目的・背景
http://snapdish.co というサービスを開始して数年、カメラロールに大量の料理写真があります。でも、いつまでたっても私の撮影センスがいまいち。
そこで、「いい感じの写真だよ!」気軽に教えてくれるAIくんに助けてもらえなかなと妄想が膨らんできたので、作ってみちゃいました。
学習データの準備
データ収集のポイント
マンパワーに依存するデータ収集は非現実的でコストが高いので絶対やらない
データ収集の方法
SnapDishには、約1000万以上の料理写真があります。
そして、評判が良かった写真やリアクションがあまりなかった料理写真や規約違反の料理ではない写真があります。
そのデータを基に、以下の条件でデータを収集します。
- 遠い関係の人からのリアクションが、一定上ある料理写真 → YES画像
- まったくリアクションがとれなかった料理写真 → NO画像
- まったく関係のない写真 → NN画像
モデルの準備
モデルが正
まず、YES画像とNO画像の2値で学習させます。学習でできたモデルを使って、振り分けられた画像の予想結果の正しさを再評価し、YESなのにNO判定(FP)、NOなのにYES判定(FN)になった画像を省いて、残ったもので再学習を続けます。
モデルを正として、学習させる事前に対象の学習画像からFPとFNを分類して、学習を続けます。
結果、料理写真だけであれば、正解率が95%以上のモデルになります。ただ、まだ未知のデータに対しては、まったく当てにならない答えが帰ってくるので、次にその問題の対応しなければなりません。
NN画像
上記で学習されせた2値を返すモデルにNN画像クラスを追加して、3値で学習を進めます。幸い、SnapDishでは数万件の通報画像があり、数年かけて料理以外の画像を保持していたので、それをNN画像として利用することにします。
最終的に、 YES, NO, NNのどのクラスにその料理写真が近いか?という予想が得られる ことになります。
今回最も知りたいことは、真陽性 (True Positive/TP)のデータつまり、 その料理写真がどれだけYESに近いか?を知りたいので、YESのYESの予想、つまりTPの正解率を高くすることが重要 になります。
YESとNOだけだと、YESとNOの間にある未知のものが評価できません。NN画像を入れることで、YESでもなくNOでもなくNNでもないものは薄まり、NNなものはNN寄り、NOなものはNOに寄り、YESなものはYESに寄ると考えられます。
繰り返し学習させ、既知のデータでの正答率が95%を超えてきたら、 モデルの品質保証基準 を超えたことにできたらなと考えています。
YESだけどNO判定
次に、判定が間違った画像を使って、再学習を進め精度を高めていきます。
現在の結果
現在以下の結果が得られれています。
ちなみに、今回は合計で約30万の画像を学習に利用しています。
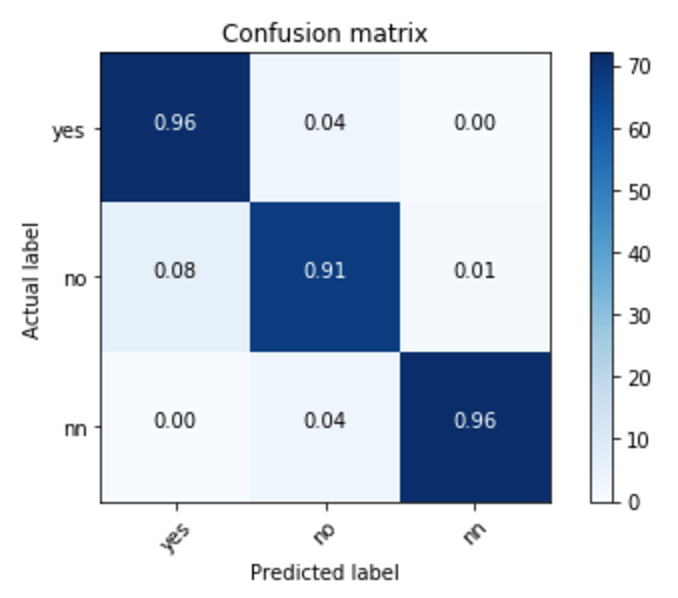
別の最新の料理写真をダウンロードしてそれをデータセットとして再度、正答率を試してみました。リアクションがなくてもリアクションがあるかもしれないというNOだけどYES判定(FN判定)が結構でました。
現在リアクションがないかもしれないデータが将来的にリアクションがある可能性を予想しているともいえます。データにゆらぎがある可能性が高いです。
FN判定が一番難しいところで、リアクションが今は少ないけどと解釈は可能かなとも言えます(強引ですがぁ)。
YESからみたTPが最重要 になってくるので方向性は間違っていないとも言えます。
実際データをみてみると私の目でもそこそこよい料理写真ではないかなと思うくらいです。
別の画像セットでの結果
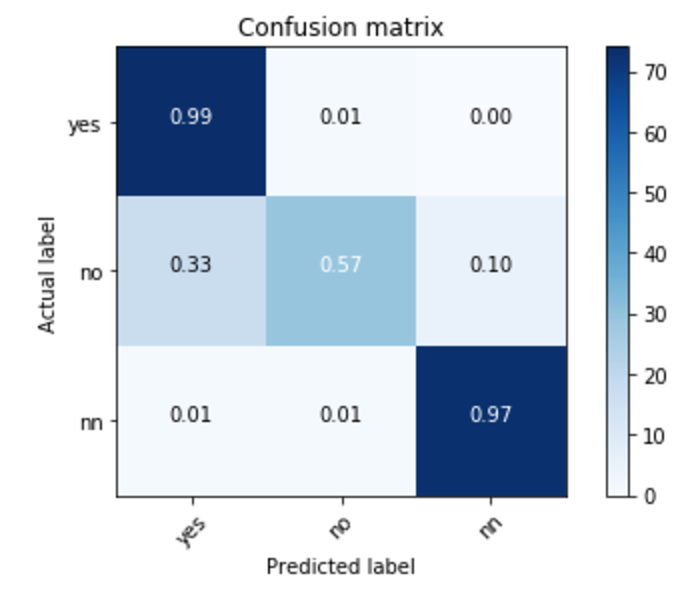
カッコ()は、(YES, NO, NN)どれに近いかの数値
FP判定(YESなのにNO判定)
徐々に救ってあげたいので、学習させる対象にする。

FN判定(NOなのにYES判定)
