いきなりですが、次のコードの良くないところはどこでしょう?
interface Foo {
Comparator<Integer> getComparator();
}
なお Comparator は java.util パッケージに含まれるインタフェースで次のように宣言されています。
interface Comparator<T> {
int compare(T o1, T o2);
}
答え
Foo をより良く書きなおすと次のようになります。
interface Foo {
Comparator<? super Integer> getComparator();
}
? super や ? extends (下限または上限つきワイルドカード)は Java でジェネリクスを使う上で特に難しい部分です。比較的新しい言語( C# 、 Scala 、 Ceylon など)では同じ目的のためによりシンプルでわかりやすいアプローチがとられています。
Java が採用した方法は Use-site variance annotation と呼ばれ、 C# などが採用した方法は Declaration-site variance annotation と呼ばれます。本投稿では Declaration-site variance annotation の考え方をベースに Java でどのように ? extends や ? super を使えば良いか について書きます。
これは必ずしも Java で一般的な方法ではありません。 Java の ? super や ? extends の使い方については PECS が有名ですが、一部それと異なる結果になります。 PECS との違いも最後に述べます。
想定読者
前提知識
- Java のコードが読める
- 継承とポリモーフィズムについて理解している
- ジェネリクスの基本について理解している(
List<String>が意味することはわかる)
読むといいと思う人
-
? superや? extendsって何?という人 -
? superや? extendsをなんとなく使ったことはあるけどよくわかっていない人 - 基本的な使い方はわかっているけど、ジェネリック型が入れ子になるなど複雑なケースでよくわからない人
- Java しか知らず、他の言語での考え方について学びたい人
- Variance(変性) って何?という人
- Variance について聞いたことはあるけどよくわかっていない人
- PECS って何?という人(比較するために PECS についても簡単に説明しています)
本投稿での表記について
コードのタイトル部
本投稿では Declaration-site variance annotation と Use-site variance annotation の両方を扱うため、文中のコードがどちらを意図しているかわかりやすいように、タイトル部に Declaration-site または Use-site と表記しています。
// Declaration-site variance annotation のコード
// Use-site variance annotation のコード
何の表記もない場合は両者に共通のコードです。
Declaration-site variance annotation のコードは Java プログラマが理解しやすいように Java 風に書いていますが、 Java ではコンパイルできません。
Annotation
本投稿で Annotation と言った場合には、 Declaration-site variance annotation で使われる in と out 、 Use-site variance annotation で使われる ? super と ? extends などのことを指します。Javaのアノテーション( @Override など)のことではないので注意して下さい。 Java のアノテーションについてはカタカナで「アノテーション」と書きます。
※(補足)
本文中に次のような形で補足を挿入しています。
※ これは補足の例です。
特に、厳密な説明をすることで話がわかりづらくなる箇所についてあえてやや不正確な説明をした上で、補足でより正確な説明をしている箇所があります。
Hello, Variance!!
まずは Variance(変性) の例について見てみましょう。
Animal クラスを継承した Cat クラスがあるとします。そこで、次のようなコードを考えてみます。
List<Cat> cats = new ArrayList<>();
List<Animal> animals = cats; // List<Cat>をList<Animal>に代入
animals.forEach(System.out::println); // animalsの要素を表示( Java 8 の構文を使用)
一見、 Cat は Animal の派生型なので List<Cat> を List<Animal> に代入しても問題ないように思えます。しかし、このコードはコンパイルエラーになります。
いったい何が問題なのでしょう?次のコードを見ればその理由が分かります。
List<Cat> cats = new ArrayList<>();
List<Animal> animals = cats;
animals.add(new Animal()); // 実体はList<Cat>なのにAnimalを追加!?
