もう3週間前くらいですが、Pull型という珍しいアーキテクチャの監視ツールであるPrometheus1.0がリリースされました。最近は日本でもPrometheus Casual Talkが開催されるなど導入事例も増えてきたようなので、今後の導入を視野に入れて触ってみました。
特徴
自分が見た範囲で気になった特徴としては、以下のようなものがありました。
- Go製
- アラート機能が無償で利用可能(例えばELKスタック使う場合、Watcherがありますが、利用には有償契約が必要)
- 扱えるのは数値のみ(ログ等で文字列を扱う場合は別のツール等が必要)
- Pull型
監視ツールはPush型(監視対象側が監視ツールに情報を送る)のものが多いと思いますが、PrometheusはPull型(Prometheusが監視対象の情報を取得する)です。理由はここに書いてありますが、ラップトップ等で気軽に監視ツールを実行できること、ターゲットが落ちている場合の判断が楽なこと(Push型だとターゲットがエラーで落ちたのかメンテで落ちたのかの判断が監視ツールにはできない)、ターゲットの状態をブラウザ等から確認できる、といった点が上げられています。ただし、PrometheusにもPushgatewayという機能があり、Pushすることも可能です。(バッチ処理の結果送信等限られた用途でのみ使うことが推奨されています)
使ってみる
一通り機能を確認していきたいと思います。
前回の記事でdocker1.12で追加されたswarmモードを使ってみたので、今回もswarmモードで構築しましたが、あんまり相応しい例ではなかったと思います。(Prometheus自体とは関係ないので理由は最後に記載)
swarm使ってやる場合はdocker-machinとdockerがインストールされてさえいれば、上記の記事を読まなくても構築できるように書いていますが、それぞれのコマンドがどのような意味か知りたい場合は上記の前回の記事を参照してください。
swarmを使わない場合は適宜docker runとかに読み替えて貰えればと思います。
インフラはDigitalOceanを使います。こちらから登録して頂けるとお互いハッピーなので(ry
Prometheusの構築と自身の監視
まずはswarmのmanagerを作成します。
# manager用のホストを作成
$ docker-machine create -d digitalocean --digitalocean-image "ubuntu-16-04-x64" --digitalocean-region "sfo1" --digitalocean-size "512mb" --digitalocean-access-token ${DIGITALOCEAN_API_TOKEN} manager
(結果略)
# managerのIPをメモる
$ docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
manager * digitalocean Running tcp://104.131.149.142:2376 v1.12.0
# swarmモードを初期化
$ eval $(docker-machine env manager)
$ docker swarm init --advertise-addr 104.131.149.142
# 以下のような出力が得られるのでworkerを追加するコマンド(1個目)を控えておく
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-12wn17zowr4ysj089mb4s0zijbwexx6w3oucz77k87uwkmxlsu-e9lv6z80x48hx42mxz50t0l6g \
104.131.149.142:2377
