はじめてAPIサーバーの負荷試験を行ったので、その時に学んだ負荷試験の目的、準備やチューニング方法の例や難しいと感じた所などを簡単に紹介したいと思います。

負荷試験の目的
-
サーバー1台につき、「○○以上の性能は出ません。」という上限の数字を出す。
-
これがわかっていれば、アクセス数に対して、どれくらいのサーバー台数で耐えれるのかがわかります。
-
チューニングを行い、パフォーマンスを上げる。
-
サーバー1台の上限値を出す際に、1台のスループットが良ければそれにこした事はありません。その為、負荷試験時にチューニングを行い性能向上をはかります。
-
システムのスケールが可能な構成であることを担保。
-
サーバー台数を増やしても、負荷が分散しなくては意味がありません、ちゃんと負荷が分散する事を事前に確認します。
使ったもの
・Djangoで作成したAPIサーバー
・locust (pythonで書ける負荷試験ツール)
・New Relic (パフォーマンス監視サービス)
目標数値を想定する
やみくもに、チューニングしても意味が無いので、まずは、目標値として最低限必要な性能値の想定します。
今回は
-
サーバー1台の限界値とするCPU使用率を決めておく。
- どれだけの余裕を持たせた状態を限界値とするかを決めます。
- これを決めておく事で負荷試験時には、決定したCPU使用率を維持した状態で捌けるリクエスト数がこのサーバーの限界値となります。
-
このサーバーが分間に捌く必要のある最大リクエスト数を想定。
