最近なんだかSparkっていうのがすごいらしい。
ちょっと試してみたいけどHadoopクラスタとか組むの大変だし。。。
と感じている方も多いのではないでしょうか。
大丈夫です。SparkはローカルPC上でもちゃんと動きます。
今回はEclipseでSparkアプリを開発、実行する手順を紹介します。
もちろん普通のJavaアプリケーションと同様にデバッグ(ステップ実行)することもできます。
OSはWindows10で説明しますが、MacやLinuxでもほとんど同じ手順でいけると思います。
(そもそもOSやEclipseについては詳しく説明していません)
まずは定番(?)の「Hello World !」をコンソールに表示するSparkアプリケーションを書いて動かしてみましょう。
【1】 インストール
ローカルPC(Windows 10 Home 64bit)上に開発環境をインストールします。
[1-1] Java SE 8(1.8) 64bit インストール
OracleのサイトからJavaをダウンロードしてインストールします。
[1-2] Eclipse Pleiades All in One 4.5.1 Java 64bit Standard Edition インストール
PleiadesのサイトからEclipseをダウンロードしてインストールします。
解凍したeclipseフォルダを適当なフォルダ1にコピーします。
【2】 セットアップ
Eclipseに開発環境をセットアップします。
eclipseフォルダのeclipse.exeをクリックしてEclipseを起動させます。
[2-1] プロジェクト作成
パッケージエクスプローラーの白い背景を右クリックし、「新規」→「その他」をクリックします。
「Maven プロジェクト」を選択して次へ進み、「シンプルなプロジェクトの作成」をチェックして次へ進みます。
適当にグループIdとアーティファクトIdを入力し、完了します。
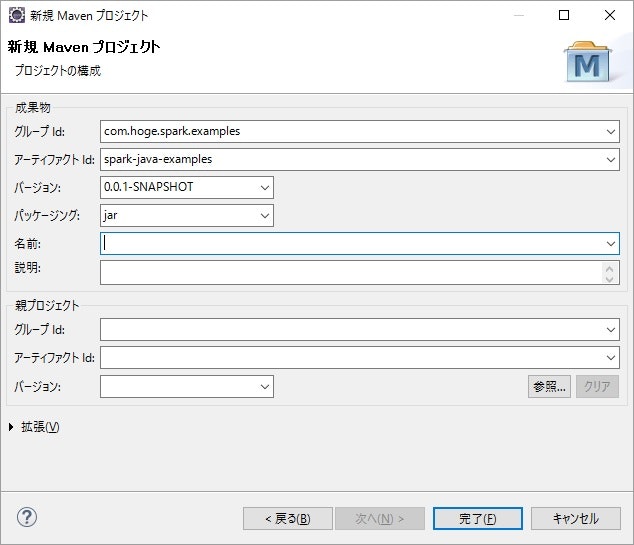
[2-2] pom.xmlファイル修正
プロジェクトの直下にあるMavenビルドファイルpom.xmlにSparkの依存関係を追加します。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hoge.spark.examples</groupId>
<artifactId>spark-java-examples</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spark-java-examples</name>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
<properties>
<java.version>1.8</java.version>
</properties>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
[2-3] Maven実行
Mavenのeclipse:eclipseゴールを実行すると、依存関係やクラスパスが設定されます。これ、最高に便利です。
パッケージエクスプローラーのpom.xmlファイルを右クリックし、「実行」→「Mavenビルド」をクリックすると、依存jarをダウンロードし2、クラスパスが設定されます。
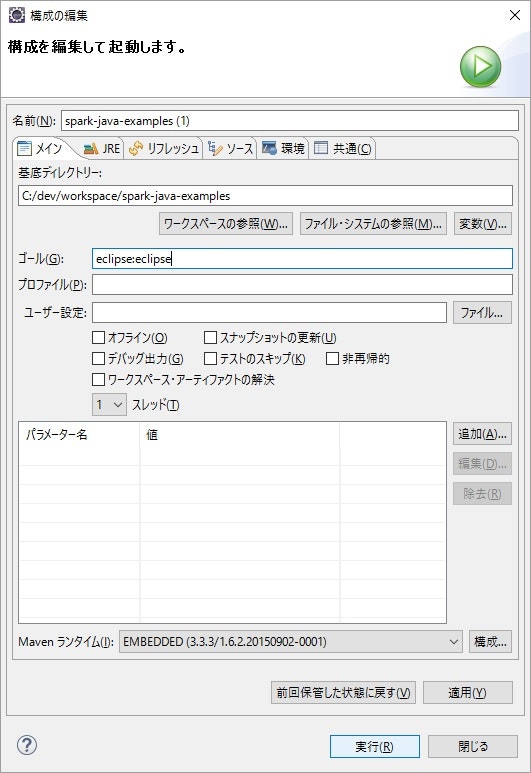
更新された内容を反映するため、パッケージエクスプローラーのspark-java-examplesプロジェクトを右クリックし、「リフレッシュ」をクリックします。
「プロジェクト構成がpom.xmlの最新ではありません」みたいな意味不明なエラーが出るので、パッケージエクスプローラーのspark-java-examplesプロジェクトを右クリックし、「Maven」→「プロジェクトの更新」→「OK」をクリックします。
【3】 Hello World ! 実装&実行
[3-1] パッケージ作成
パッケージエクスプローラーのsrc/main/javaフォルダを右クリックし、「新規」→「パッケージ」をクリックします。
「名前」に「com.hoge.spark.examples」を入力し、完了します。
[3-2] クラス実装
パッケージエクスプローラーのsrc/main/javaフォルダの下にあるcom.hoge.spark.examplesパッケージを右クリックし、「新規」→「クラス」をクリックします。