To add a manager to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-12wn17zowr4ysj089mb4s0zijbwexx6w3oucz77k87uwkmxlsu-en1rtjwtlujupv16qqjja9xda \
104.131.149.142:2377
続いてPrometheus用のDockerホストを作ります。
# Prometheus用のホストを作成
docker-machine create -d digitalocean --digitalocean-image "ubuntu-16-04-x64" --digitalocean-region "sfo1" --digitalocean-size "2gb" --digitalocean-access-token ${DIGITALOCEAN_API_TOKEN} prometheus
(結果略)
# prometheusノードをswarmクラスタに追加
$ eval $(docker-machine env prometheus)
$ docker swarm join \
--token SWMTKN-1-12wn17zowr4ysj089mb4s0zijbwexx6w3oucz77k87uwkmxlsu-e9lv6z80x48hx42mxz50t0l6g \
104.131.149.142:2377
以下のような自身を監視する最小限のconfigを作ります。
mkdir prometheus
vi prometheus/prometheus.yml
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
何を設定しているかはラベルから分かると思いますが、詳細は公式ページを見て頂ければと思います。
一旦、Prometheusを起動します。
# 設定ファイルディレクトリをDockerホストにコピー
docker-machine scp -r prometheus prometheus:/opt/
# managerでdockerコマンドを実行するように指定
eval $(docker-machine env manager)
# prometheusサービスをprometheusホストでのみ起動するよう作成
docker service create \
--replicas 1 \
--name prometheus \
--publish 9090:9090 \
--mount type=volume,source=/opt/prometheus,target=/etc/prometheus \
--constraint node.hostname==prometheus \
prom/prometheus
これでhttp://<prometheus_ip>:9090/metricsにアクセスすると以下のようなメトリクスの一覧が出てきます。
PrometheusのIPはdocker-machine lsなどで調べてください。
http://<prometheus_ip>:9090/graphからGraphタブまたはConsoleタブを選ぶとそれぞれグラフとコンソールが表示されます。
まずはコンソールタブを選択して、/metricsででてきた一覧から適当にメトリクス名を入力して実行してみます。メトリクスの種類やクエリの書き方等は後述しますが、今回は試しにgo_goroutinesというメトリクスを使ってみました。

続いてグラフタブを開くとこのようになります。
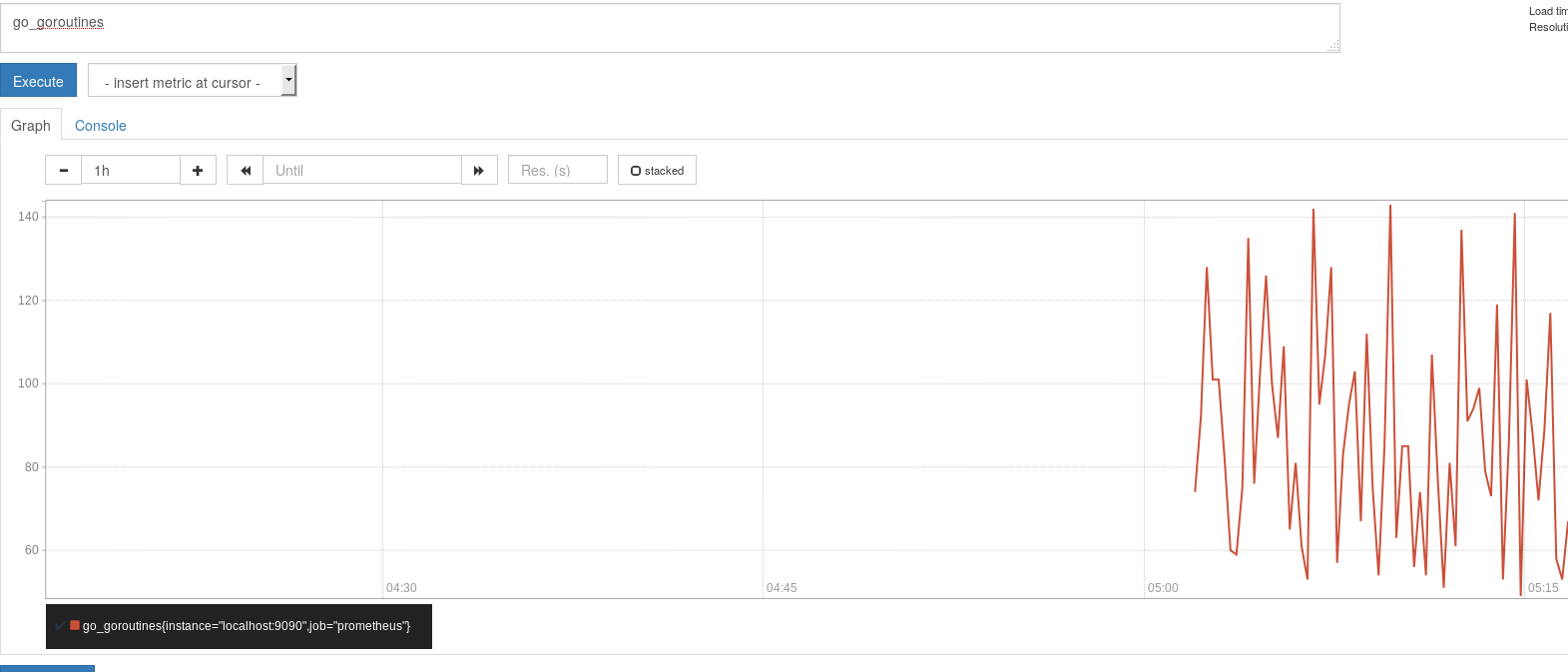
時間軸等は変更できます。
別の監視対象を追加
ここまでだとprometheus自体のメトリクスしか取れていないので、別の監視対象を追加してみたいと思います。
exporter