- この数値は、最大で分間(または秒間)にどれくらいのリクエストを捌く必要があるのかを想定した数字になります。
- 1台でどの程度のリクエスト数が捌ける(1台の限界値)のかが決まった場合、最終的に「最大リクエスト数 ÷ 1台の限界値」で、サーバーが何台必要なのかを出す事ができます。
例えばDAUなどから、ピーク時のアクセス数の想定が12000rpmとし、サーバー1台の使用して良いCPU使用率は50%であるとします。
※RPM (分間に捌けるリクエストの数)
※RPS (秒間に捌けるリクエストの数)
その場合にサーバー台数を4台に抑える事を目標とした時に、
1台あたり、CPU使用率50%時に3000RPMを捌ける事が目標と言う事になります。
ちなみに、負荷試験時のサーバー構成はこの様になります。
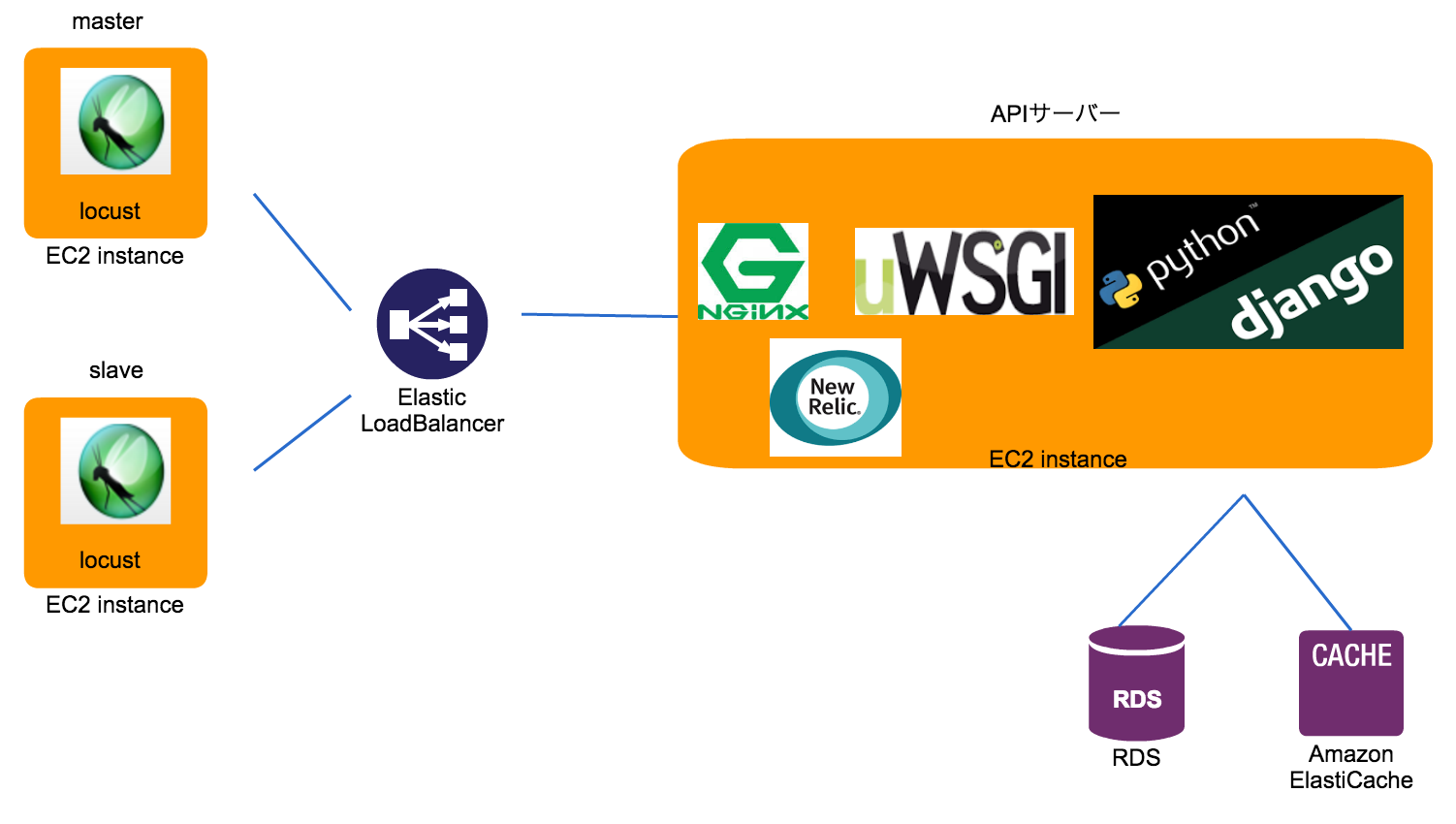
まずは、1台あたりの数字を見る為にまずはAPIサーバー1台で負荷試験を行っていきました。
New Relicは、APIサーバー1号にのみに搭載しています。
Locustで負荷試験シナリオの作成
では、次に負荷をかける為に、Locustの準備をします。
Locustの使い方についてはこちらが参考になります。
どのAPIがどのくらいの割合で呼ばれるのかを想定して、シナリオを作成します。
下記は簡単なシナリオの例です、クライアント作成時に1回だけUser登録を行い、以後signinAPIとstatusAPIを順不同で呼ばれます。
ただし、taskデコレーターで各APIの呼ばれる割合を指定しています。
# -*- coding:utf-8 -*-
"""