上記コードのように、もし cats が animals に代入できるなら List<Cat> に Animal を追加するコードが書けることになり、コンパイル時の型チェックをすり抜けて実行時エラーになってしまいます。
とは言え、 List に変更を加えなければ問題ないのに、 List<Cat> と List<Animal> に一切互換性がないも不便です。次のように書けば cats を animals に代入できます。
List<Cat> cats = new ArrayList<>();
List<? extends Animal> animals = cats;
animals.forEach(System.out::println);
Java では ? extends をつけることによって Variance を変更することができ、型パラメータの異なる List に互換性を持たせることができます。
次に Variance について詳しく説明します。
継承とVariance
ジェネリクスと Variance について考える準備として、まずは継承と Variance について説明します。
メソッドの戻り値
次のようなクラス A があるとします。
class A {
Animal makeAnimal() { ... }
}
A を継承して makeAnimal メソッドをオーバーライドします。このとき、 makeAnimal の戻り値の型を Animal よりも狭い(より特化した) Cat に変更することができます。
class B extends A {
@Override
Cat makeAnimal() { ... }
}
これが許されるのは Animal 型の変数に Cat を代入できるのと同じ理由によります( Cat は Animal を継承しているので Animal として振る舞える、 is-a 関係 、 Cat is an Animal )。
Animal と Cat 、 A と B の間にはそれぞれ継承による派生関係が成り立ちます。派生型と基本型の関係を 派生型 < 基本型 のように書くと、次のように書けます。
-
Cat<Animal -
B<A
メソッドの戻り値の型( Cat と Animal )とその持ち主の型( B と A )について、派生の方向が一致(両方とも < )しています。このような状態を Covariant(共変) と呼びます。
上記のように、 継承におけるメソッドの戻り値の型については Covariant になります。
メソッドの引数
次はメソッドの引数について考えてみます。
class C {
void useAnimal(Animal animal) { ... }
}
C を継承して useAnimal メソッドをオーバーライドします。同じように引数の型を狭めて Cat にするとどうなるでしょうか。
class D extends C {
@Override
void useAnimal(Cat cat) { ... }
}
これはコンパイルエラーになります。 D は C を継承しており C として振る舞う必要があります。そのためには、 useAnimal が引数として Animal を受け取れなければなりません。しかし、 D の useAnimal は Animal よりも狭い Cat しか受け取れません。よって、 D は C として振る舞うことができず、 is-a 関係 を満たすことができないのでエラーとなります。
逆に、引数の型を広めるとどうなるでしょうか。
class C {
void useCat(Cat cat) { ... }
}
class D extends C {
@Override
void useCat(Animal animal) { ... }
}
D の useCat はより C の useCat よりも広い型( Animal )に対応しています。これなら、 D が C として振る舞うことができそうです。
Animal と Cat 、 C と D の関係を不等号で表すと次のようになります。
-
Cat<Animal -
C>D
引数の時とは異なり、不等号の向きが逆転( < と > )しました。このような状態を Contravariant(反変) と呼びます。
一般的に、 継承におけるメソッドの引数については Contravariant となります。
実際には Java の型システムでは、オーバーライドするときにメソッド引数の型を変えることはできません(上記の useCat のコードはエラーになります)。不等号(と等号)で表すと
-
Cat=Cat(ここの型を変えることができない) -
C>D
でなければなりません。そのような関係を Invariant(非変) と呼びます。一般的な型システムについて考えると継承時のメソッドの引数については Contravariant で安全なのですが、 Java の型システムでは Invariant となります。
※ Java の型システムではオーバーライドしてメソッドの引数の型を変えた場合は、オーバーライドではなくオーバーロードされた別のメソッドとして扱われます。そのため、 useCat のコードから @Override を取り除くとエラーでなくなります。引数の型を狭めた場合( useAnimal のコード)でも @Override をつけなければオーバーロードとなりエラーになりません。
Covariant か Contravariant か Invariant かという性質のことを Variance と呼びます。
ジェネリクスとVariance
派生型を作るのは継承だけではありません。ジェネリクスも派生型を作る場合があります。本題に戻ってジェネリクスと Variance について考えてみましょう。
メソッドの戻り値
最もシンプルな例として、 T 型のオブジェクトを返す(供給する)だけの型 Supplier (供給者)を考えます。