OS自体のメトリクスや既存のソフトウェアのメトリクスを取得したい場合はexporterを使います。MySQLやHAProxy等有名どころのexporterは公式またはサードパーティのものが利用できます。なお、kubernetesやetcd等はPrometheus向けのメトリクスをデフォルトでexposeしているのでexporter不要でメトリクスを取得できます。
今回は例としてシステムのメトリクスを取得するnode exporterを使ってみます。
# hostネットワークを使うため、swarmではなく通常のdockerコマンドで実行
# manager上で実行
eval $(docker-machine env manager)
docker run -d -p 9100:9100 --net="host" prom/node-exporter
# prometheusノードでも実行
eval $(docker-machine env prometheus)
docker run -d -p 9100:9100 --net="host" prom/node-exporter
http://<対象ノードのIP>:9100/metricsにアクセスすると先ほどと同様の様々なメトリクスおよびnode exporeterのメトリクスが確認できます。
Prometheusから監視できるようにconfigファイルを以下のように書き換えます。
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
scrape_interval: 5s
static_configs:
- targets: ['manager_host_ip:9100']
labels:
group: 'manager'
- targets: ['prometheus_ip:9100']
labels:
group: 'worker'
configファイル変更時はPrometheusのプロセスにSIGHUPを送るか以下のようなリクエストを送るとリロードできます。ちなみにPOSTですが、configファイル自体を渡すことはできません。(仕様)
# configファイルをホストに送信
docker-machine scp -r prometheus prometheus:/opt/
# curlでリロード
curl -X POST http://prometheus_ip:9090/-/reload
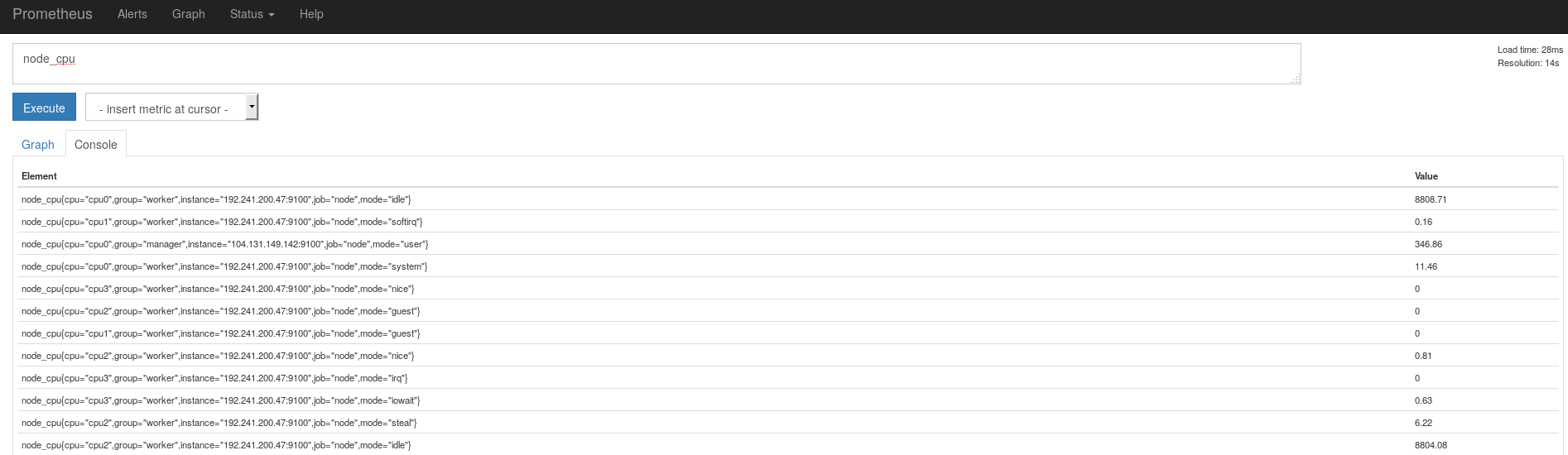
監視対象に追加されているはずなので、http://<prometheus_ip>:9090/graphのConsoleタブから試しにnode_cpuという名前のメトリクスを確認してみます。
クエリの書き方
ここでクエリの書き方を簡単に紹介してみます。
node_cpuを実行した上記のキャプチャにある通り、Elementカラムに様々なラベル付きでnode_cpuの値が表示されているのが分かるかと思います(たとえば、node_cpu{cpu="cpu0",group="worker",instance="192.241.200.47:9100",job="node",mode="idle"})。
この形式はそのままクエリに使えて、例えば
node_cpu{cpu="cpu0",group="manager",mode="user"}を実行すると該当のデータのみ取得できます。

ちなみにjobとgroupというラベルは上記のymlファイルで指定したものです。
クエリの書き方の網羅的な説明は公式ページに載っていますが、例えば以下のように正規表現を使ったり、
node_cpu{cpu=~"cpu.+",group="worker",mode=~"user|system"}
以下のように直近5分のデータを表示したり