一通りの動きを1週するシナリオ
"""
from locust import HttpLocust, task, TaskSet
class ScenarioTaskSet(TaskSet):
def on_start(self):
"""
userの登録
ここで、各クライアントで必要な情報を用意する
"""
self.user_id = "xxxxxxxxxxxxxx"
self.client.headers = {
'Content-Type': 'application/json; charset=utf-8',
}
self.client.post(
'/user/signup',
json={
"user_id": self.user_id,
}
)
@task(1)
def signin(self):
"""
userログイン
"""
self.client.post(
'/user/signin',
json={
"client_id": self.client_id,
}
)
@task(10)
def status(self):
"""
user情報の取得
"""
self.client.post(
'/client/status',
json={
"client_id": self.client_id,
}
)
class MyLocust(HttpLocust):
task_set = ScenarioTaskSet
# task実行の最短待ち時間
min_wait = 1000
# task実行の最大待ち時間
max_wait = 1000
そして下記コマンドで実行します。
locust -H http://apiserver.co.jp(←負荷をかけたいサーバー)
ブラウザでアクセスしてlocustのTOP画面が出たらlocustの準備は完了です。
あとは、user数と増幅率を指定すれば、負荷試験を開始できます。
実際に開始してみると、この様にブラウザ上で負荷をかけている情報を確認できます。
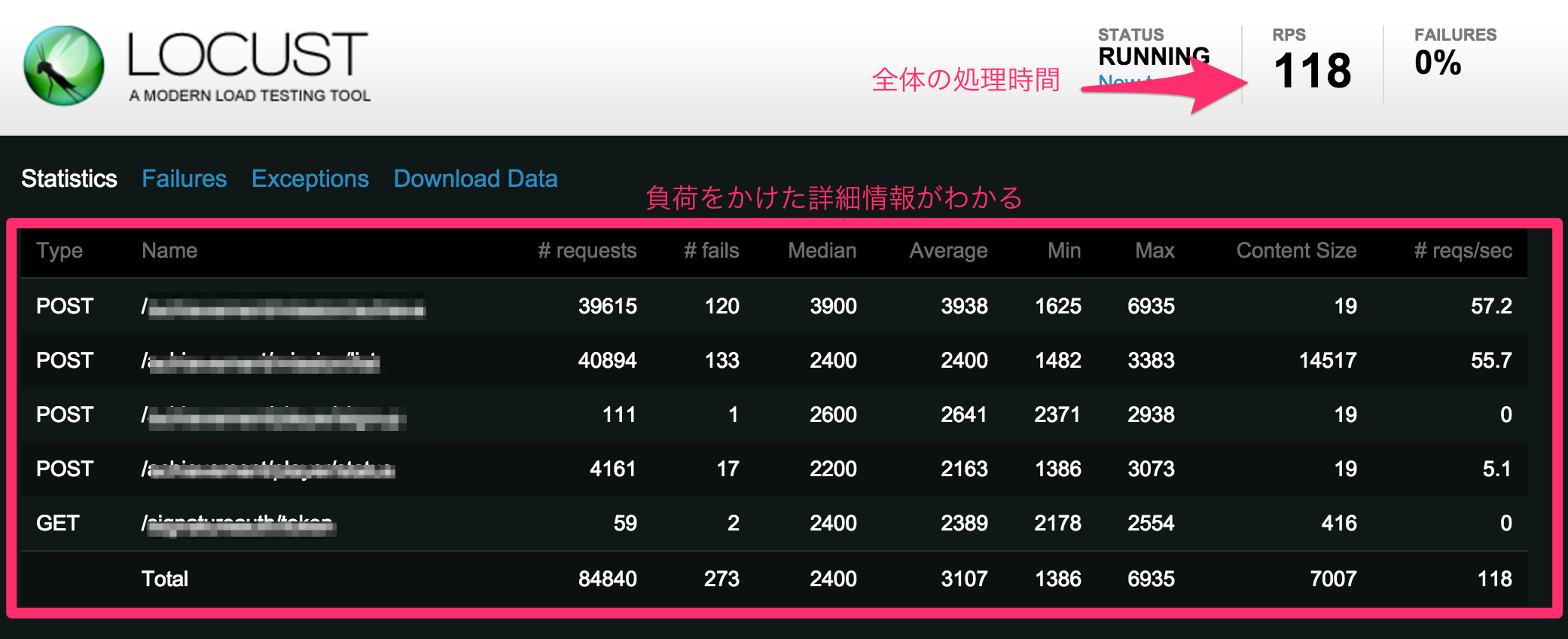
locustには複数のスレーブと同期する機能があり、今回もlocust専用のサーバーを10台ほど用意して、最終的には10台のlocustサーバーからAPIサーバーへ負荷をかけました。
New Relic
locustの準備ができたら、実際に負荷をかけてみて、New Relicで負荷状況を確認していきます。
今回の負荷試験では、このNew Relicが主役になります、パフォーマンスのチューニングをしていく際に、locustで負荷をかけNew Relicで負荷がかかっている箇所を調べて、チューニング目星を付けて改修作業を行います。
(DjangoアプリにNew Relicを設定する方法はこちらが参考になります。)
New Relicを確認する
では、実際に負荷をかけて、New Relicを見てみましょう。
下記がNew Relicの「OverView」になります。
このページで全体の情報を見る事ができます。
これは、チューニングをする前のデータですが、スループットが43rpmになっています。
