Infinibadを触る機会があったので分散版tensorflowのcifar10を使って早さなどを比較してみました。
InfinibandはIPoIBで通信しています。
検証環境
サーバー
CPU: E5-2623 * 2
GPU: TITAN X(Maxwell) * 4
RAM: 128G
NIC: 1Gbps, 10Gbps, InfiniBnad(FDR 56Gbps)
計:5台
tensorflow version
tensorflow=0.12
比較プログラム
- 分散版cifar10(後述)
- サーバー1台, 4GPU, パラメータサーバー2台
- サーバー5台, 20GPU, パラメータサーバー10台
本当は学習サーバーとパラメータサーバーを分けた方が良いのですが別途用意できなかったので各サーバーに相乗りで2個ずつ立てています。
分散版はtensorflow付属のcifar10のtrain()部分をSyncReplicasOptimizer + Adamに置き換えた物を使います.
images, labels = cifar10.distorted_inputs()
logits = cifar10.inference(images)
loss = cifar10.loss(logits, labels)
opt = tf.train.AdamOptimizer()
syc_opt = tf.train.SyncReplicasOptimizer(opt, ....)
train_op = syc_opt.minimize(total_loss, global_step)
バッチサイズとかそのほかのパラメータは全部そのままです。
ついでにtensorflow付属のcifar10の比較もしておきます。
-
tensorflow付属のcifar10_train.py
- サーバー1台, 1GPU
-
tensorflow付属のcifar10_multi_gpu_train.py
- サーバー1台, 1GPU
- サーバー1台, 4GPU
各GPUのイテレーションが 100000 になるまで回します。
比較はlossの下がり具合を見ます。
結果
グラフの見方
左図: 重みを共有しているとあるGPU1台で計算した イテレーションあたりのlossの変化
右図: 重みを共有しているとあるGPU1台で計算した 時間あたりのlossの変化(イテレーション100000で終了)
サーバー1台1GPU
- tensorflow付属のcifar10_train.py
- サーバー1台, 1GPU
- tensorflow付属のcifar10_multi_gpu_train.py
- サーバー1台, 1GPU
の比較
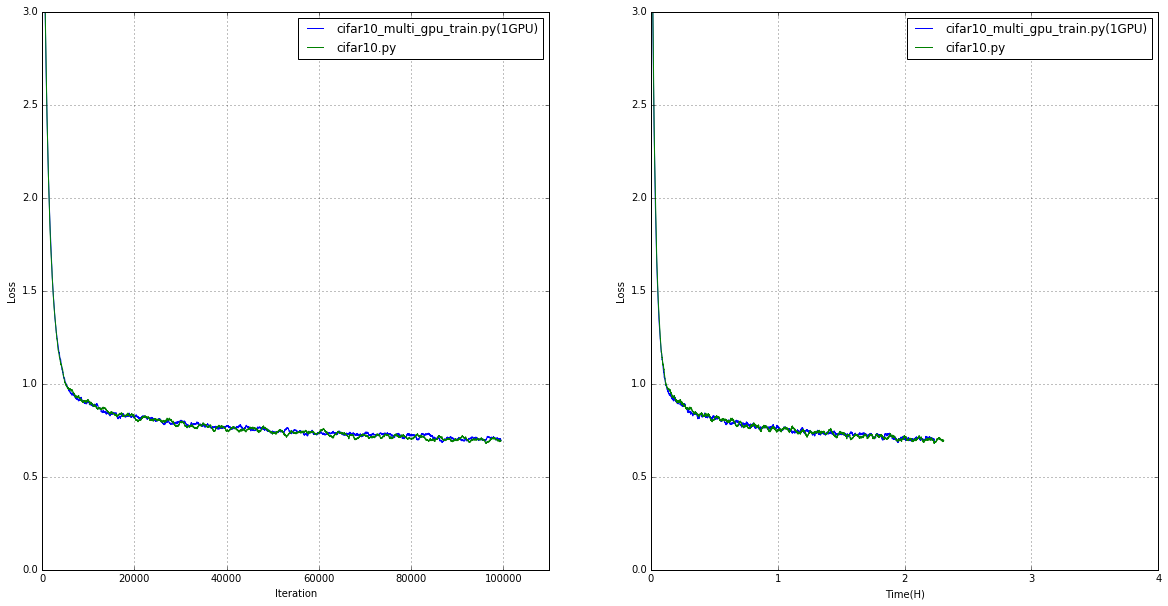
1台の場合は予想通り?一緒でした。
サーバー1台4GPU
-
tensorflow付属のcifar10_multi_gpu_train.py
- サーバー1台, 4GPU
-
分散版cifar10
- サーバー1台, 4GPU, パラメータサーバー2台
の比較
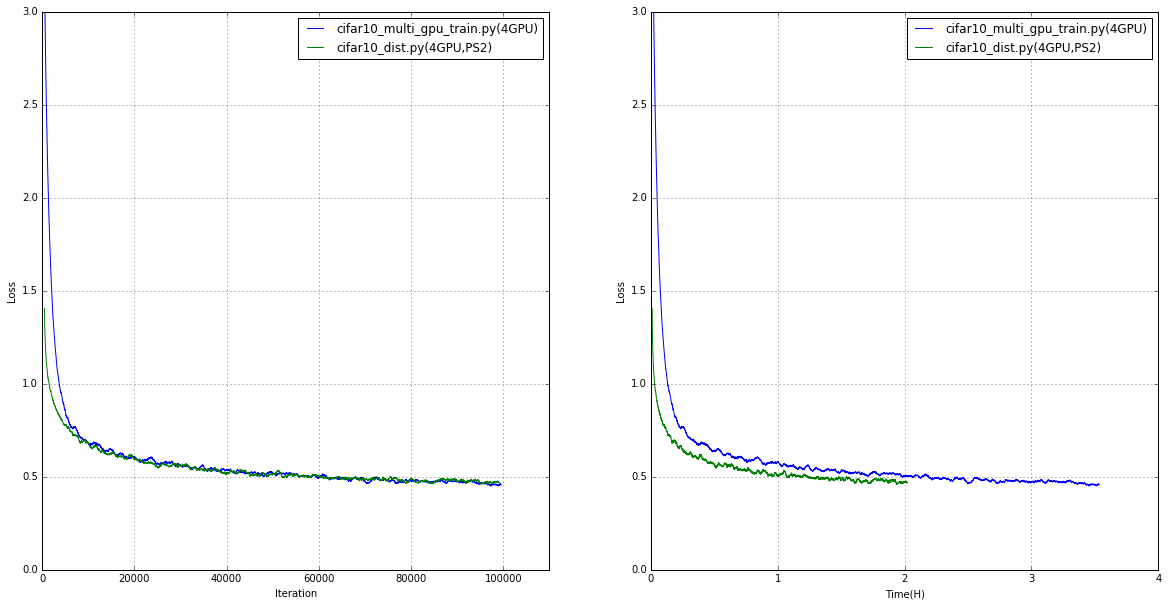
イテレーションあたりのlossの変化はだいたい同じぐらいでしたが時間あたりの変化に差がでています。