node_cpu{cpu=~"cpu.+",group="worker",mode=~"user|system"}[5m]
直近5分の平均を表示したり
rate(node_cpu{cpu=~"cpu.+",group="worker",mode=~"user|system"}[5m])
userとsystemの合計を表示したり
sum(rate(node_cpu{cpu="cpu0",group="worker",mode=~"user|system"}[5m]))
色々できます。
そのままグラフタブを開けば該当するデータのグラフが表示されます。
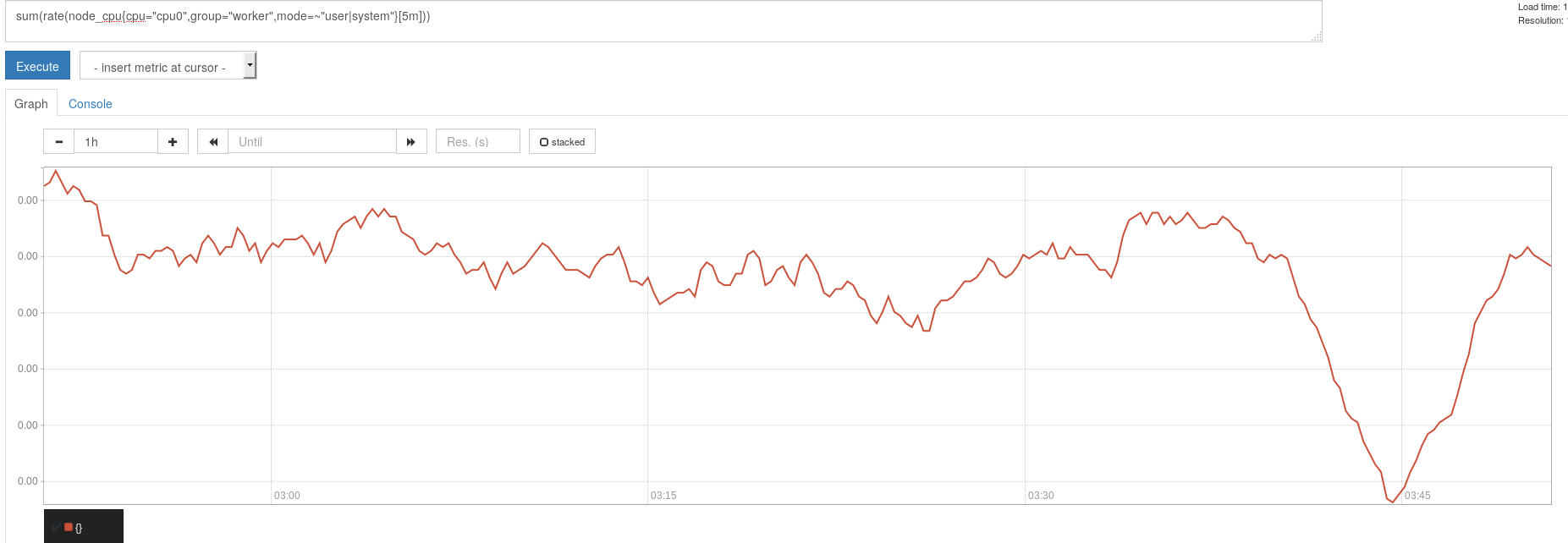
もちろんexporterは自作もできます。
https://prometheus.io/docs/instrumenting/writing_exporters/
クライアントを書く
アプリやツール等からメトリクスを取得させたい場合はexporterを書くまでもなくクライアントライブラリを使ってメトリクスを公開することができます。
https://prometheus.io/docs/instrumenting/clientlibs/
Go以外の言語でも書くことができます。
今回はお試しということで以下のような意味のないCounterのサンプルを作りました。Counterの他にもGauge,Summary,Histogramというタイプのメトリクスがあります。
ちなみにここにpublishしてあるので以下のプログラムとDockerfileは作らなくてOKです。
package main
import (
"math/rand"
"net/http"
"time"
"github.com/prometheus/client_golang/prometheus"
)
func main() {
pushCounter := prometheus.NewCounter(prometheus.CounterOpts{
Name: "sample_counter",
Help: "just a simple counter",
})
prometheus.MustRegister(pushCounter)
go func() {
for {
pushCounter.Inc()
time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond)
}
}()
http.Handle("/metrics", prometheus.Handler())
http.ListenAndServe(":9111", nil)
}
alpineで動かすのでこんな感じでビルドします。
CGO_ENABLED=0 go build
こんな感じのDokcerfileを作ります。
FROM alpine:latest
ADD prometheus /
CMD /prometheus
このタスクを実行するサービスを作ります。
docker service create \
--replicas 1 \
--name sample-client \
--publish 9111:9111 \
daikikohara/prometheus-client:v1
swarmノードの任意のIP:9111/metricsにアクセスするとデフォルトのメトリクスに加えて追加したsample_counterというメトリクスが表示されています。

Prometheusの監視対象に追加するには以下のようなセクションを追加し、
- job_name: 'sample'
scrape_interval: 5s
static_configs:
- targets: ['sample-clientが動いているノードのIP:9111']
リロードします。
docker-machine scp -r prometheus prometheus:/opt/