※ Supplier は Java 8 で頻出のインタフェースです。
interface Supplier<T> {
T get();
}
このとき、 Supplier<Cat> と Supplier<Animal> の関係について考えてみましょう。 Supplier<Cat> は Cat を供給します。供給された Cat は Animal として振る舞うことができるので、 Supplier<Cat> は Animal を供給しているとも考えられます。そのため、 Supplier<Cat> は Supplier<Animal> として振る舞うことができ、 Supplier<Cat> は Supplier<Animal> の派生型であると言うことができそうです。
この関係を < を使って書くと次のようになります。
-
Cat<Animal -
Supplier<Cat>< `Supplier`
不等号の向きがそろっているので、これは継承のときに見たのと同じ Covariant な関係です。
一般的に、 ジェネリックな型はメソッドの戻り値としてしか使われない型パラメータについて Covariant になります。
※ 実際には、上記のように宣言するだけでは Covariant として取り扱えません。後述の構文で明示的に Covariant であることを指定する必要があります。
メソッドの引数
同じく最もシンプルな例として、 T 型のオブジェクトを受け取る(消費する)だけの型 Consumer (消費者)を考えます。
※ Consumer も Java 8 で頻出のインタフェースです。
interface Consumer<T> {
void accept(T t);
}
このとき、 Consumer<Cat> と Consumer<Animal> について考えてみましょう。 Consumer<Cat> は Cat を受け取って消費します。 Consumer<Animal> はより広い型 Animal を受け取ることができます。 Consumer<Animal> は Consumer<Cat> として振る舞って Cat を受け取ることができるため、 Consumer<Animal> は Consumer<Cat> の派生型と考えることができそうです。
逆はダメです。 Consumer<Cat> が Consumer<Animal> として振る舞おうとしても、 Consumer<Cat> は Animal を受け取れません。
つまり、次のような関係になります。
-
Cat<Animal -
Consumer<Cat>>Consumer<Animal>
不等号の向きが反転しているので、これは継承の時に見たのと同じ Contravariant な関係です。
一般的に、 ジェネリックな型はメソッドの引数としてしか使われない型パラメータについて Contravariant になります。
※ 実際には、上記のように宣言するだけでは Contravariant として取り扱えません。後述の構文で明示的に Contravariant であることを指定する必要があります。
Declaration-site variance annotation
Declaration-site variance annotation を採用した言語では、ジェネリクスの型パラメータの宣言(Declaration)に Annotation を付与して Variance を指定することができます。
ここでは C# や Ceylon にならって、 out を付けたら Covariant 、 in を付けたら Contravariant 、何も付与しなければ Invariant になるとします。 Covariant であるために out が付与された型は戻り値でしか使えません。同様に、 Contravariant であるために in が付与された型は引数でしか使えません。これに違反するとコンパイルエラーになります。
interface Supplier<out T> { // outが付与された型は戻り値にしか使えない
T get();
}
interface Consumer<in T> { // inが付与された型は引数にしか使えない
void accept(T t);
}
このとき、 Supplier は Covariant、 Consumer は Contravariant なので、次のような代入が可能になります。
Supplier<Cat> catSupplier = ...;
Supplier<Animal> animalAupplier = catSupplier; // Covariant なので Supplier<Cat> < Supplier<Animal>
Consumer<Animal> animalConsumer = ...;
Consumer<Cat> catConsumer = animalConsumer; // Contravariant なので Consumer<Animal> < Consumer<Cat>
また、複数の型パラメータを持つジェネリックな型では、片方について Covariant で、もう一方について Contravariant なケースも考えられます。
最もシンプルな例として、 T を受け取り R を返すだけの型 Function について考えます。 Function に in 、 out を付与すると次のようになります。
※ Function も Java 8 で頻出のインタフェースです。
interface Function<in T, out R> { // T は引数に、 R は戻り値にしか使えない
R apply(T t);
}
Function は T については Contravariant に、 R については Covariant になるので、次のような代入が可能です。
Function<Animal, Cat> animalToCat = ...;