重み更新時 lossが4つ計算おわるまで待ってから更新(cifar10_multi_gpu_train.py)とlossが4つたまれば更新(SyncReplicasOptimizer)の差が出た感じでしょうか。
5台20GPU
タイトルの
- 分散版cifar10
- サーバー5台, 20GPU, パラメータサーバー10台, 1G NIC
- サーバー5台, 20GPU, パラメータサーバー10台, 10G NIC
- サーバー5台, 20GPU, パラメータサーバー10台, InfiniBand
の比較。
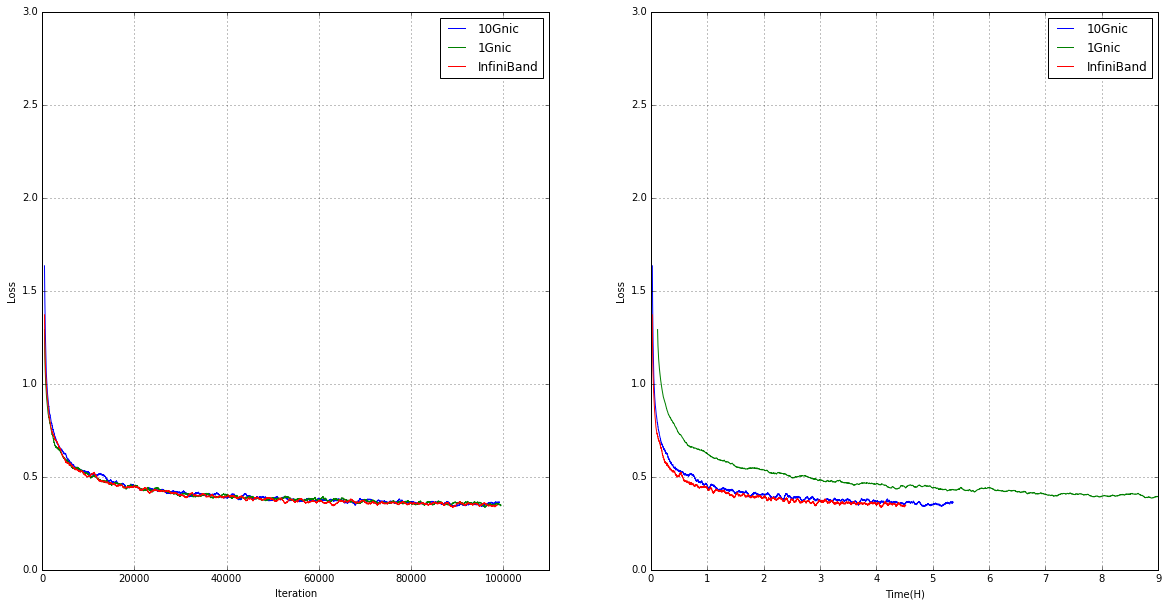
こちらもイテレーションあたりの変化はほぼ同じになり時間あたりの変化に差が出ています。
もっともパラメータサーバーへの通信が集中したサーバーでは常時2.5Gbpsの通信が発生しました(10G,infiniband)。
1GのNICの場合は最大速度は1Gbpsに制限されているのにでは同期に時間がかかり100000イテレーションに到達するまでに23時間とinfinibadの5倍以上時間がかかりました。
通信が10Gbpsを超えないようであればinfinibadの低レイテンシの分10Gnicより有利なようです。
このちょっとした差でinfinibad使うかどうかは実験の規模によりそうですね。
全部の結果
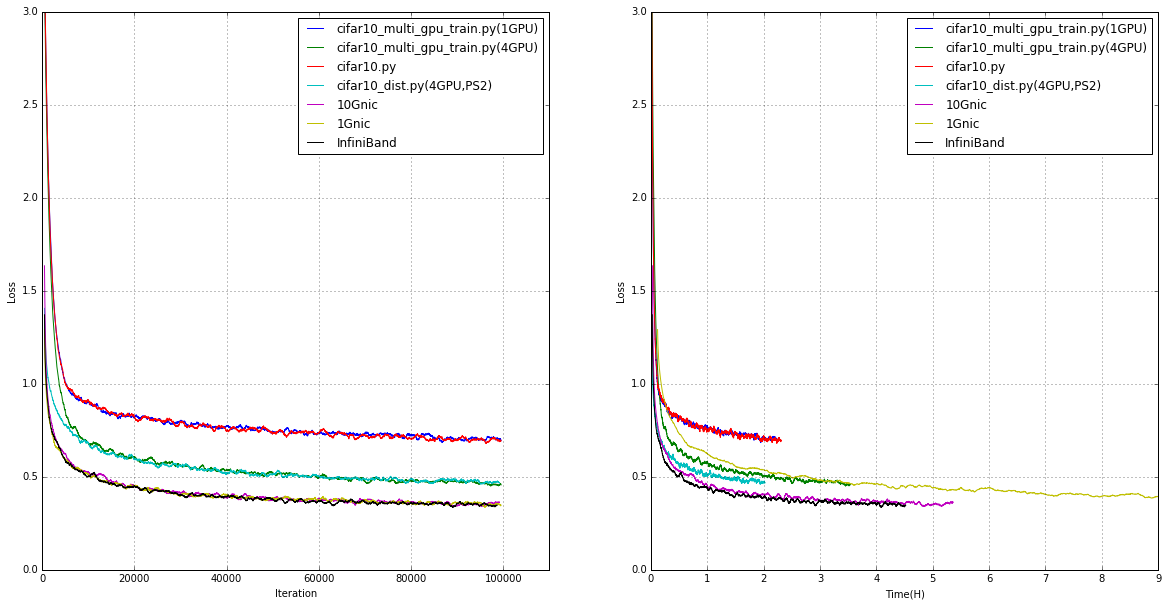
1Gnicではすぐにボトルネックになりそうな感じです。
10Gnicか効率の良い分散学習方法が必要になりそうです。
RDMA使った分散学習もそのうち試してみたいです。