curl -X POST http://prometheus_ip:9090/-/reload
WebUIからグラフも表示できます。
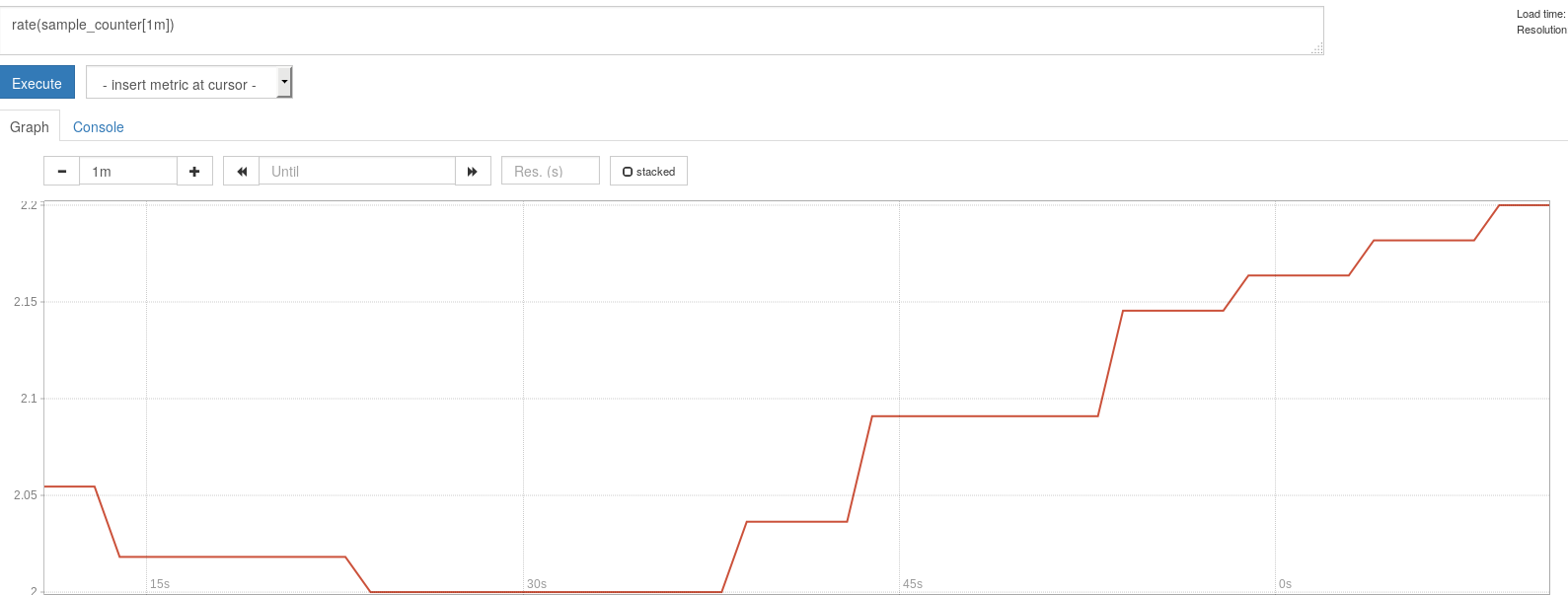
Recording rule
Recording ruleを使うとよく使うクエリの結果等を別のメトリクスとして取得できるようになります。これは元のクエリを都度実行するより効率的で、特にダッシュボード等で頻繁に実行されるケースでは有利みたいです。
お試しということで、ローカルのprometheus/prometheus.rulesファイルを以下のような内容で作成します。
sample_rule:node_cpu_user:avg_rate5m = avg(rate(node_cpu{mode="user"}[5m])) by (instance, cpu)
ルールの書き方が正しいかは以下のツールでチェックできます。
$ go get github.com/prometheus/prometheus/cmd/promtool
$ promtool check-rules ./prometheus.rules
Checking ./prometheus.rules
SUCCESS: 1 rules found
prometheus.ymlを以下のように書き換えます。追加したのはevaluation_intervalとrule_filesです。ルールの評価を15秒ごとに行うというものです。
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
monitor: 'codelab-monitor'
rule_files:
- 'prometheus.rules'
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
scrape_interval: 5s
static_configs:
- targets: ['manager_ip:9100']
labels:
group: 'manager'
- targets: ['prometheus_ip:9100']
labels:
group: 'worker'
- job_name: 'sample'
scrape_interval: 5s
scrape_timeout: 3s
static_configs:
- targets: ['prometheus_ip:9111']
ルールとconfigファイルをPrometheusのホストに送ってリロードします。
docker-machine scp -r prometheus prometheus:/opt/
curl -X POST http://prometheus_ip:9090/-/reload
設定したルール名でグラフが取得できるようになっています。
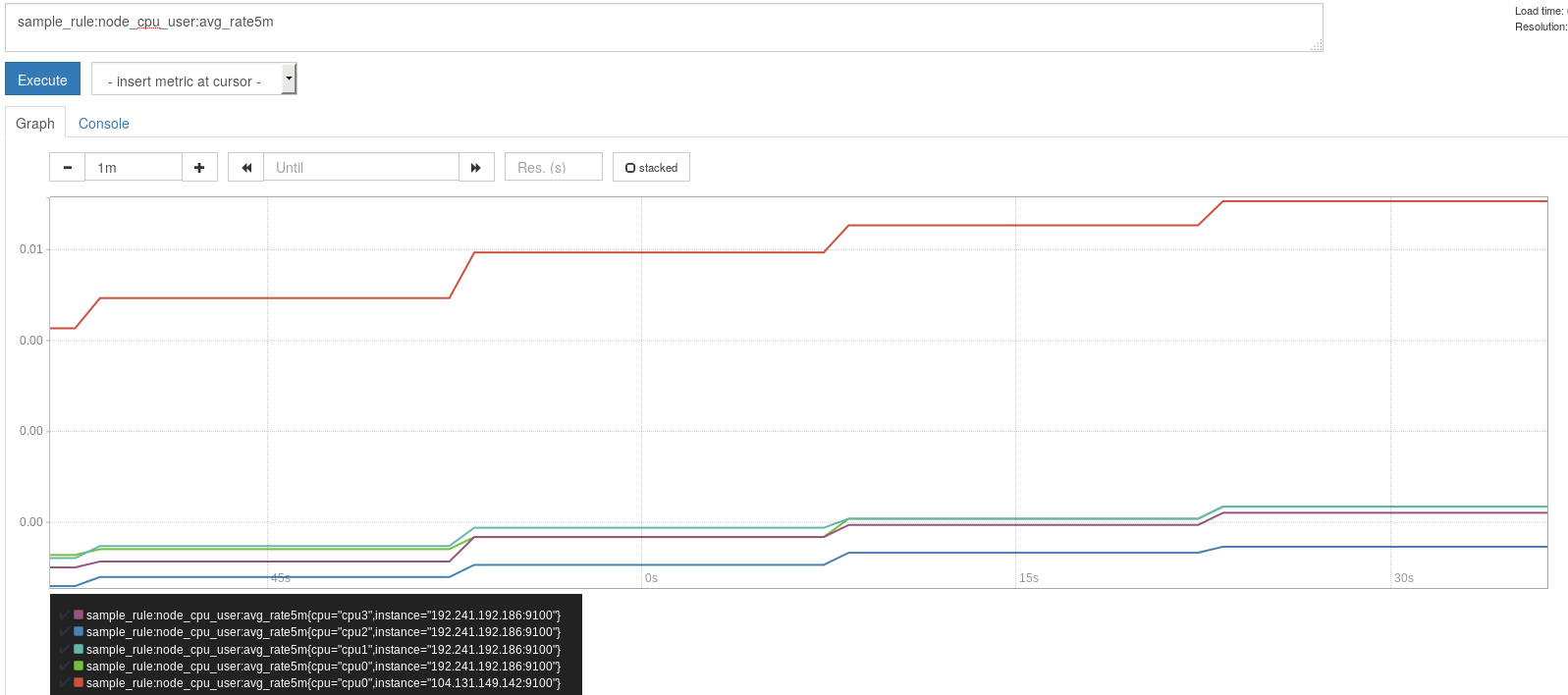
Alertmanager
Alertmanagerを使うと様々な条件でアラートの送信ができるようになります。
AlertmanagerはPrometheusとは別のプロセスで、Prometheus上でruleを設定してAlertmanagerにアラートを送信、Alertmanagerが送られてきたアラートを条件に従って様々な通知先に送信する等のハンドリングを行うという挙動になっています。
送信先はemailやSlack等様々なものに対応しています。
ルールも様々なものが設定できます。
公式ページで触れられているものだとGrouping(例えばDBが落ちたら発生するエラー等は1つのインスタンスから受信できれば良いので、同じ種類のアラートはまとめる)、Inhibition(あるグループのアラートが既に発生していたら別のアラートは発生させない)、Silence(特定のアラートを一定時間発生させない)といったタイプのルールがあります。