これはかなりひどいですね。
また、「web tarnsaction response time」グラフでは、処理の種類毎に色分けされていて、今回の例だと水色が大半を占めているので、全体的にPython処理で時間がかかりすぎている事がわかます。
下のTransationを見るとAPIの処理に時間がかかりすぎている事や、Error rateではエラーが多発していることも分かります。
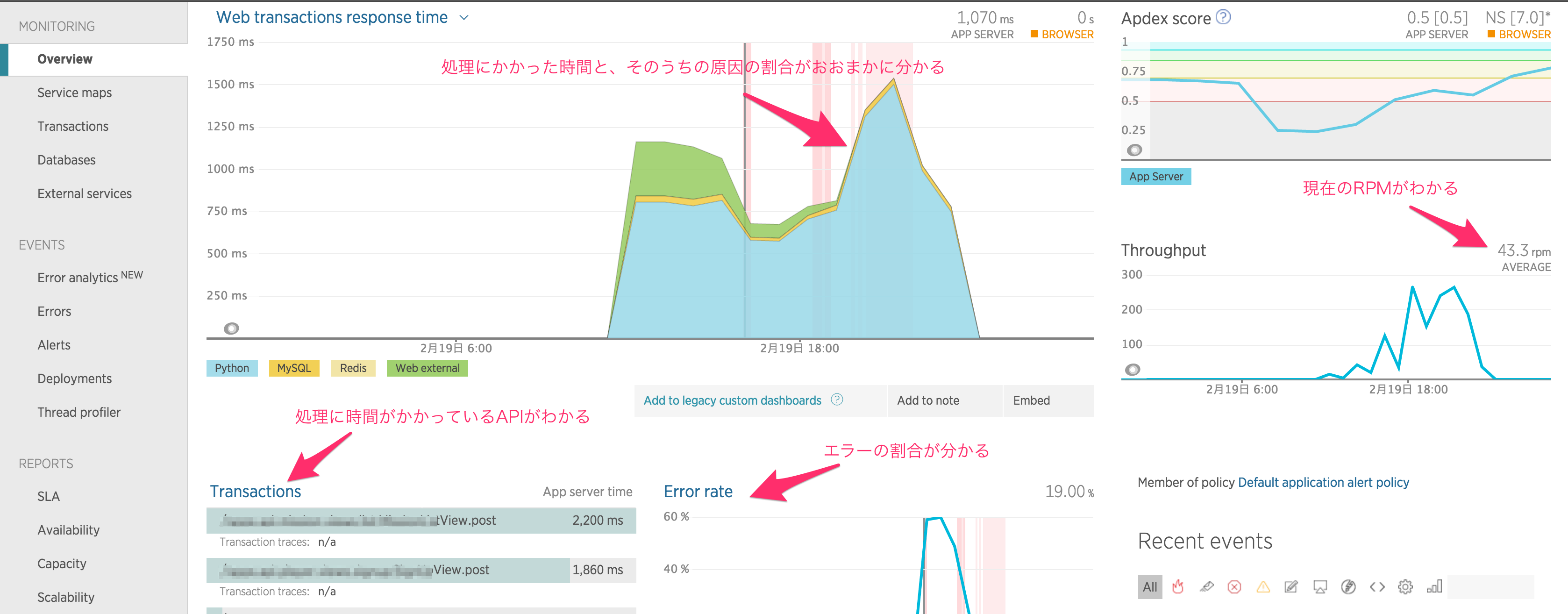
これらのデータを元にチューニングを行い、目標のパフォーマンスまで引き上げて行きます。
では、どのようにチューニングを行うのか、簡単な例を紹介します。
チューニング
処理が遅い時、どのAPIがネックになっているのかを確認する為にNew RelicのTransactionsページを見てみます。
Most time conumingを選択すると、リクエストの処理が遅い順に表示されます。
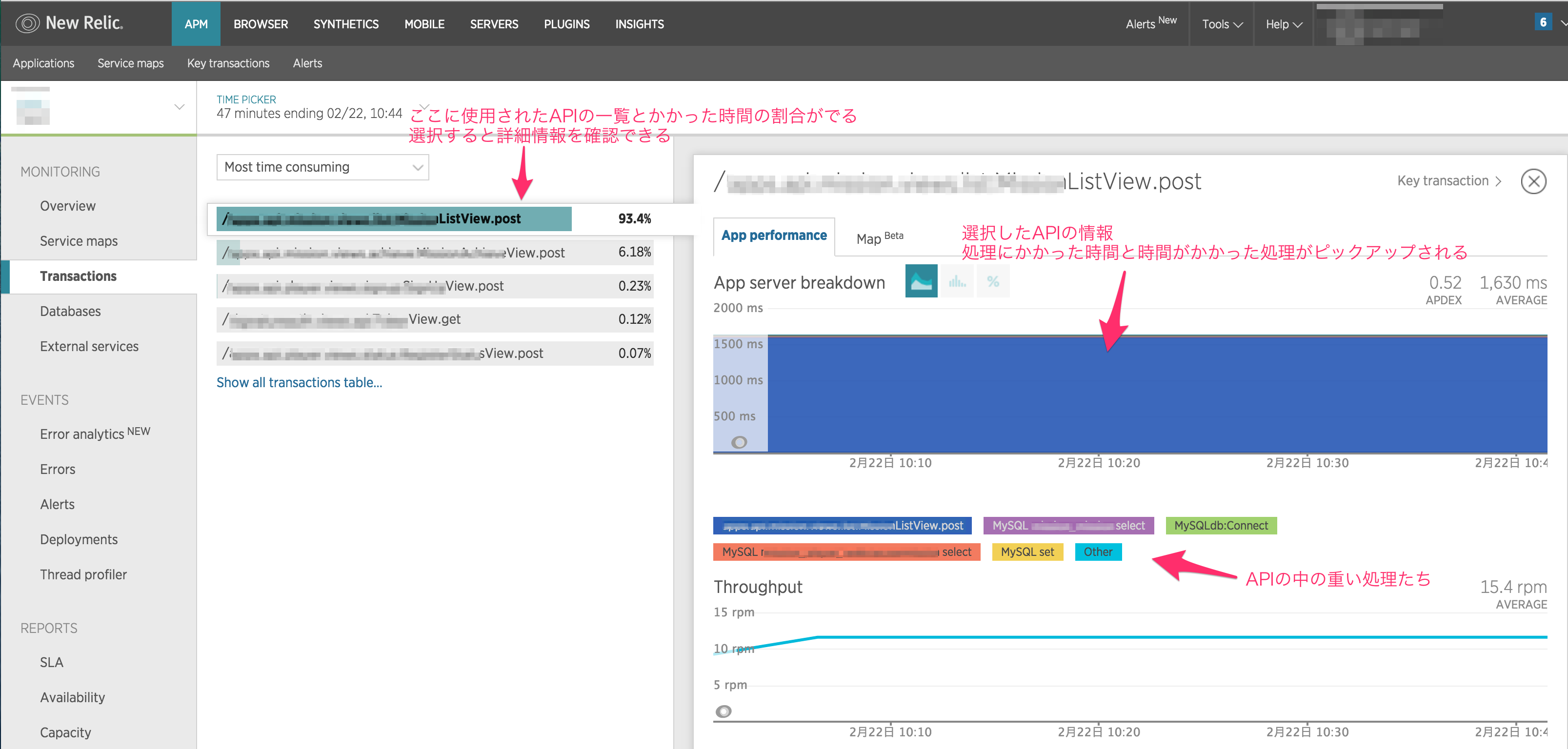
ちなみに今回はpythonの処理が原因の大半を占めているため、「App Server breakdown」青一色ですが、通常はこんな感じで処理毎の割合が可視化されています。
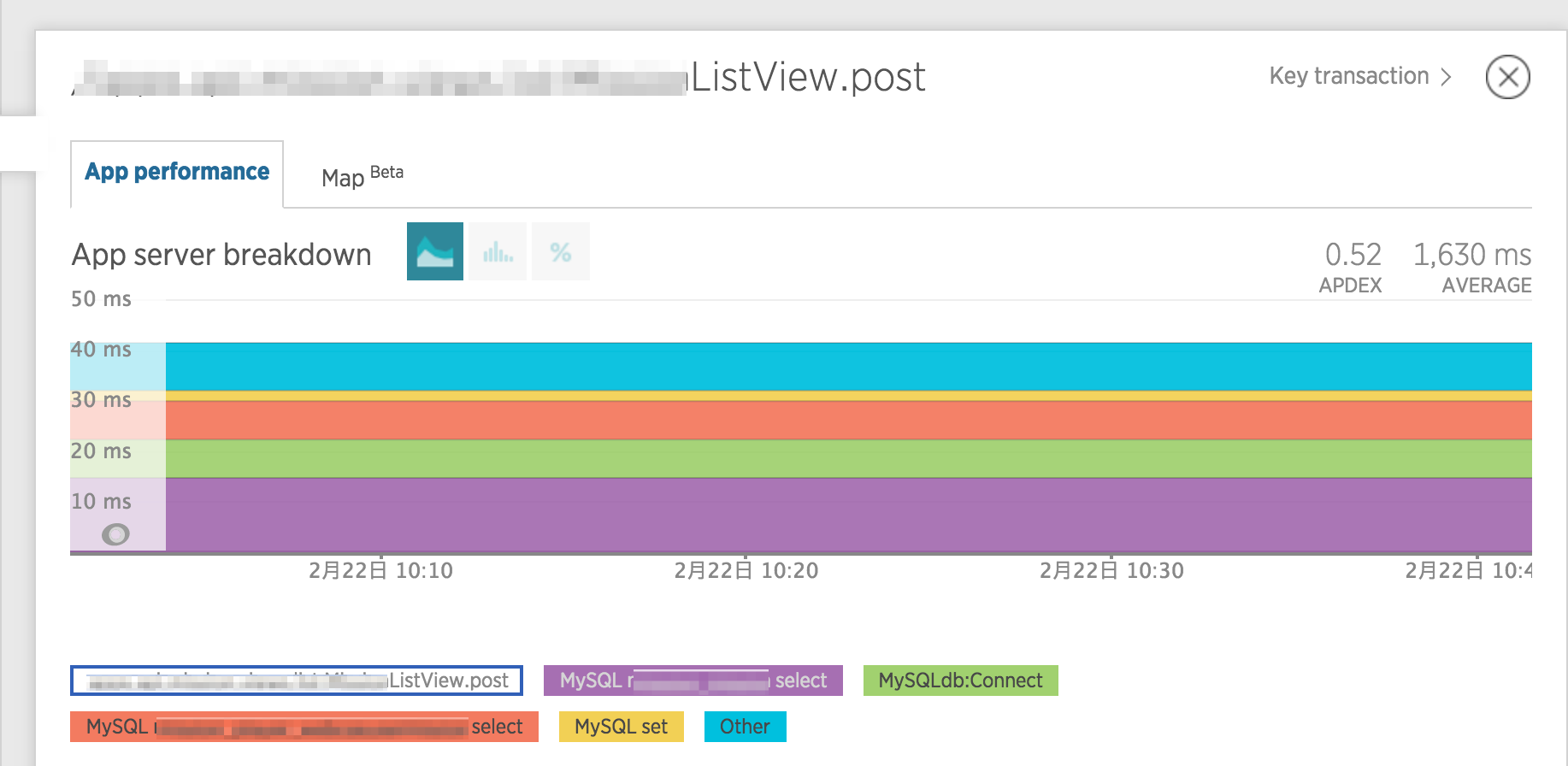
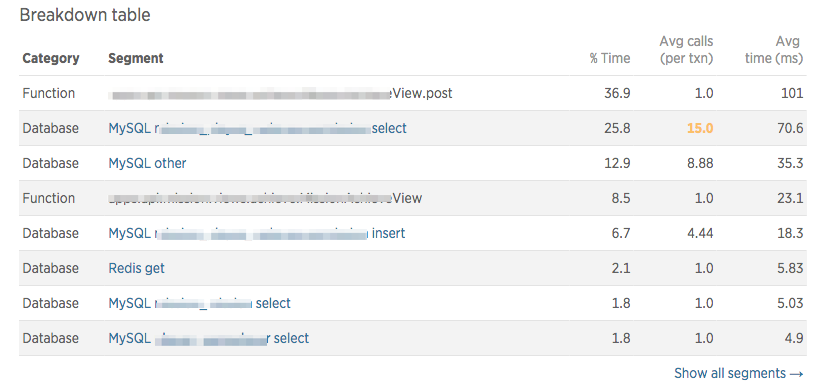
さらにグラフの下には、「Breakdown table」が表示されていて、ここで、SQLも含めてどこで時間がかかっているのかが分かります。
