アダブースト (AdaBoost) のまとめ
What is アダブースト (AdaBoost) ?
アダブーストは、ランダムよりも少し精度がいいような弱い識別機を組みわせて、強い識別機を作成しようとする機械学習モデルです。
作り方の流れは、
まず、弱い識別機の適用させ、誤分類してしまったものの重みを増やす。
そして、次にその重みがついたものを優先的にみて、分類する。ということを繰り返します。
下記の図を参考にするとわかりやすいです。Youtube のリンクも貼っておいたので、詳しく知りたい方は見てみてください、
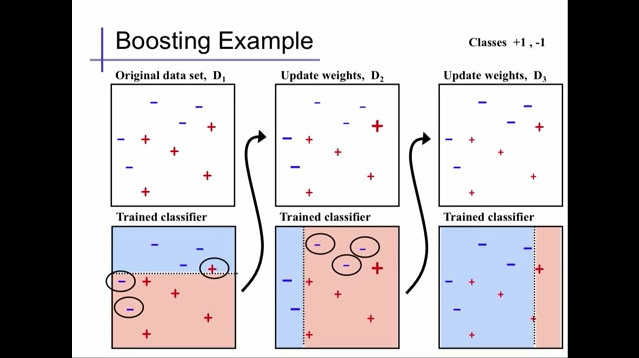
Extracted from Alexander Ihler's youtube video
上記の図では、最初にD1で弱い識別機を使って、分類し、D2で誤分類した '+'1個と'-'2個の重みを増やしています。次にその誤分類された3つを優先的に考えて、また分類しています。ここで、重みを増やすのと同時に、正確に分類された他のものの重みは減っています。さらに、D3では、D2で誤分類された'-'3個の重みを増やすと同時に他のものの、重みは減っています。ちなみに、AdaBoost の default code では、この弱い識別機での分類は、DecisionTree (決定木)が使われています。
その繰り返し行った分類の重みを元に、強い識別機というものを作ります。
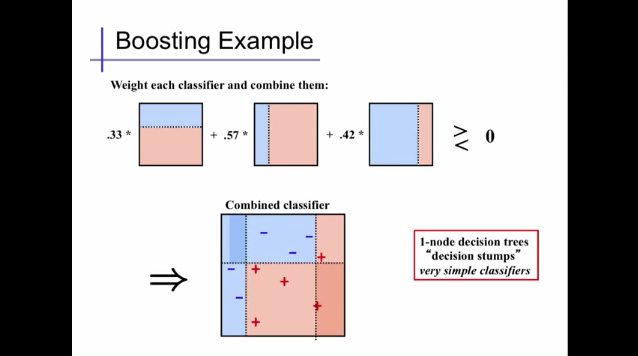
Extracted from Alexander Ihler's youtube video
default のコード
from sklearn.ensemble import AdaBoostClassifier
AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
アダブースト (AdaBoost) 内の Parameter の説明
- base_estimator
弱い識別機として使われる機械学習モデルのこと。default は、DecisionTreeClassifier (決定木)が使われているが、指定することで他の機械学習モデルを適応することもできる。
- n_estimators
弱い識別機を使った分類を何回繰り返すかの指定。しかし、その前に強い識別機が100%の精度になったら、そこで終了。
アダブースト (AdaBoost) の 良い点悪い点。
- 良い点
弱い識別機を幾つか組み合わせるので、正確に分類されやすい。
- 悪い点
K nearest neighbors と同じで、ノイズ(違うラベルが同じ場所に混在する)や、Outliers (異常値)にも、弱い。過学習になりやすい。
まとめ
以上が現在筆者のわかる範囲での アダブースト (AdaBoost) の概要です。
日々更新していきますので、追加すべきところ、直すべきところありましたら、コメントいただけると幸いです。