Sklearnでのデータ前処理① 欠損値の処理
データの前処理とは
実際の業務などで使うデータで完璧に整備されているものはとても少なく、空欄があったり(欠損値)、異常値があったりと分析をする際に障害となってしまうものが含まれているのがほとんどです。よって、データ分析をする上でデータの前処理はとても大切な役割を果たします。むしろ、前処理がないと機械学習モデルに当てはめることができないのでなにも始まりません。また、この前処理のできの良し悪しによって、結果も違ってくるという意味でも重要な要素と言えます。
こちらがpreprocessingのライブラリがリストにされてる公式ドキュメントです。
Preprocessingの種類
- Data cleaning
- Data integration
- Data transformation
- Data reduction
今回やるのは、このData cleaningの部分です。Data cleaningでは、欠損値を埋めたり、外れ値を認識し除外したりします。
Imputerでのpreprocessing
Preprocessing においてのImputerは欠損値を mean(平均), median(中央値), mode(最頻値)のどれかに置き換えることができます。
ちなみに、データ内にNULL値があるかどうかを特定するのは下記のコードでできます。
#データの中に欠損値があるかどうかを見ます axisが0なのは列を検索するからです。
dataset.isnull().any(axis=0)
>>>
Name False
Age True
Job True
#これはAgeとJobに欠損値が含まれていることを示します
そして、欠損値がそれぞれの値にどれくらい含まれているのかを探すコードは下記になります。もし、欠損値があまりにも多かったらその列を考慮しないでデータを使ったほうが良いのかもしれませんし、もし逆に欠損値が少ないものであれば、なんらかの値で埋めるという選択肢も取れます。
dataset.isnull().sum()
>>>
Name 0
Age 76
Job 2
この場合、Nameは何も問題ありませんが、Age, Jobには欠損値があり、なんらかの値でその欠損値を埋める必要があります。
Finally! Imputerで欠損値を埋めていきます。
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0, verbose=0, copy=True)
imp.fit(df[df.columns["Embarked"]])
df["Embarked"]=imp.transform(df[df.columns["Embarked"]]).ravel()
#使い方はこんな感じで、変数に代入して、それをfitさせ、実際データをTransformさせるみたいな感じです。
下記がImputerの中身の詳細です。
missing_values
これで欠損値であるものを指定します。 defaultは'NaN'です。strategy
ここで、mean, median, mode のどれかを指定します。axis
行か列かの指定です。verbose
理論値。copy
コピーするか、元のデータ自体に変更を加えるかの指定です。
こちらが公式ドキュメントです。
ちなみに文字列のImputer は複雑だったので、 .fillna()で欠損値を埋めてみました。
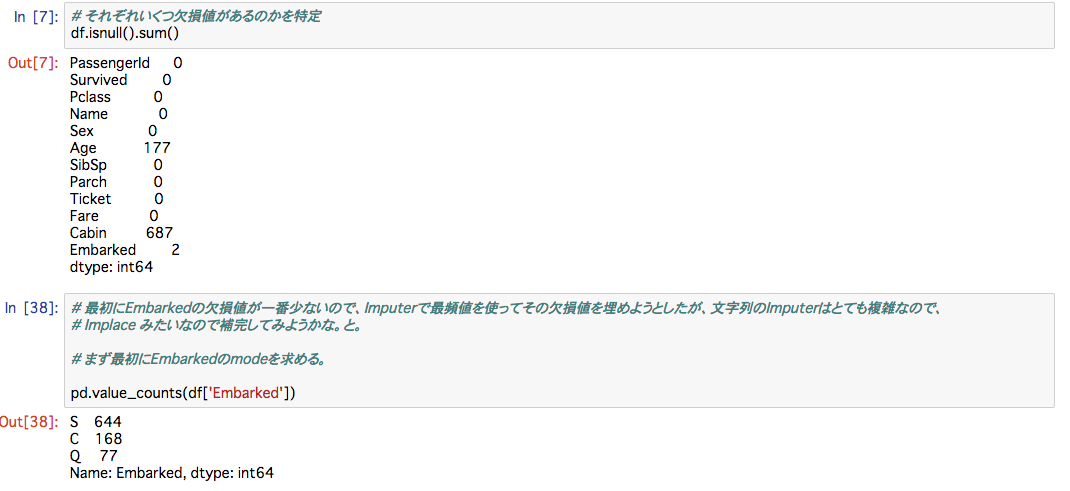
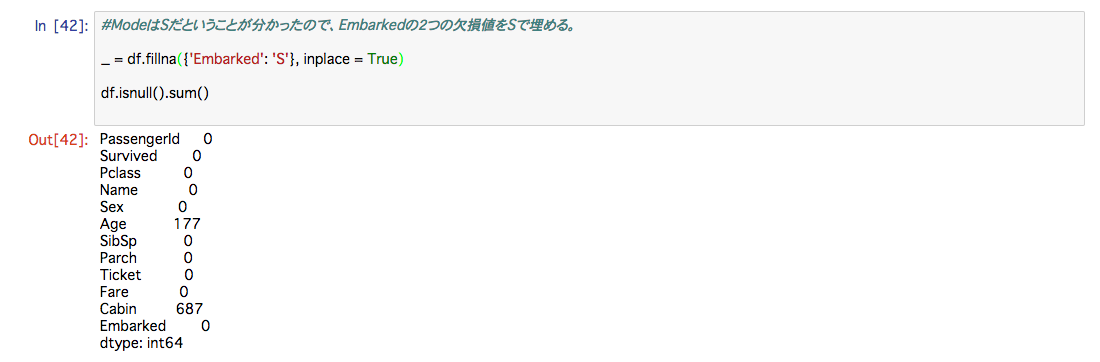
fillna()はdictionaryを入れることで、列ごとに、その代替値を指定することもできます。上記では、Embarkedという列のnanをSで埋めています。埋める値が少ない時、かつ埋める値が同じ時はこれでも対応できそうです。
.dropna()での行ごと、または、列ごと消去
例えばある行の90%が欠損値であれば、分析の際に考慮せず、行ごと消去してしまったほうが良い場合もあります。そんな時に使えるのが列ごと、行ごと消去できる pandasライブラリの一つである、'.dropna() 'です。default code はこんな感じです。
dataframe_name.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
.dropna()の中身はこんな感じです。
axis
行を消去するのか、列を消去するのかを決めます。 行の場合は、0か'index'で、列の場合は、1か'columns'で指定します。その他にも、tuplesやlistsも可能のようです。how
一つでもNaNが含まれていたら消去の場合は'any'で、全てがNaNの場合は消去と指定したい場合は'all'と書きます。thresh
これは、数字を指定し、ちゃんと使える値がat least(最低)この数あります。そしてその数に満たない行は消去します、という意味が含まれています。subset
subsetは列を指定して、その列にNaNがある行自体を消去します。例えば、列Aと指定し、行6にNaNがあった場合、行6自体を消去します。axisを変えることで、行でNaNを検索し、NaNがある列を消すことも可能です。inplace
これをTrueにすると、修正したコピーを作るのではなく、元のデータセット自体に変更を加えます。
こちら公式ドキュメントです。