Function<Cat, Animal> catToAnimal = animalToCat; // TについてはContravariant、RについてはCovariant
in, out と引数・戻り値の型のより正確な関係
これまでは意図的に簡略化して次のように説明してきました。
-
outで型パラメータを宣言 → メソッドの戻り値でのみ利用可 -
inで型パラメータを宣言 → メソッドの引数でのみ利用可
しかし、これは正確な説明ではありません。次の話に進む前に、型パラメータと引数・戻り値の型のより正確な関係について説明します。
例えば次のコードでは、一見 out を付与された T が引数で使われているようですが問題ありません。
interface Foo<out T> {
void foo(Consumer<T> consumer); // Tが引数で使われているように見えるが問題なし
}
Foo<Cat> と Foo<Animal> について考えてみましょう。 Consumer は前の例のように Consumer<in T> なので T について Contravariant です。そのため、次のような関係になります。
-
Cat<Animal -
Consumer<Cat>>Consumer<Animal>
Consumer<Cat> > Consumer<Animal> ということは、 Foo<Cat> の void foo(Consumer<Cat>) は Foo<Animal> の void foo(Consumer<Animal>) よりも広い型に対応できるので
-
Foo<Cat>< `Foo`
となります。 Foo<Cat> と Foo<Animal> 、 Cat と Animal で不等号と向きが同じであるため Foo は T について Covariant であることがわかります。よって、 Foo の T は out に違反していないわけです。
このように、 out が付与された型パラメータなら戻り値、 in なら引数という単純なルールではなく、その型パラメータについて Covariant 、 Contravariant として扱っても安全かどうかによって out 、 in に違反していないかが判定されます。
定式化された判定方法は参考文献1が詳しいです。
Use-site variance annotation
Use-site variance annotation を採用した言語では、宣言時ではなく利用(Use)時に付与する Annotation によってジェネリック型の Variance を決定します。
Java では上限・下限付きワイルドカードを Annotation として使い、 Supplier<? extends Animal> とすれば Covariant に、 Supplier<? super Animal> とすれば Contravariant になります。また、単に Supplier<Animal> とすれば Invariant になります。
Declaration-site variance annotation で例に上げた Supplier 、 Consumer 、 Function のコードを Use-site variance annotation で書きなおすと次のようになります。
Supplier<Cat> catSupplier = ...;
Supplier<? extends Animal> animalAupplier = catSupplier; // Covariant
Consumer<Animal> animalConsumer = ...;
Consumer<? super Cat> catConsumer = animalConsumer; // Contravariant
Function<Animal, Cat> animalToCat = ...;
Function<? super Cat, ? extends Animal> catToAnimal = animalToCat; // TについてはContravariant、RについてはCovariant
欠点
見ての通り、 Declaration-site variance annotation では Supplier や Consumer などの型を宣言する際に一度だけ in や out と記述すればいいところが、 Use-site variance annotation ではそれらを利用する際に毎回 ? extends や ? super と記述しなければなりません。これは、単に面倒だというだけでなく、 Supplier は Covariant だと想定されているから ? extends にするといったことを、 その型の設計者ではなく利用者が常に把握していなければならない ことを意味します。
利点
一方で、 Use-site variance annotation では一つの型の Variance を Invariant にも Covariant にも Contravariant にもできるので表現力の幅が広いという利点があります。
例えば、 Animal の List を受け取って要素を表示するメソッドを考えてみます。
void printAnimals(List<Animal> animals) { ... }
このメソッドに List<Cat> を渡したくても、 List は Invariant なのでこのままでは渡せません。
List<Cat> cats = ...;
printAnimals(cats); // コンパイルエラー( List<Cat> is NOT a List<Animal> )
printAnimals は単に渡された List から Animal を取り出して表示するだけなので、 List には何の変更も加えません。そのため、このメソッドに限っては List が Covantiant であると考えても問題はおこりません。そこで、 ? extends を使って Variance を変更することで、 List<Animal> も List<Cat> も受け取れるメソッドを作ることができます。
