{rtan}を使った2群の平均値の差の検定。
ASAの声明を受けて。
方々で書かれているので何番煎じなんだ、という話ですが。
http://www.slideshare.net/simizu706/stan-62042940
http://tjo.hatenablog.com/entry/2016/03/10/190000
サンプル数の異なる2群でやりたかったので。
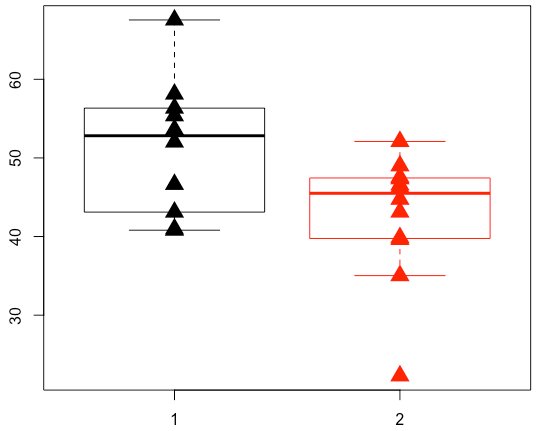
サンプルデータの準備
まぁこんな感じで。
サンプル数は各群 M, Nとします。
set.seed(1)
M <- 10
N <- 12
X1 <- rnorm(M, 50, 11)
X2 <- rnorm(N, 40, 8)
boxplot(X1, X2, border=c(1,2))
points(rep(1, M), X1, pch=17, cex=2)
points(rep(2, N), X2, col="Red", pch=17, cex=2)
t-test
t-testは、こんな感じ。
t.test(X1, X2, var.equal = F)
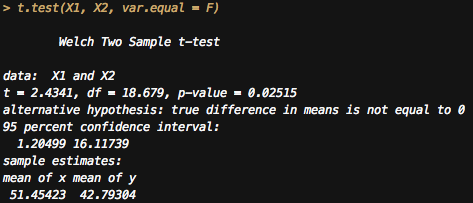
という事で、$p < 0.05$ なので「有意差あり」。
厳密には、「帰無仮説を採用した際に、現在のデータとそれより甚だしいデータを説明できる確率が5%より小さい」。
{rstan}でやると。
要するに、
\begin{eqnarray*}
X1 &\sim& m_1 + Normal(0, s_1)\\
X2 &\sim& m_1 + m_2 + Normal(0, s_2)
\end{eqnarray*}
この$m_2$がゼロで無ければ「差がある」。
stanのコードは、上の式をそのまんまペタペタと書きます。
data{
int<lower=0> M;
int<lower=0> N;
real x1[M];
real x2[N];
}
parameters{
real<lower=0> s1;
real<lower=0> s2;
real m1;
real m2;
}
model{
for(i in 1:M)
x1[i] ~ normal(m1, s1);
for(i in 1:N)
x2[i] ~ normal(m1+m2, s2);
}
これを
code1 <- "hoge"
とかにしておきます。
で、
library("rstan")
dat <- list(M=M, N=N, x1=X1, x2=X2)
fit <- stan(model_code=code1, data=dat, iter=1000, chain=4)
並列化したければ前の記事を参照のこと。
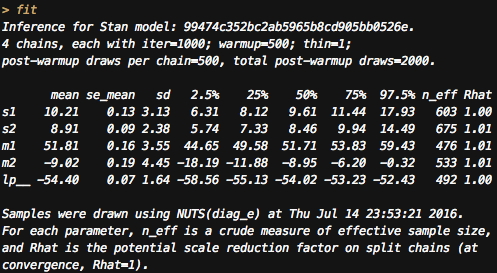
Rhat>1.2とか、n_effがiterより極端に低いとかになったら、収束してません。
ま、めちゃめちゃ単純なモデルなので大丈夫でしょう。
結果の図示
m2の事後分布が0でない事を一目で分かるような図を書きたい。
どうとでもなるんですが、最近はこんな感じにしています。
library("ggplot2")
m2 <- extract(fit)$m2
dat_gg <- data.frame(X=density(m2)$x, Y=density(m2)$y)
q <- quantile(m2, prob=c(0.025, 0.975))
ggplot()+
geom_line(data=dat_gg, aes(x=X, y=Y))+
geom_ribbon(data=subset(dat_gg, X >= q[1] & X <= q[2]),
aes(x=X, ymin=0, ymax=Y))
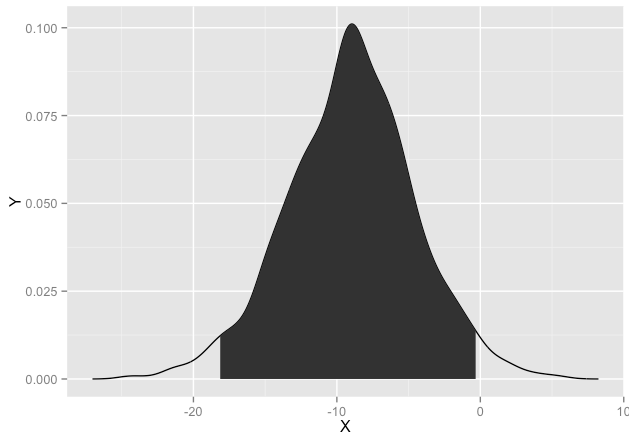
m2の事後分布の95percentileが黒塗部分ですので、
一目瞭然で、まぁ、0ではない、と。
どっとはらい