とりあえず今回は公式ページの例にあるインスタンスがダウンした場合のアラートを試しみてます。送信先はSlackで試してみました。
まずはalertmanager用のディレクトリをローカルに作って、設定ファイルを作成します。
mkdir alertmanager
vi alertmanager/config.yml
global:
route:
receiver: main
group_by: ['alertname', 'instance']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receivers:
- name: 'main'
slack_configs:
- api_url: 'https://hooks.slack.com/services/your_api_token'
channel: '#channel_name'
次にAlertmanagerを起動します。
# alertmaanger用のホストを作成
docker-machine create -d digitalocean --digitalocean-image "ubuntu-16-04-x64" --digitalocean-region "sfo1" --digitalocean-size "2gb" --digitalocean-access-token ${DIGITALOCEAN_API_TOKEN} alertmanager
# swarmクラスタに追加
eval $(docker-machine env alertmanager)
docker swarm join \
--token SWMTKN-1-12wn17zowr4ysj089mb4s0zijbwexx6w3oucz77k87uwkmxlsu-e9lv6z80x48hx42mxz50t0l6g \
104.131.149.142:2377
# 設定ファイルをalertmanagerのホストに送信
docker-machine scp -r alertmanager alertmanager:/opt/
# Alertmanager用のサービスの作成
eval $(docker-machine env manager)
docker service create \
--replicas 1 \
--name alertmanager \
--publish 9093:9093 \
--mount type=volume,source=/opt/alertmanager,target=/etc/alertmanager \
--constraint node.hostname==alertmanager \
prom/alertmanager:latest
AlertmanagerノードのIP:9093にブラウザからアクセスして以下のような画面が出来きたらOKです。
続いてPrometheus側にアラートルールを追加します。prometheusディレクトリに以下のようなファイルを作成します。
ALERT InstanceDown
IF up == 0
FOR 1m
LABELS { severity = "page" }
ANNOTATIONS {
summary = "Instance {{ $labels.instance }} down",
description = "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.",
}
上記のファイルをprometheus.ymlから参照します。
rule_files:
- 'prometheus.rules'
- 'alert.rules'