void printAnimals(List<? extends Animal> animals) { ... } // Covariant
List<Cat> cats = ...;
printAnimals(cats); // 問題なし( List<Cat> is a List<? extends Animal> )
コンパイル時の型チェック
ところで、 "Hello, Variance!!" で見たように、 List が Covariant だと危険なコードがコンパイル時の型チェックをすり抜けてしまう心配がありました。 Use-site variance annotation で List を Covariant にするとどうなるのでしょうか。
List<Cat> cats = new ArrayList<>();
List<? extends Animal> animals = cats; // CovariantなのでこれはOK
animals.add(new Animal()); // コンパイルエラー
上記のコードでは add が(実行時ではなく)コンパイルエラーになります。 List<? extends Animal> のような Covariant な List は、 add や set など Covariant な List が持っているとおかしいメソッドは使えないものとして型チェックが行われます。そのため、 Use-site variance annotation であっても危険なコードがコンパイルをすり抜けてしまうことはありません。
※ 実際には、 add や set などのメソッド自体が利用不可になっているわけではありません。メソッドの引数の型が安全な範囲に限定されているだけで、 add メソッドであれば null を渡すことはできます。
Use-site variance annotation の問題点と対処法
これまでに見てきた Declaration-site variance annotation と Use-site variance annotation の利点・欠点についてまとめると次のようになります。
| Declaration-site variance annotation | Use-site variance annotation | |
|---|---|---|
| 利点 | 宣言時に一度だけ out, in を書けばいい |
より柔軟なケースに対応可能 |
| 欠点 | 対応可能なケースが限定されている | 利用時に毎回 ? extends, ? super を書かなければならない |
これだけを見ると一長一短で、どちらが望ましいとは言えないように思えます。しかし、 Use-site variance annotation で利用時に正しく Variance を指定するのは、その型の設計者ではない利用者にとってはとても難しいことです。
問題点
冒頭のコードを思い出して下さい。
interface Foo {
Comparator<Integer> getComparator();
}
interface Foo {
Comparator<? super Integer> getComparator();
}
Variance についてきちんと理解していなかったり、注意が足りなかったりすると前者のように書いてしまうのではないでしょうか。
前者が良くないのは Foo を継承して次のような Bar を作ることができないからです。
interface Bar extends Foo {
Comparator<Number> getComparator(); // オーバーライドして Comparator<Number> を返すようにする。
}
Comparator<Number> は Comparator<Integer> よりも広い型 Number に対応できます。もちろん、 Integer にも対応できるため、 getComparator メソッドの戻り値の型を Comparator<Number> でオーバーライドしても問題は起こらないはずです。不必要にそれを禁止してしまうのは良くありません。
これくらいのシンプルな例であれば少し考えれば ? super を付ければ良いとわかるかもしれません。しかし、より複雑な次の例ではどうでしょうか。次の qux メソッドの Animal にどのような Annotation を付ければ良いか考えてみて下さい( Baz と Qux に意味はありません。純粋に型のみから考えて下さい)。
interface Baz<T, U> {
Supplier<? extends U> baz(Consumer<? super T> consumer);
}
interface Qux {
Baz<Animal, Animal> qux(); // Baz<Animal, Animal> に適切に Annotation を付けたい
}
答えは↓です(説明は後述)。
interface Qux {
Baz<? extends Animal, ? super Animal> qux();
}
このように、 Use-site variance annotation で適切な Annotation を考えるのは複雑です。この複雑さこそが、比較的新しい言語で Use-site variance annotation が採用されていない理由だと思います。
対処法
とはいえ、 Java を使う以上 Use-site variance annotation と付き合っていかなければなりません。
ここからは僕の考えですが、 Use-site variance annotation を正しく使うには、 一度 Declaration-site variance annotation として考えてから Use-site variance annotation に変換すると良い と思います。