徐々に救ってあげたいが、現段階、学習させるとノイズも入る可能性があります。
そこそこ良い画像も混じっている印象です。

TP判定(YESでYES判定)
実際、リアクションが高い画像なので、安定のリアクションがとれそうな画像に見えます。

TN判定(NOでNO判定)
基本、SnapDishに投稿される画像内容は悪くはない、むしろ良いものが多いので予想は非常に難しいところですが、以下の内容になっています。

NOクラスの幅が結構あるので、その辺りが課題かなと思われます。
補足
世の中に存在する画像をクラス分けしたクラスごとの幅の関係は以下になります。
YESの幅 < NOの幅 < NNの幅
YESからしてみると、NOの中に将来的にYESになるものはあります。
NOからしてみると、NNは無限に存在しているので、NNにNOが存在するかもしれません。
例えば蝋細工の料理など。ただ、NOとNNの境目はファジーなものになります。ただ、サービスにとっては悪影響はないので深追いする必要がどこまであるかは考える必要があるかなと思います。
予想プログラムをAWSのlambdaにアップロード
今回は、pythonを使います。
numpyとcv2とchainerを使うので、その準備をします。
環境準備手順
ここにある手順で Python 3.6.0 を準備します。
http://qiita.com/kiyotaman/items/93689429a2c7652ed601
lambdaディレクトリをHOMEに作成してそこで作業をする前提で解説します。
以下準備します。
cd ~/lambda
├── 201707131838-TunedGoogLeNet-base.model # 今回資料するモデルデータ
├── deploy.sh # lambdaにファイルをアップロード
├── lambda_function.py # lambda_function
├── predict.py # 予想用のメインのクラス
├── requirements.txt # 必要パッケージ
├── test.jpg # テスト用の画像
├── test.sh # API Gatewayのテスト
└── venv # Pythonのvirtualenv
chainer==2.0.1
numpy==1.13.1
opencv-python==3.2.0.7
# !/bin/bash
cd ~lambda
/opt/python/versions/3.6.0/bin/python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
zip -9 ~lambda.zip
cd ~/lambda/venv/lib/python3.6/site-packages
zip -r9 ~lambda.zip *
cd ~/lambda/venv/lib64/python3.6/site-packages
zip -r9 ~lambda.zip *
cd ~/lambda
zip -r9 ~lambda.zip *.py
zip -r9 ~lambda.zip *.model
aws s3 cp ~lambda.zip s3://バケット名/lambda_function/
aws lambda update-function-code --function-name ファンクション名 --s3-bucket バケット名 --s3-key lambda_function/lambda.zip
# !/bin/bash
IMAGE=$1
API_KEY='************'
curl --request POST -H "x-api-key: $API_KEY" -H "Accept: application/json" -H "Content-Type: image/jpeg" --data-binary "@${IMAGE}" https://*****.execute-api.ap-northeast-1.amazonaws.com/prod/predict
echo "."