Prometheusのコンテナ側も設定を変更する必要がありますが、公式のDocker imageではAlertmanagerに接続できないので、以下のようなDockerfileを作成してこちらに置きました。
FROM prom/prometheus
ENTRYPOINT [ "sh" ]
CMD [ "-c", \
"/bin/prometheus \
-config.file=/etc/prometheus/prometheus.yml \
-storage.local.path=/prometheus \
-alertmanager.url=${ALERTMANAGER}" ]
一度元のprometheusサービスを落としてから上記のイメージを使ったprometheusサービスを実行します。
# サービスを削除
$ docker service rm prometheus
# 設定ファイルをホストに送信
$ docker-machine scp -r prometheus prometheus:/opt/
# サービスを再作成
$ docker service create \
--replicas 1 \
--name prometheus \
--publish 9090:9090 \
--mount type=volume,source=/opt/prometheus,target=/etc/prometheus \
--env ALERTMANAGER="http://alertmanager_ip:9093" \
--constraint node.hostname==prometheus \
daikikohara/prometheus:v1
おもむろに監視対象のコンテナを一つ落としてみます。
# manager上のdockerプロセスを確認
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
57aa0d720403 prom/node-exporter "/bin/node_exporter" 2 hours ago Up 2 hours suspicious_keller
9687d44ae859 daikikohara/prometheus-client:v1 "/bin/sh -c /promethe" 7 hours ago Up 7 hours sample-client.1.2zkn3wtvw37f8fiy6xqfhui4n
# node_exporterのプロセスを停止
$ docker stop suspicious_keller
suspicious_keller
ここでAlertタブから確認するとPENDINGになっています。
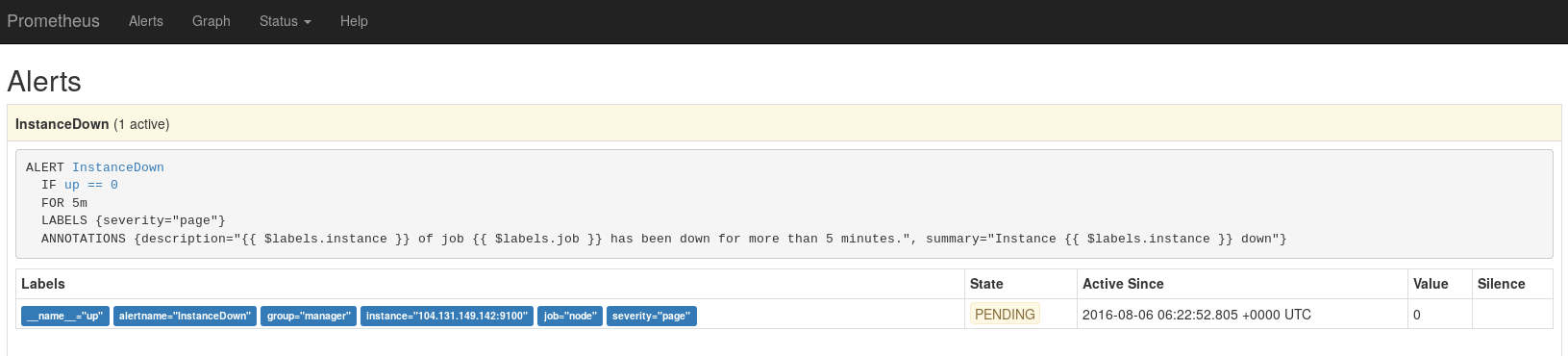
1分以上経過してから再確認するとStateがFIRINGに変わりました。
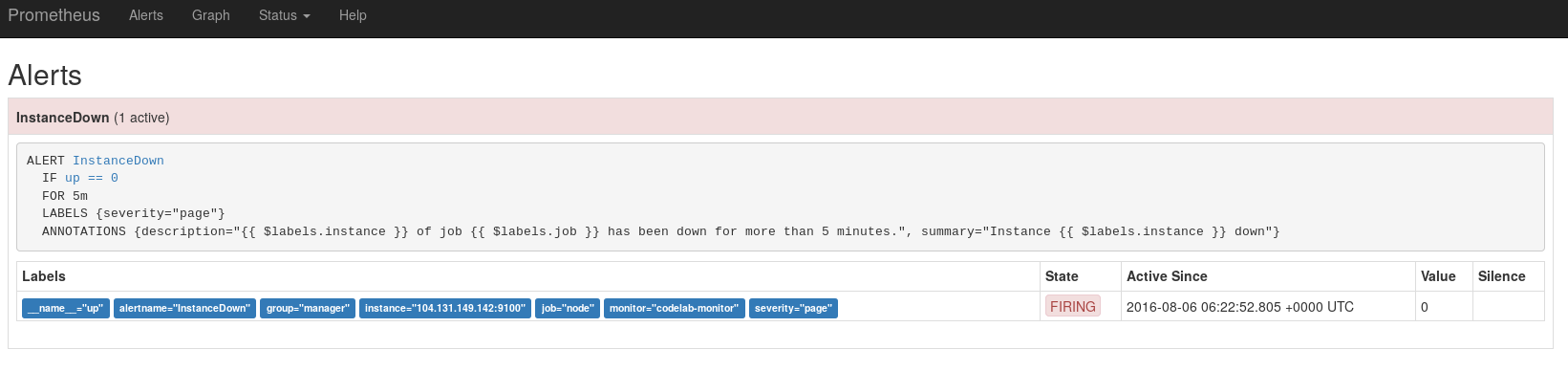
Alertmanagerにも通知されています。
(キャプチャ撮り忘れ)
Alertmanager経由でSlackにも通知されています。

Grafana連携
これまで見てきた通りPrometheus自身にもグラフの機能がありますが、あまりパワフルではないため、Grafanaと連携することを公式でも推奨しています。Grafanaは様々なメトリクスを可視化するツールで、Prometheus以外にもInfluxDBやCloudWatch等様々なデータソースに対応しています。
まずはGrafana用のマシンとサービスを作成します。
# Grafana用のホストを作成
$ docker-machine create -d digitalocean --digitalocean-image "ubuntu-16-04-x64" --digitalocean-region "sfo1" --digitalocean-size "2gb" --digitalocean-access-token ${DIGITALOCEAN_API_TOKEN} grafana