Declaration-site variance annotation で考えるのは難しくありませんし、 Use-site variance annotation に変換するのも簡単です。次の表のような単純なルールで変換できます。
| Declaration-site variance annotation | Use-site variance annotation | |
|---|---|---|
| 宣言時 |
<out T>, <in U>
|
<T>, <U>
|
| 利用時 |
<Foo>, <Bar>
|
<? extends Foo>, <? super Bar>
|
Variance がわかっている場合
前述の Comparator の例で考えてみます。 Comparator の T は compare メソッドの引数でしか使われていないので Comparator は Contravariant だと考えられます。そのため、 T には in が付与されていると考えます。
// 宣言時
interface Comparator<in T> {
int compare(T o1, T o2);
}
// 利用時
interface Foo {
Comparator<Integer> getComparator();
}
これを Use-site variance annotation に変換すると、「宣言時に in → 利用時に ? super 」なので、簡単に次のコードが得られます。
// 宣言時
interface Comparator<T> {
int compare(T o1, T o2);
}
// 利用時
interface Foo {
Comparator<? super Integer> getComparator();
}
これなら、 in か out かを知っていれば簡単に Use-site variance annotation に変換できます。次のような複雑な型であっても、
interface Foo {
Supplier<Comparator<Cat>> foo(Function<Consumer<Animal>, List<Animal>> function);
}
Declaration-site variance annotation での宣言を考えると
interface Supplier<out T> { ... }
interface Consumer<in T> { ... }
interface Function<in T, out R> { ... }
interface Comparator<in T> { ... }
interface List<T> { ... } // T は引数でも戻り値でも使われているので in でも out でもない
なので、機械的に Use-site variance annotation に変換できます。
interface Foo {
Supplier<? extends Comparator<? super Cat>> foo(Function<? super Consumer<? super Animal>, ? extends List<Animal>> function);
}
Variance がわかっていない場合
in か out かどちらでもないかわからない場合は、まずは Variance について考えます。
例として、前述の Baz について考えてみましょう。
interface Baz<T, U> {
Supplier<? extends U> baz(Consumer<? super T> consumer);
}
まずはワイルドカードを外します。
interface Baz<T, U> {
Supplier<U> baz(Consumer<T> consumer);
}
一見 T は引数で、 U は戻り値で使われているように見えますが、 Consumer は Contravariant 、 Supplier は Covariant です。
-
Consumer<Cat>>Consumer<Animal> -
Supplier<Cat>< `Supplier`
なので、 Baz<Cat, Animal> と Baz<Animal, Cat> で考えると前者の baz メソッドはより広い型を受けてより狭い型を返しているので、
-
Baz<Cat, Animal>< `Baz`
と考えても問題なさそうです。 T については Cat < Animal と方向が同じなので Covariant 、 U は方向が逆なので Contravariant です。つまり、 Annotation を付けると次のようになります。
interface Baz<out T, in U> {
Supplier<U> baz(Consumer<T> consumer);
}
ここまでわかれば、機械的に Use-site variance annotation に変換し、利用時には Baz<? extends Animal, ? super Animal> とすれば良いことがわかります。
難しいのは、 メソッドの型から Variance を考えただけでは不十分なケースがあることです。
例えば、 Java 8 で導入された Optional クラスの主な機能は次の通りで、 Optional は Covariant と考えると適切に思えます。
class Optional<T> {
T get() { ... }
void ifPresent(Consumer<? super T> consumer) { ... }
<U> Optional<U> map(Function<? super T, ? extends U> mapper) { ... }
...