from predict import Predict
import json
import base64
def lambda_handler(event, context):
model = '201707131838-TunedGoogLeNet-base.model'
p = Predict(model)
img = base64.b64decode(event['base64Image'])
r = p.image(img)
return json.dumps(r)
# サンプルソースなので、コピペしても使えません。
class Predict:
def __init__(self, model):
self.model = model
self.arch = TunedGoogLeNet()
self.insize = TunedGoogLeNet.insize
chainer.serializers.load_npz(self.model, self.arch)
def cropimage(self, image): # もっとスマートの書き方あると思う
h_orig, w_orig = image.shape[0:2]
h, w = 256, 256
if h_orig == h and w_orig == w:
return image
elif h_orig == w_orig and h_orig != h:
return cv2.resize(image, (h, w))
if w_orig > h_orig:
w = int(w_orig*(h_orig/h)) \
if h_orig < h else \
int(w_orig*(h/h_orig))
elif w_orig < h_orig:
h = int(h_orig*(w_orig/w)) \
if w_orig < w else \
int(h_orig*(w/w_orig))
image = cv2.resize(image, (h, w))
top, bottom, left, right = 0, 0, 0, 0
if h > w:
top = int((h - w) / 2)
bottom = int(h - top)
to_h = h - top - (h - bottom)
if to_h < w:
bottom += w - to_h
elif to_h > w:
bottom -= to_h - w
image = image[:, top:bottom]
elif h < w:
left = int((w - h) / 2)
right = int(w - left)
to_w = w - left - (w - right)
if to_w < h:
right += h - to_w
elif to_w > h:
right -= to_w - h
image = image[left:right, :]
return image
def fit_image(self, image):
image = np.asarray(bytearray(image), dtype=np.uint8)
image = cv2.imdecode(image, 1)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
x = self.cropimage(image)
x = cv2.resize(x, (self.insize, self.insize))
x = np.float32(x) / 255.0
x = x.transpose(2, 1, 0)
return np.array([x])
def calc(self, x):
y = self.arch.forward(x, train=False)
y = F.softmax(y).data
return y
def image(self, image):
x = self.fit_image(image)
x = self.calc(x)
score = self.score(x)
yes, no, nn = int(x[0][0]*100), int(x[0][1]*100), int(x[0][2]*100)
return {'score': score, 'yes': yes, 'no': no, 'nn': nn}
def score(self, y):
return ((y[0][0] * 0.9) + (y[0][1] * 0.3)) * 100
lambdaにアップロード
$ ./deploy.sh
lambdaに deploy.sh を使ってアップロードして、AWS API Gateway経由で、処理ができるようになります。
AWS API Gatewayの設定
基本的に簡単です。googleってみてください。まずは、Usage Plansを作って、API Keysを作っておくとtest.shのx-api-keyにそれを設定して使うことができます。
ポイントは、body mapping templateで設定した内容が、lambda_functionのeventに入ってくるので、その設定を正しくします。(もしかしたら不要なのかな?)