SQLクエリの呼び出し回数(Avg calls) が異常に多かったり、処理に時間がかかっていたりした場合は改修します。
今回は、複数回呼ばれていたクエリを1つにまとめてAvg callsを1にしたり、Timeが遅いSQLはINDEXを周りを調整してTimeを縮めたりして、チューニングを行いました。
しかし、pythonが処理している部分を指すfunctionはここでは詳細を確認する事はできません。
そこで「Breakdown table」の下の「Transaction traces」からTransaction traceページを表示して、もっと詳細な情報を見る事ができます。

例えば、「Trace details」では、この様に処理される順番に処理内容が表示されるので、どこの部分の処理が原因なのか改修箇所に目星をつける時にはかなり便利です。
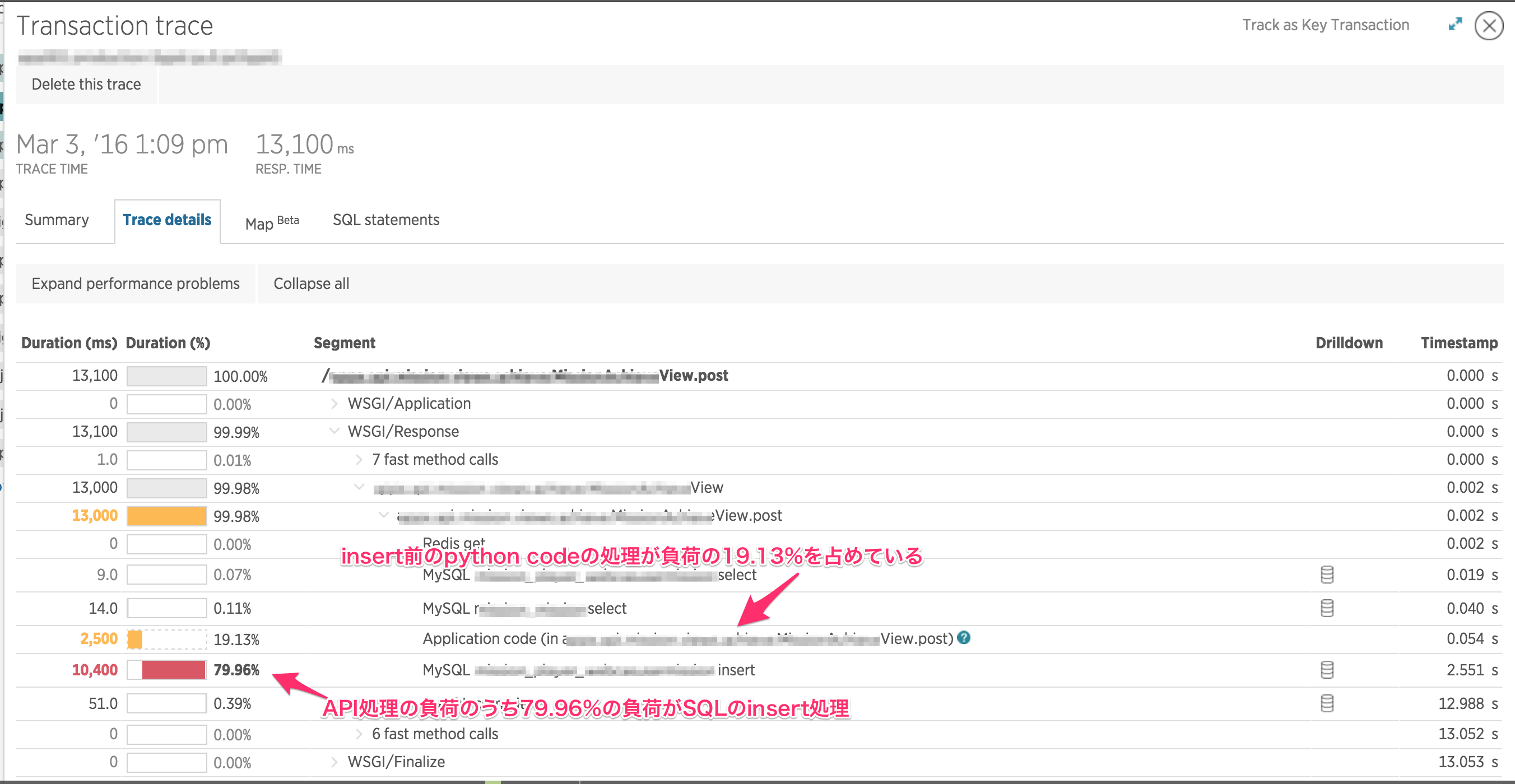
今回の場合は、INSERTする前に、2つのテーブルからSELECTしてきた内容をpythonのループ処理でまとめ、その内容をINSERTしていました。
「Trace details」と照らし合わせると、負荷がかかっているApplication codeはpythonのループ処理の部分だと判断ができます。
なので、ループ処理の負荷を軽減させる事によって、Application codeで問題となっている箇所を解消する事ができました。