「名前」に「HelloWorld」を入力し、「public static void main(String[] args」にチェックを入れて、完了します。
HelloWorldクラスを以下のように実装します。
package com.hoge.spark.examples;
import java.util.Arrays;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class HelloWorld {
public static void main(String[] args) {
try (JavaSparkContext sc = new JavaSparkContext("local", "Hello World")) {
JavaRDD<String> rdd = sc.parallelize(Arrays.asList("Hello", "World", "!"));
rdd.foreach(val -> System.out.print(val + " "));
}
}
}
[3-3] クラス実行
パッケージエクスプローラーのHelloWorldクラスを右クリックし、「実行」→「Javaアプリケーション」をクリックします。
コンソールビューに大量の赤文字と黒文字「Hello World !」が表示されます。
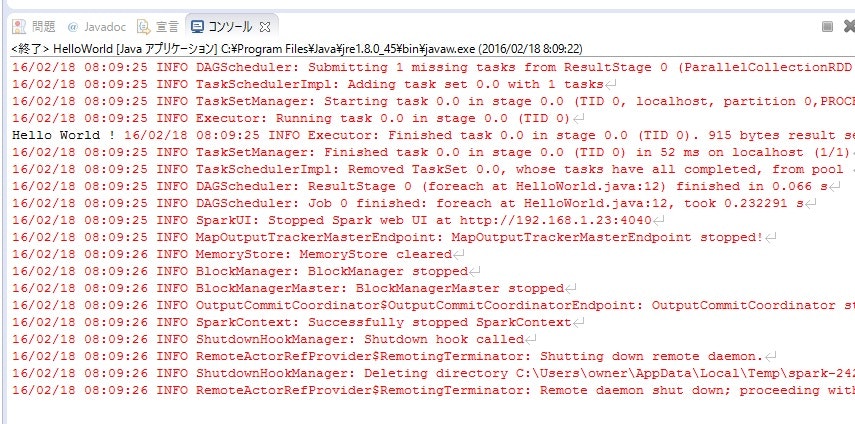
赤文字がジャマなので、ログの出力レベルをINFOからERRORに変更しておきます。
パッケージエクスプローラーのsrc/main/resourcesフォルダを右クリックし、「新規」→「ファイル」をクリックします。
「ファイル名」に「log4j.properties」を入力し、完了します。
log4j.propertiesファイルに以下の内容を書きます。
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
もう一度HelloWorldクラスを実行すると、今度は「Hello World !」だけが出力されるはずです。
【4】 おまけ winutils.exeが見つからない問題
今回は元になるデータを
JavaRDD<String> rdd = sc.parallelize(Arrays.asList("Hello", "World", "!"));
のように、プログラム内で生成したので問題ありませんでしたが、
JavaSparkContext.textFile("ファイルパス");
のようにファイルからデータを読み込むと、winutils.exeが見つからないというエラーが発生します。
16/02/18 21:17:24 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278)
winutils.exeはWindows上でHadoopを動かすときに使うのですが、どうやらSparkでファイルを読み込む際にこの実行ファイルを探しにいって、見つからずにエラーが起きているようです。
この問題を解決するにはwinutils.exeをローカルPC上に置いて読めるようにしてやる必要があります。
あらかじめC:\dev\hadoop\binというフォルダを作っておきます。
hadoop-winutils-2.6.0.zipをダウンロードし、winutils.exeファイルを取り出してC:\dev\hadoop\binフォルダの中にコピーします。
次にOSの環境変数HADOOP_HOMEを設定するか、Javaのシステムプロパティhadoop.home.dirを設定します。
ローカルPC環境とクラスタ環境の両方でちゃんと動くように、OSの環境変数を使ったほうがいいでしょう。
環境変数HADOOP_HOMEを作って値に「C:\dev\hadoop」を設定し、Eclipseを再起動します。
HelloWorldクラスを実行すると、winutils.exeが見つからないエラーは起きなくなっているはずです。
【5】 まとめ
これでローカルPC上でSparkアプリケーションを開発する環境が整いました。
あとはRDDなどのSparkのAPIを使い込んで慣れていくだけです。
今回のコードはGitHubにあげておきましたので、手順を実行するのも面倒くさい!という方はそちらを使ってみてください。
今後はRDDのサンプルコードを追加していこうかなと思っていますので、よろしくお願いします。