こんにちは。
皆さん、Apache Kafkaは使っているでしょうか?
最近はHadoop、Sparkの他Storm、Spark Streaming、Flink、Gearpumpのようにストリーム処理系プロダクトとペアで使われることが多く、リアルタイムな処理を行う場合にはかなりつかわれるプロダクトになってきていると思います。
ですが、実際に使ってみると困ることもあるわけでして・・・
で、それを解決できる可能性があるConfulent Platformというプロダクトが出ていました。
ですので、それを追ってみることにします。
参照:
http://docs.confluent.io/2.0.0/platform.html
Confluent Platformとは?
Confluent Platformとは、毎秒大量のデータが到達する事業環境を整理し、管理可能なストリームデータ基盤。
Confluent Platformを用いることで、常に成長し続ける構造化されていない、だが価値あるデータ群を組織内で統一的に、容易にアクセス可能なストリームデータ基盤を構築することが可能となる。
Confluent PlatformによってHadoopを用いたバッチ処理によるビッグデータ解析からリアルタイムのモニタリングシステム、加えて他の古くから存在する大規模データ処理についても統合し、高スループットなETLバックエンドを構築することが可能となる。
Confluent Platformは何を含んでいるか?
Confluent Platformはインフラサービス、ツール、後はあなたの会社の全データを容易にリアルタイムストリームとして扱えるようにするガイドラインからなっている。
異なるITシステムの様々なデータを1個の中央ストリームデータ基盤に統合し、神経系と化すことができる。
Confluent Platformを使うことによって、あなたはデータを如何に異なるデータ間で往復、切替、ソートするかを気にすることなく、ビジネス的な価値を導き出す活動に専念することができる。
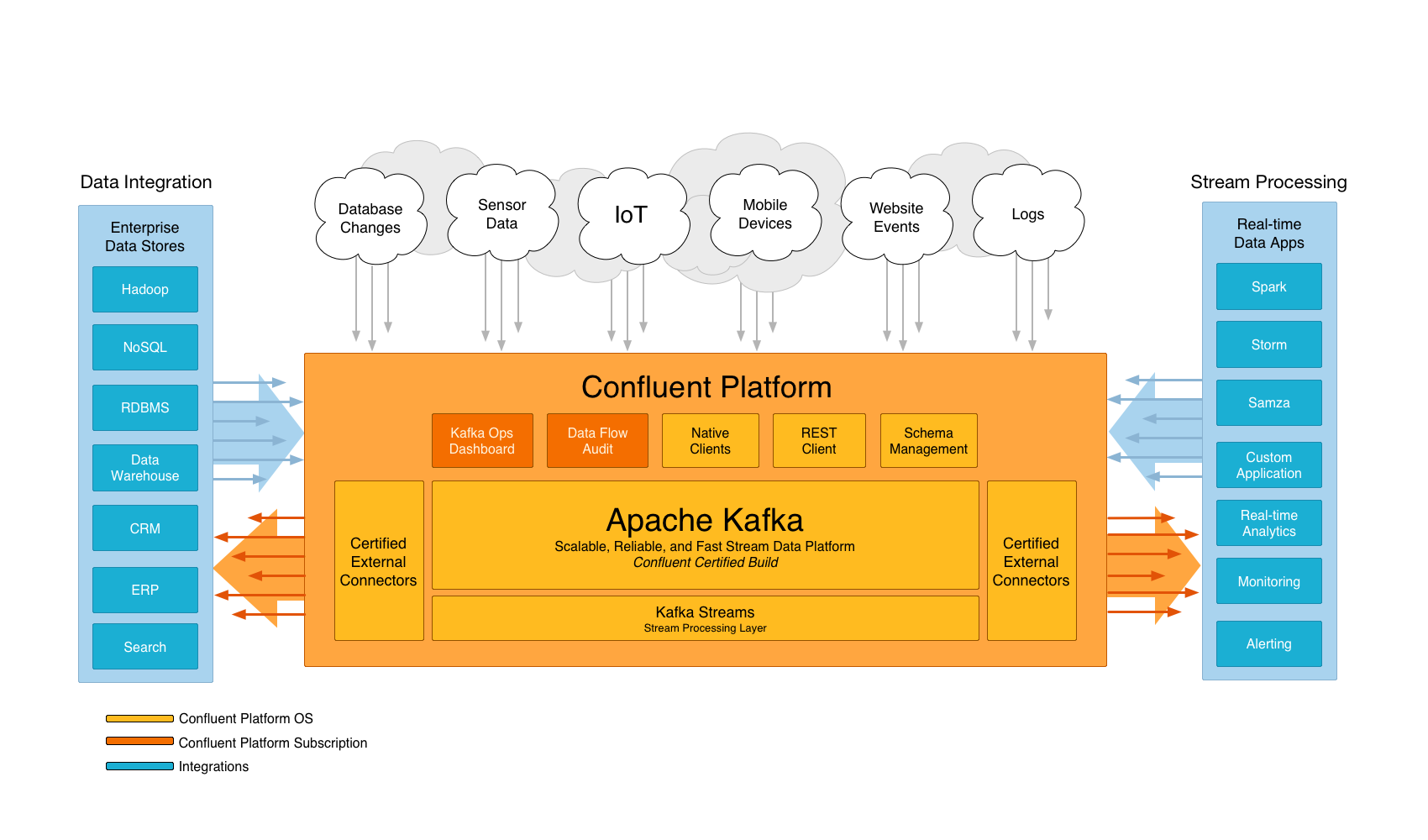
Confluent Platformはコアとして、Apache Kafkaを使用している。Kafkaはリアルタイムで耐障害性を持ち、スケーラブルなメッセージングシステム。
キーとなる特長として、システムにおいて様々な要求に対して応え得る大容量のリアルタイムストリーム処理を可能とすることがある。Hadoopのようなバッチシステムにも対応できるし、低レイテンシを要求するリアルタイムシステムにも対応可能で、ストリーム処理エンジンはデータが到着し次第データを取得して処理することが可能となる。
加えて、Confluent PlatformはSchema Registry、Rest Proxy、CamusというHadoop ClusterにKafkaのデータを容易にアップロード可能なMapReduce実装を有している。
これらのツールの詳細については以後の章で記述する。Confluent Platformはこれらのコンポーネントを統合し、一貫性を持ちながらも柔軟で、様々なユースケースに対応可能なストリームデータ処理基盤を容易に構築することが可能にする。
Apache Kafka
※Kafkaについては当然すぎる内容ですので省略します。
Kafka Connect
Kafka ConnectはKafkaと他システムの間でスケールし、かつ信頼性の高いストリーミングデータを確立するためのツール。Kafka Connectによって大規模データを他システムとの間で出し入れすることがシンプルに定義可能になる。Kafka Connectはデータベース丸ごとや、アプリケーションサーバからのメトリクスを取得してKafka Topicに投入し、低レイテンシのストリーム処理を可能にする。Export Connectを用いることでKafka Topicから取得したデータをElasticsearchでの検索用に投入したり、Hadoopのようなオフラインバッチ解析に用いることもできる。