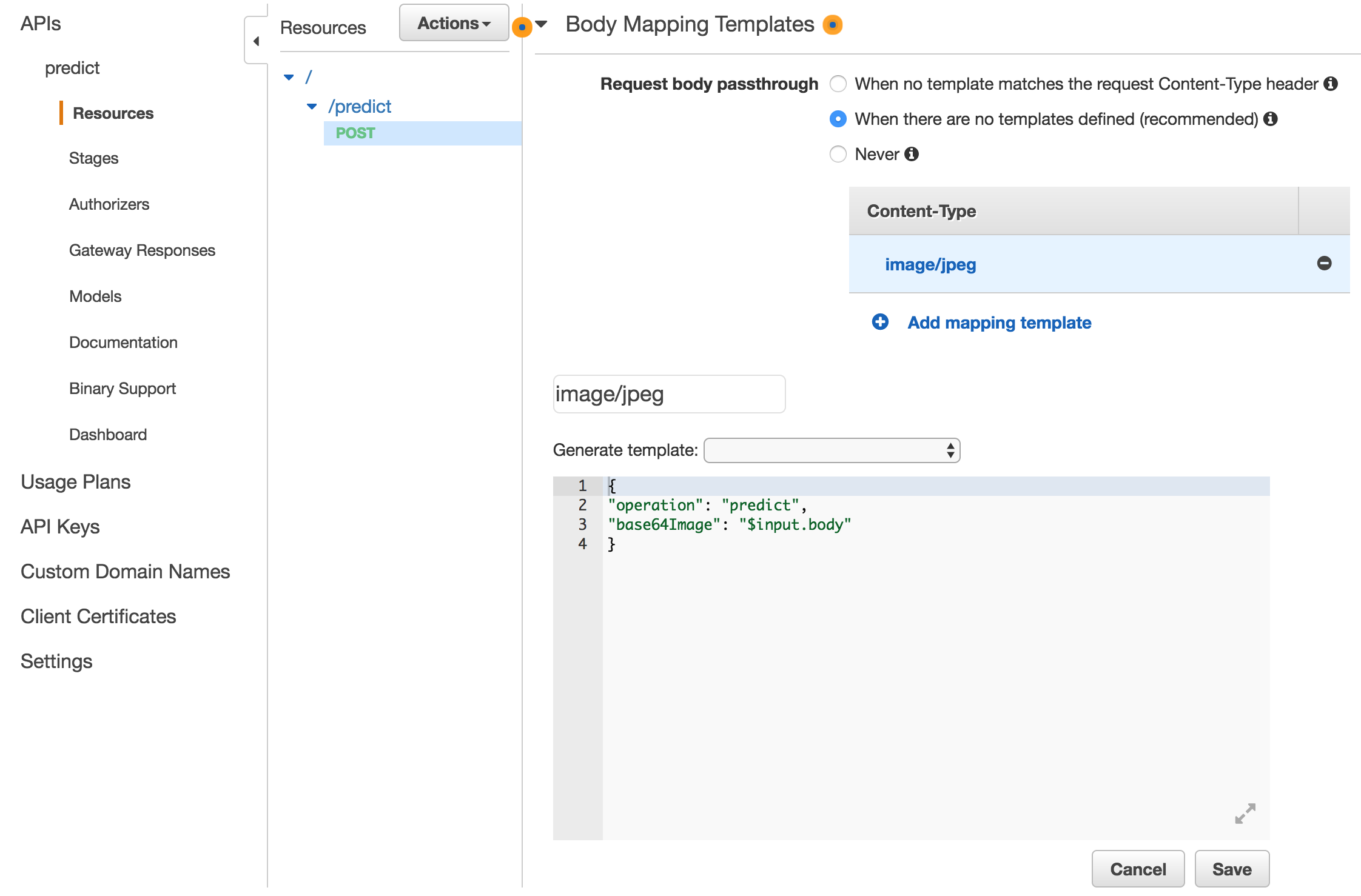
# こんな感じで、lambda functionからbodyデータがとれます
img = base64.b64decode(event['base64Image'])
AWS API GatewayとLambdaの関係
Lambdaはevent駆動だと思っていたので、全て非同期で動くのかなと思っていたのですが、API Gatewayと連動させると、RequestResponseでnot非同期で動いてくれます。今回のテストでは、その方が都合よいので重宝しています。
動作確認
$ ./test.sh test.jpg
"{\"score\": 74.66125801205635, \"yes\": 78, \"no\": 13, \"nn\": 8}"
まとめ
動作することろまで確認できました。レスポンスが6000msでメモリが200m使う感じです。バックエンドにai engineサーバーを置いてそこでpredictを動かすということも考えられるかなと思いました。このレスポンスだとプロダクションUSEは厳しいのかなというのが正直な感想です。レスポンスを速くできる方法があれば教えて頂きたいところです。