基本的にはこの様に「負荷をかける → 原因調査 → 原因箇所を改修し、パフォーマンス改善」の繰り返しで、目標値であるCPU使用率まで安定してリクエストを捌け、もう改修できる所が無いだろうという所まで、SQL処理やコード処理を含めたあらゆる原因箇所の改善を行いサーバーのパフォーマンスを上げていきます。
限界値を計る
サーバーのチューニングが完了したら、いよいよ限界値を測定します。
CPU使用率50%を上限とするため、topコマンドでサーバーのCPU使用率を確認しながら負荷をかけます。
まずはCPU使用率が50%になるまでに、処理が安定している事をlocustのブラウザ画面で確認しつつ、locustの調整をし、CPU使用率が50%前後で負荷をかけ続けるようにします。
この時点でlocustのRPSから計算でRPMを求めても良いのですが、今回はNewRelicの数値を参考にパフォーマンスの調整を行っているので、統一する為にNewRelicのRPMを確認し、サーバーの限界値としました。
これにより、サーバー1台のパフォーマンスが決定したので、後は台数を増やしてちゃんと負荷分散しているかを確認できれば、運用時に必要な台数を用意するだけで大丈夫です。
ここが難しいよ負荷試験
ざっくりと負荷試験のやり方を紹介しましたが、これはほんの一例で、実際に試験をやってみると色んな壁がたくさん立ちはだかります。
- Locustのシナリオを考えるのが難しい
- Task同士に依存性がある場合のシナリオの調整や、データの更新頻度の考慮などが難しかった。特にデータの更新頻度などは、負荷に直結する内容なので、これだけで負荷試験の結果が大きく変わる。