Kafka Connectはテスト用に1プロセスで走らせることもできるし、分散して実行させ、スケーラビリティと耐障害性を確保することもできる。開発/テスト用や小規模なデプロイに対しては簡易にデプロイが可能なうえ、最終的には組織全体のデータパイプライン化まで拡大させることもできる。
Kafka Connect HDFS Connector
JDBC connectorはRDBからJDBC Driverを用いてデータを取得し、Kafka Topicに投入することができる。
Kafka Connect HDFS Connector
HDFS connectorはKafka Topicから取得したデータをHDFSにエクスポートし、その際に多様なフォーマットやデータの統合をHive QLを用いて行うことができる。
C/C++ library: librdkafka
librdkafkaはKafkaプロトコルに対応したC/C++ライブラリで、Producer、Consumer両方に対応している。
librdkafkaはスケールし、かつ信頼性の高いメッセージ配信を行うために設計されており、Producerとしては80万メッセージ/秒以上、Consumerとしては300万メッセージ/秒以上のスループットを達成できる。
Proactive Support
Proactive SupportはConfluent Platformにおいてメトリクスの収集、レポートを行うためのコンポーネント。 Proactive SupportはConfluent Platformでデフォルトで有効化されている。これによってメトリクス情報がKafkaに保存される。我々の顧客に対してIDと共に有効化することで我々のメトリクスサーバにもデータを転送し、そのデータを基に深い解析とサポートを提供する。
デフォルトのバージョンですとメトリクスをKafkaにため込むだけですが、設定によってデータを収集させるタイプのコンポーネントのようです。
Schema Registry
疎結合なシステム間を接続する上で課題となってくるのが、システムの拡大や進化に合わせて互換性を担保すること。
Kafkaのようなメッセージングサービスを利用する場合、互いに共通のフォーマットを指定しておき、それに従ったメッセージを使用することになる。
だが、多くのシステムにおいてそのフォーマットはアドホックに変わり、コード上に暗黙的に定義され、各システムで個々に重複して定義が必要となってくる。
しかし、要求の変化に応じてこれらのフォーマット定義にも進化が必要となる。
単にアドホックに定義可能とするだけでは、開発者にとってその修正がどれだけの影響を生むかを判断することは非常に難しい。
Schema Registryは、これらのスキーマ管理に対してAvroによって一元管理/定義されたシリアライズ機構を提供することにより、安全、0ダウンタイムな変革をもたらす。
Schema RegistryはKafkaの各Topicに対して使用された全バージョンのスキーマを管理しており、ユーザの定義した互換性設定に応じた変更のみを可能としている。
Schema Registryは開発者に対して必要に応じて安全にスキーマを変更可能な環境を提供することで、様々なシステムに対して予期しない問題を波及させてしまう問題も防止している。
Schema RegistryはKafka Clientに対してスキーマ定義を扱ったり、検索したり、Kafkaに対してAvroFormatでメッセージを送信するためのためのプラグインも有している。
統合がシームレスか? 既にあなたがKafkaをAvroスキーマの元に使用している場合、Schema Registryを使用するために必要になるのはシリアライザの挿入と設定を変えるのみとなる。