# grafanaノードをswarmクラスタに追加
$ eval $(docker-machine env grafana)
$ docker swarm join \
--token SWMTKN-1-12wn17zowr4ysj089mb4s0zijbwexx6w3oucz77k87uwkmxlsu-e9lv6z80x48hx42mxz50t0l6g \
104.131.149.142:2377
# Grafana用のサービスを作成
$ docker service create \
--replicas 1 \
--name grafana \
--publish 3000:3000 \
--constraint node.hostname==grafana \
grafana/grafana
GrafanaのノードのIP:3000にアクセスしたらログイン画面が出てきます。

今回はデフォルトなのでadmin/adminでログインします。
Prometheusのデータソースを追加するには、
- logoクリック
- Data Sourcesクリック
- Add data sourceをクリック
- Nameに適当な名前を入力
- Defaultにチェック(オプショナル)
- Type をPrometheusに変更
- UrlをPrometheusのURLに変更
- AccessをDirectに変更
- Addをクリック
で追加できます。
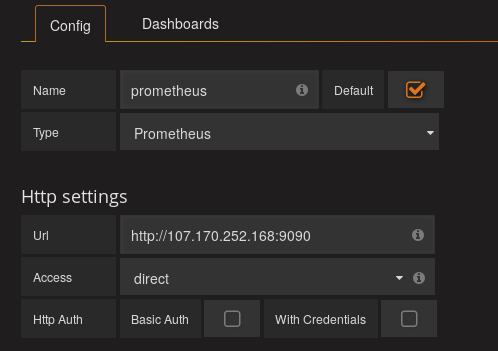
次にグラフを作成するには、
- 左上のlogoクリック
- DashboardsからNewを選択
- 左端のメニューからAdd Panel、Graphを選択
- Queryに適当にグラフにしたいクエリを入力
とすることで作成できます。
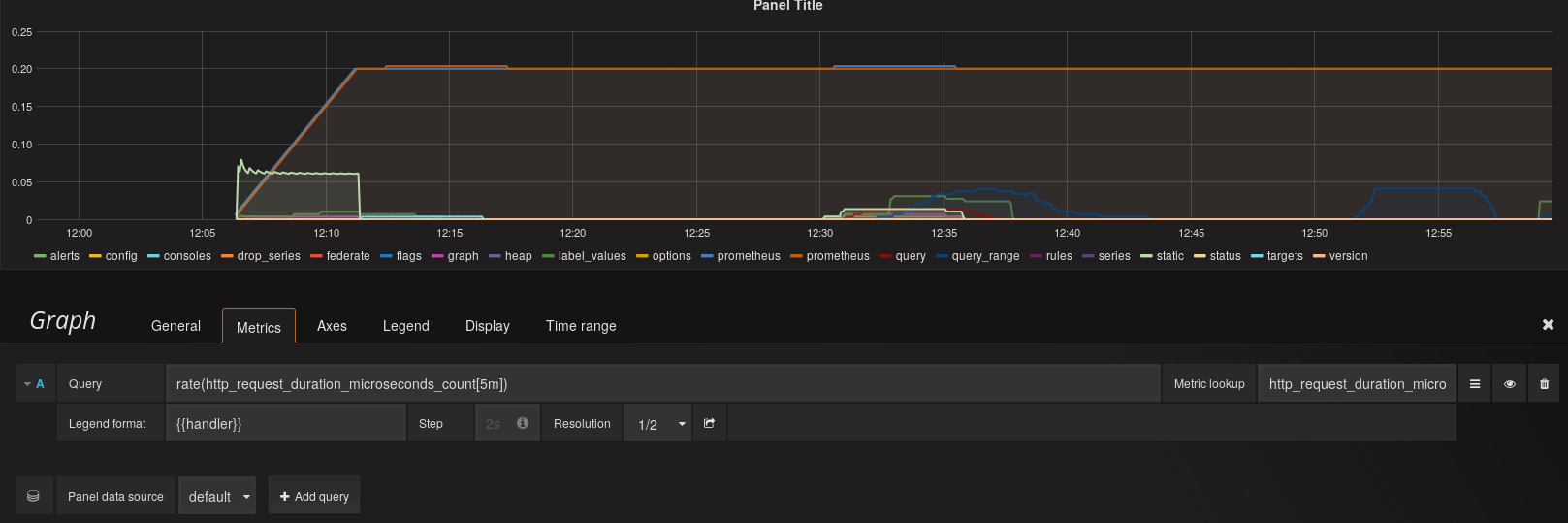
Prometheusのコンソールで入力できたものはそのまま入力できます。補完もlookup metricsというところから入力すると機能します。
とりあえず適当なメトリクスでグラフを作り、後は保存するなりすれば、以後は一覧から選択するだけでそのグラフにアクセスできるようになります。
その他グラフ作成の詳細はGrafana自体の機能なのでGrafanaの公式ページでも見てもらえればと思います。
その他
以下は気になってるけどまだ試せていないので今後試すことができたら追記しようと思います。
- Pushgateway
最初に書きましたがPushgatewayを使うとPullではなくPushもできるようになります。 -
Consul連携
Consulと連携することでConsulから監視対象を取得できるようなので監視対象の増減に伴う設定ファイルの書き換えが不要になりそうなので試してみたいと思っています。 -
Federation
Federationを使うと他のPrometheusのインスタンスからメトリクスの取得ができるようです。スケールさせる場合等に使うようですが、今のところそこまでの規模が必要になることは無さそうなので試すことは無いかもしれません。。。
最後に
ということで簡単にPrometheusの使い方を見てみました。
中々面白そうなので機会があれば実戦投入してみようと思います。
ちなみにdockerのswarmモード使いましたが、監視ツールは固定ノードで動かしたいし、監視対象もserviceとして作ってしまうと落ちたことに気付けない(Routing meshで別のノードからのレスポンスを受け取ってしまう)といったことがあるので、swarmモードの例としては激しく不適切だったかなと思います。ということで、実際に作る場合は普通にcompose辺りを使って立てるのが良いかと思います。