}
-
Cat<Animal -
Consumer<Cat>>Consumer<Animal> -
Function<Cat, U>>Function<Animal, U> -
Optional<Cat>< `Optional`
しかし、 Optional クラスは次のようなメソッドも持っています。
T orElse(T other) { ... }
このメソッドから考えると Optional は T について Invariant でなければなりません。しかし、 Optional の本質ではないこのメソッドに引きずられて Invariant になってしまうというのも微妙な話です。
僕の考えでは、本来は orElse は次のような static メソッドとして宣言されているべきだったと思います(もし Declaration-site variance annotation で Optional を Covariant として実装するなら orElse をこうしなければならなかったはずです)。
static <T> T orElse(Optional<T> optional, T other) { ... }
このように、必ずしもその型の持つメソッドだけから既存の型の Variance を判断できるわけではありません。 Java は Declaration-site variance annotation ではないので、設計時にそこまで考慮されずにメソッドが実装されていることがあります。ですので、メソッドの型からだけではなく、その型の持つ本質的な機能まで考えて Variance を考える必要があります。
ただ、実際にはよく使うジェネリックなクラスやインタフェースは限られているので、それらの型パラメータが in か out かを覚えておけば困ることは少ないと思います。
下に Java の主要なクラス、インタフェースの型パラメータに in, out を付与したリストを示します。
Collection<E>
List<E>
Set<E>
SortedSet<E>
Map<K, V>
SortedMap<K, V>
Map.Entry<out K, V>
Iterable<out E>
Iterator<out E>
Comparable<in T>
Comparator<in T>
Optional<out T>
Supplier<out T>
Consumer<in T>
Predicate<in T>
Function<in T, out R>
BiConsumer<in T, in U>
BiPredicate<in T, in U>
BiFunction<in T, in U, out R>
UnaryOperator<T>
BinaryOperator<T>
Stream<out T>
Collector<in T, A, out R>
ジェネリックな型を自作する場合
主要な型については in か out かを覚えてしまえばいいですが、自作した型についてはそういうわけにはいきません。
ジェネリックな型を自作する場合は、 Declaration-site variance annotation のように型パラメータが in なのか out なのかどちらでもないのかを意識して設計するのが良いと思います。メソッドの引数や戻り値が in や out に違反していないか確認して下さい。
僕はわかりやすいように次のようにコメントを付けています。
class Foo</*in*/ T, /*out*/ U, V> {
...
}
また、 Java 8 からは型パラメータにアノテーションを付けられるようになったので、自作ライブラリを使ってアノテーションを付けています。
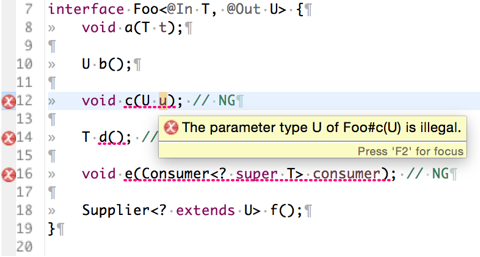
class Foo<@In T, @Out U, V> {
...
}
in 、 out が決まっていれば使うときは簡単です。
Foo<? super String, ? extends Number> getFoo();
ただ、宣言したクラスやインタフェースが正しく in や out を守れているかを検証するのはなかなか難しいです。前述のライブラリでは C# と同様のアルゴリズムによって @In, @Out による型チェックを行いエラーを報告してくれます。
? extends や ? super を書かなくても良い場合、書いた方が良い場合
利用時に out なら ? extends を、 in なら ? super を付与すると言っても、さすがにすべてのジェネリック型の変数にワイルドカードを使う必要はないと思います。
Optional<Animal> animal = Optional.ofNullable(...); // Optional<? extends Animal> でなくて良い
変数のスコープ内で Covariant や Contravariant であってほしいケースは稀だと思います。変数の型については必要なとき(そうしないとコンパイルが通らないとき)だけ ? extends や ? super をつければ良いでしょう。
しかし、メソッドの戻り値や引数、フィールドについては常に ? extends や ? super を付けた方が良いでしょう。前述の Comparator の例のように、 ? extends や ? super を書き忘れると本来問題ないことまで禁止してしまうことになります。
※ Java においては、"継承と Variance"で見たように継承してメソッドの引数の型を広げてもオーバーライドではなくオーバーロードとして扱われます。そのため、引数に対して ? extends や ? super が必要になるのは、ジェネリックな型がその型パラメータを別のジェネリックな型の型パラメータとして指定する場合だけです(例えば、 Foo<T> のメソッドで引数に Comparator などのジェネリックな型を指定し、その型パラメータとして T を使う場合など)。ただ、それ以外のケースでついていても特に害はないと思います。
List<? extends Foo> はダメ?
