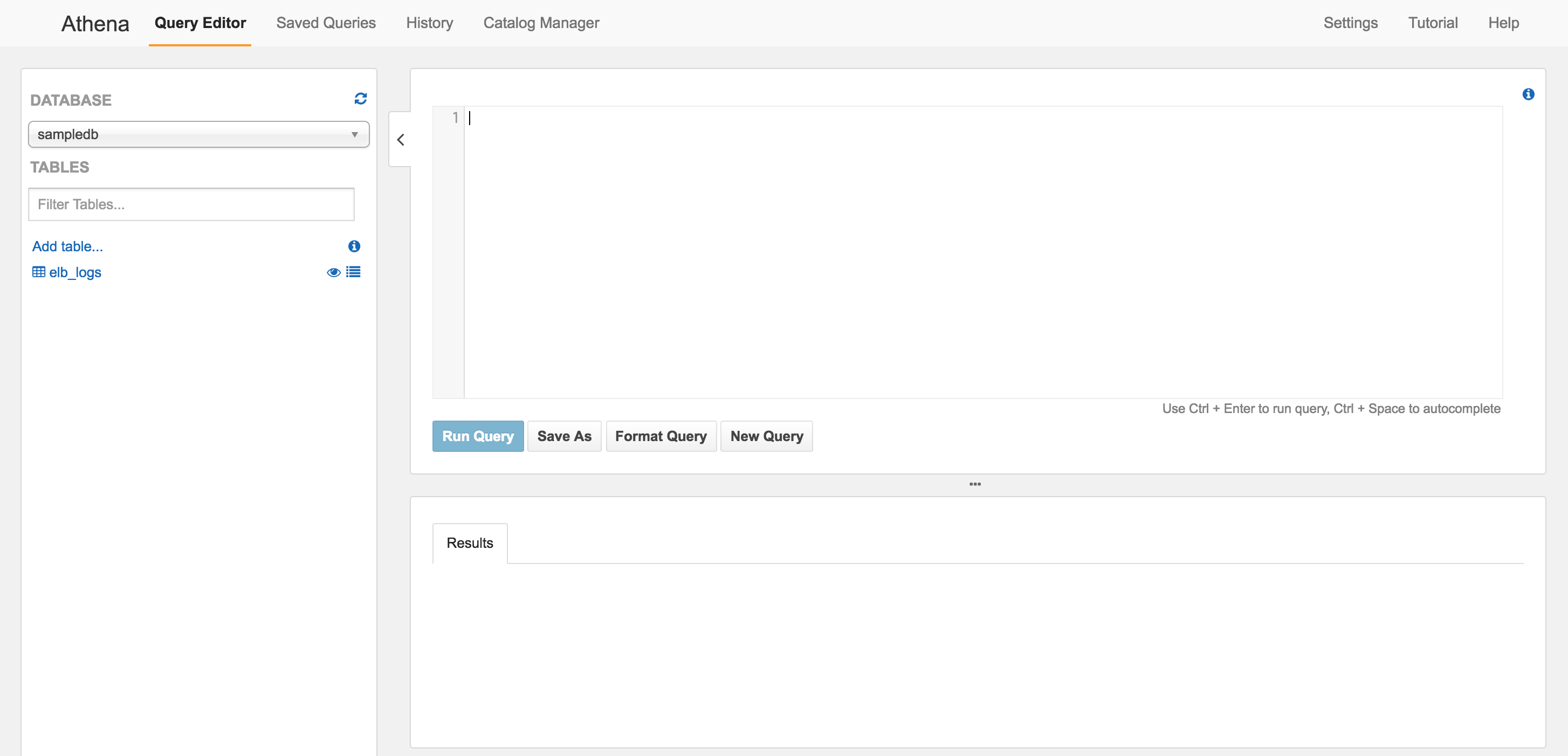
すでにsampledbの中にelb_logsというテーブルがあるので、検索をかけてみます。
select * from elb_logs;
すぐ結果が返ってきました。素敵。

ちなみにここまででS3にアクセスしてみたら、新しいバケットができていました。

ほかにもいくつか試してみます。全部で何件あるのか確認。
select count(*) from elb_logs;

backendprocessigntimeが0.2より大きいものを検索。
select * from elb_logs where backendprocessingtime > 0.2;

カウント数は165件でしたので、無事絞り込めているようです。ちなみにデフォルトの最初の表示件数は99件のようです。スクロールすればもちろん動的に更新されていきますが。
テーブルを作成してみる
せっかくなので新しくテーブルを作成したいと思います。適当なcsvファイルが必要なようなので、以下のようなデータをS3に登録しておきます。
id, name, age, position
1, Yamada, 22, Member
2, Taro, 30, Project Leader
3, Sato, 27, Sub Leader
4, Ichiro, 46, Manager
DB、テーブルの作成
最初にデータベース名とテーブル名、S3のパスを書きます。説明が書いてあるのでS3のパスもどのようにかけばいいのか明確で使いやすいです。ちなみにすでにあるデータベースを使うこともできますし、新しい名前を書けば勝手に新しいデータベースを作成してくれます、これも素敵。
(DDLを見てみると「CREATE EXTERNAL TABLE IF NOT EXIST」となっていたので、仮にテーブルの重複作成をしようとしても防いでくれるようです。どういう動作をするのかまでは知りません。)

形式の選択
S3に保存してあるデータの形式を選択します。今回はCSVを選択します。

カラムの設定
それぞれのカラムの設定をします。ここでstringやintといったデータの型を選べるんですね。

パーティションの設定
Athenaではパーティションという仮想カラムを設けることで、特定のカラム同士をグルーピングできるらしいです。詳しいことはこれから調べようと思います。

テーブルの作成
ここまでくればテーブルが作成されます。

作成したテーブルで検索してみる
一応きちんと検索できるのか、いくつかクエリを試してみます。
select * from sample_table;

・・・やってみてわかることってありますよね。csvファイルにヘッダいらないのか。そういえば途中でヘッダ用意してたな。。。まぁとはいえ、無事検索はできました。(ちなみに型に合わないデータは表示されないんですね。idとagegはint型で定義していたので、検索結果が空になったようです)
所感
使ってみた感じとしては、かなり可能性を感じさせる使いやすさとレスポンスでした。これは期待ですよ!
他にもクエリの保存とか履歴とか色々と機能がありそうなので、またいじってみたいと思います。
おまけ
もしテーブル作成時にこんな画面になったら、テーブル名とか疑ってみてください。うっかりテーブル名に「-」(ハイフン)を入れて作ろうとしてしまい、入力時には特にバリデーションで弾かれなかったので気づきませんでした。

あとはいくつかリンク切れのページがあったりもしましたが、すぐに対応されるかと思います。
何はともあれ今後に期待です。