- 外部サービスのAPIを叩いている
- この場合は外部サービスの負荷が、どれほど影響するのかを算出する必要があり、その方法を考えるのが難しかった。
- 負荷が起きている箇所の原因調査が難しい
- 見るからに負荷の大きそうなコードであったり、SQL文が原因の場合は、今回紹介したような手順で目星を付け修正する事ができますが。一見問題なさそうに見えるのになぜかうまく行っていないというパターンも多く、その場合はいろんな角度から解決アプローチを考える為に、たくさんの知識や経験の持っている事が要求されます。
まとめ
今回、紹介したNew Relicの使い方やチューニング手順を抑えておけば、ある程度基礎的な負荷試験はできるかもしれません。
ただし、実際にはもっといろんな問題が発生し、いろんなチューニングのアプローチが必要です。
はじめて行う場合は、経験者の助言を受けながら試験を行う事をお勧めします。
結構いい感じにパフォーマンス向上できたと思ったら、経験者に確認してもらったら実は負荷をかける量が足りてなかったなんて事は大いにありえると思います。
また、負荷試験は険しいため、自分自身のスキルが低いと、サーバーの負荷をかける度に、自分にも負荷がかかってしまい、誰の負荷試験なのか分からなくなってしまうかもしれません。
しかし、その分勉強になるので、きっと、辛い負荷試験を終えた暁には、サーバーも自分もスループットが格段に上がっている事でしょう!
チャンスがあれば一度は経験しておくと、すごく勉強になると思います。
きっとあなたも、一緒に苦楽を共にしたサーバーと友情が芽生えるはず☆