REST Proxy
様々な組織は各々固有のツールを持っており、様々な実装言語で作成されているが、全言語に対して優れたKafka Clientが用意されている状況ではない。
現状、2言語しか我々が優れているというレベルまで至ったクライアントをサポートすることは出来ていない。
高性能なKafka Clientを開発すること自体がもともと高汎用性、柔軟なPubSubモデルを前提している関係上、他のシステムのクライアントより困難なものとなっている。
REST ProxyでKafka Clusterと連携可能なRESTful HTTP serviceを提供し、様々な言語から容易にアクセスが可能となる。
REST ProxyはKafkaへのメッセージ送信、メッセージ取得、独自コンシューマグループ/特定コンシューマグループ所属、クラスタメタデータ取得、Topic一覧や設定取得といったKafkaのコア機能を一通り提供する。
REST Proxyによって高性能で常にメンテナンスされたJava Clientを他の言語から利用することが可能となる。
REST ProxyはSchema Registryとも統合されている。Kafkaに対するAvroデータの読み書き、Schema Registryからのスキーマ取得/登録が可能になる。
JSONを登録することでAvroデータにシリアライズし、取得時にAvroデータからデシリアライズされるため、一括したスキーマ管理の恩恵をHTTPとJSONのみで受けることが可能。
Camus
Camusは自動的にかつデータ欠損なくKafkaからデータをHDFSに投入するETLを提供するMapReduceジョブ。Camusを定期的に実行することで、Kafkaに投入されたデータをDWHに使いやすい時間分割されたフォーマットで投入し、オフラインバッチ処理実行準備ができた状態に持っていくことができる。
CamusもSchema Registryと統合されている。統合された機能によって、CamusはHDFSにデータ格納前にデータをデコードし、異なるスキーマを用いたデータが混じっていた場合でも、各時間分割パーティション間で一貫性のあるフォーマットで統一して出力することが可能になる。データ生成からDWHへのデータ投入までの各ステップのSchema Registryとの統合機能により、高価で労働集約的な前処理から解放され、有用な状態にデータを保つことができる。
既存のKafkaクラスタからのマイグレーション
ConfluentはOSSのApache Kafkaプロジェクトにコミットしている。
Confluent PlatformのあるバージョンにおけるKafkaはOSSバージョンのKafkaに常時互換性を保っており、リリース時期が明確になっていないクリティカルなバグに対するパッチのみを適用した状態になっている。
そのため、既に存在しているクラスタはKafka Brokerのローリングリスタートにより容易にConfluent Platformバージョン化が可能。
残りのConfluent Platformのコンポーネントはインクリメンタルに追加可能。Schema Registryの追加とアプリケーションへのAvroシリアライザの追加から始まり、次にKafka/Avroのライブラリが使えないケースでもアクセス可能とするREST Proxy、最後にComusジョブを追加することでKafkaのデータを常時HDFSにロードすることが可能となる。
まとめ
Kafkaをある組織の中で共通のETL基盤として使う際に足りないと感じられるコンポーネントを順次補ったような構成に見えます。
実際、Kafka自体はメッセージバス(最近認証は入りましたが)でしかないため、それを公開するといろいろ問題が発生するというのは納得がいく説明ではありますね。
とりあえず概要はつかめたので、次は各コンポーネントでの特徴的な記述を抽出してまとめてみます。