Declaration-site variance annotation 的に考えると List は Invariant なので List<? extends Foo> のように List に ? extends を付けて使うべきではないということになります。しかし、前述の
void printAnimals(List<? extends Animal> animals) { ... }
みたいなメソッドを作りたくなったらどうすれば良いでしょうか。
Java にはイミュータブルな List を表す型がありません。イミュータブルな List もミュータブルな List も List を共用します。その上で、 add や set のようなミュータブルな List 用のメソッドは optional operation なので、ミュータブルのときだけ実装して下さい(イミュータブルな List では UnsupportedOperationException をスローして下さい)という設計です。
この設計には苦々しい気持ちになりますが、そうなってしまっているものは仕方ありません。 add や set が oprional operation と言うのであれば、それらがないイミュータブルな List を想定しているケースにおいては List<? extends Foo> などとしても良いと思います。
しかし、現実問題としてそういうケースでは大抵 Iterable を代わりに使えば事足りるのではないでしょうか。
void printAnimals(Iterable<? extends Animal> animals) { ... }
Iterable は Iterable<out T> と考えることができるので、 ? extends を付けて
void printAnimals(Iterable<? extends Animal> animals) { ... }
としても問題ありません。
List<? extends Foo> を使うのは、すべてを理解した上で、イミュータブルな List として使いたい場合で、かつ Iterable ではダメなとき( get が使いたいときなど)に限定するのがいいんじゃないでしょうか。
PECSとの比較
PECS (producer-extends, consumer-super) は Java のワイルドカードの使い方に関する有名な戦略です。 Foo<T> から T を取得して利用する、つまり Foo が producer なら ? extends を、 Foo<T> に T を渡して処理させる、つまり Foo が consumer なら ? super を付けるというものです。これは、 in が引数でしか使えず、 out が戻り値でしか使えないことと同じようなことを言っており、その結果はほぼ Declaration-site variance annotation で考えたときと同じになります。
ただ、 PECS は Use-site variance annotation に基づいた考え方であり、一つの型の Variance を利用時に変更することに躊躇がないように思います。例えば、 Collections クラスの copy メソッドは次のように宣言されています。
// src から dest へコピー
static <T> void copy(List<? super T> dest, List<? extends T> src)
dest は consumer なので ? super 、 src は producer なので ? extends というわけです。これは前節で述べた考え方とはマッチしません。 copy メソッドに関しては利用時に List の Variance を変更しなくても、次のような実装をすれば十分ではないかと思います。
// src から dest へコピー
// ただし、 dest が src より短い場合のエラー処理などは省く。
static <T, U extends T> void copy(List<T> dest, List<U> src) {
ListIterator<T> destIterator = dest.listIterator();
Iterator<U> srcIterator = src.listIterator();
while (srcIterator.hasNext()) {
destIterator.next();
destIterator.set(srcIterator.next());
}
}
また、 PECS はあくまで利用時の指針であり、ジェネリック型を設計するときには役に立ちません。ジェネリック型を作るときは Declaration-site variance annotation 的な考え方で、型パラメータごとに in にしたいのか out にしたいのかを考えないと、 Variance について設計者の意図がよくわからない型ができあがってしまいます。
まとめ
? super や ? extends は Java でジェネリクスを使う上で特に難しい部分です。 C# や Scala 、 Ceylon など比較的新しい言語では、よりシンプルでわかりやすいアプローチが採用されています。
本投稿では、それらの言語で採用された考え方を元に、 Java の ? super や ? extends を使う方法を紹介しました。また、そのための前提知識として Variance(変性) の考え方について説明しました。最後に、 Java でよく用いられる PECS という戦略との比較をしました。
色々と調べながら書いた部分も多いので、おかしなところがあればご指摘下さい。