語彙力診断
2016年8月18日,とある診断がバズりました.
この診断は50問の類義語/対義語に関する4択問題に答えると点数化され,分布のどの辺にいるのかを教えてくれます.
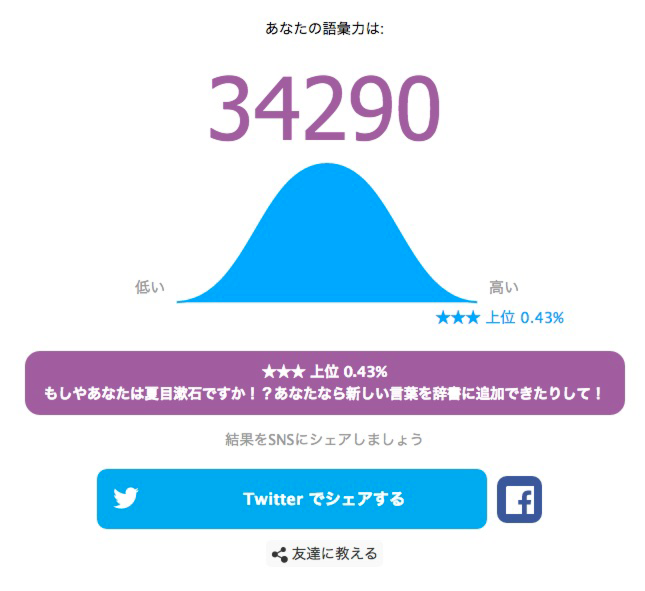
しかし,Twitterで該当ハッシュタグ#私の語彙力はを検索…するまでもなくこの点数が"上位0.43%"でないことくらい感覚的に分かります.
なので点数分布を取ってみました.
そもそもこんな診断は信憑性のかけらもないよとか言わない.
検索・分布の描画
Twitter APIを使ったプログラムを組むのはほぼ初めてなので,以下
Python で Twitter から情報収集 (Twitter API 編)
をベースにして組みました.
変更点は点数の取得とヒストグラムの描画と検索件数の変更です.
if point <= 36600としてるのはネタでめちゃめちゃデカい点数に改変してツイートする人がいるから.
検索した感じだと何故この点数なのか知らないけど,36600点が満点らしい.ヒト桁点はもう知らん.
from requests_oauthlib import OAuth1Session
import json
import re
import matplotlib.pyplot as plt
keysfile = open('keys.json')
keys = json.load(keysfile)
def main():
maxid = None
pointarray = []
pattern = '【[0-9]+】'
counter = 0
for i in range(0,100):
tweets = tweet_search('#私の語彙力は', keys,maxid)
if tweets == None or len(tweets['statuses']) == 0:
return pointarray
for tweet in tweets['statuses']:
text = tweet['text']
maxid = tweet['id']
m = re.search(pattern, text)
if m!=None:
point = m.group(0)
point = int(point[1:-1])
if point <= 36600 and point >= 0:
pointarray.append(int(point))
counter+=1
if counter%1000 == 0:
print('counter={0}'.format(counter))
return pointarray
def create_oath_session(oath_key_dict):
oath = OAuth1Session(
oath_key_dict['consumer_key'],
oath_key_dict['consumer_secret'],
oath_key_dict['access_token'],
oath_key_dict['access_token_secret']
)
return oath
def tweet_search(search_word, oath_key_dict, maxid=None):
if maxid is not None:
maxid = int(maxid) - 1
url = 'https://api.twitter.com/1.1/search/tweets.json?'
params = {
'q': search_word,
'lang': 'ja',
'result_type': 'recent',
'count': '100',
'max_id': maxid
}
oath = create_oath_session(oath_key_dict)
responce = oath.get(url, params = params)
if responce.status_code != 200:
print('Error code: %d' %(responce.status_code))
return None
tweets = json.loads(responce.text)
return tweets
if __name__ == '__main__':
pointarray = main()
plt.hist(pointarray,bins=100)
plt.show()
語彙力ヒストグラム
上のプログラムによって以下のヒストグラムが得られました.軸ラベルは(めんどくさくなって)あとから足した.
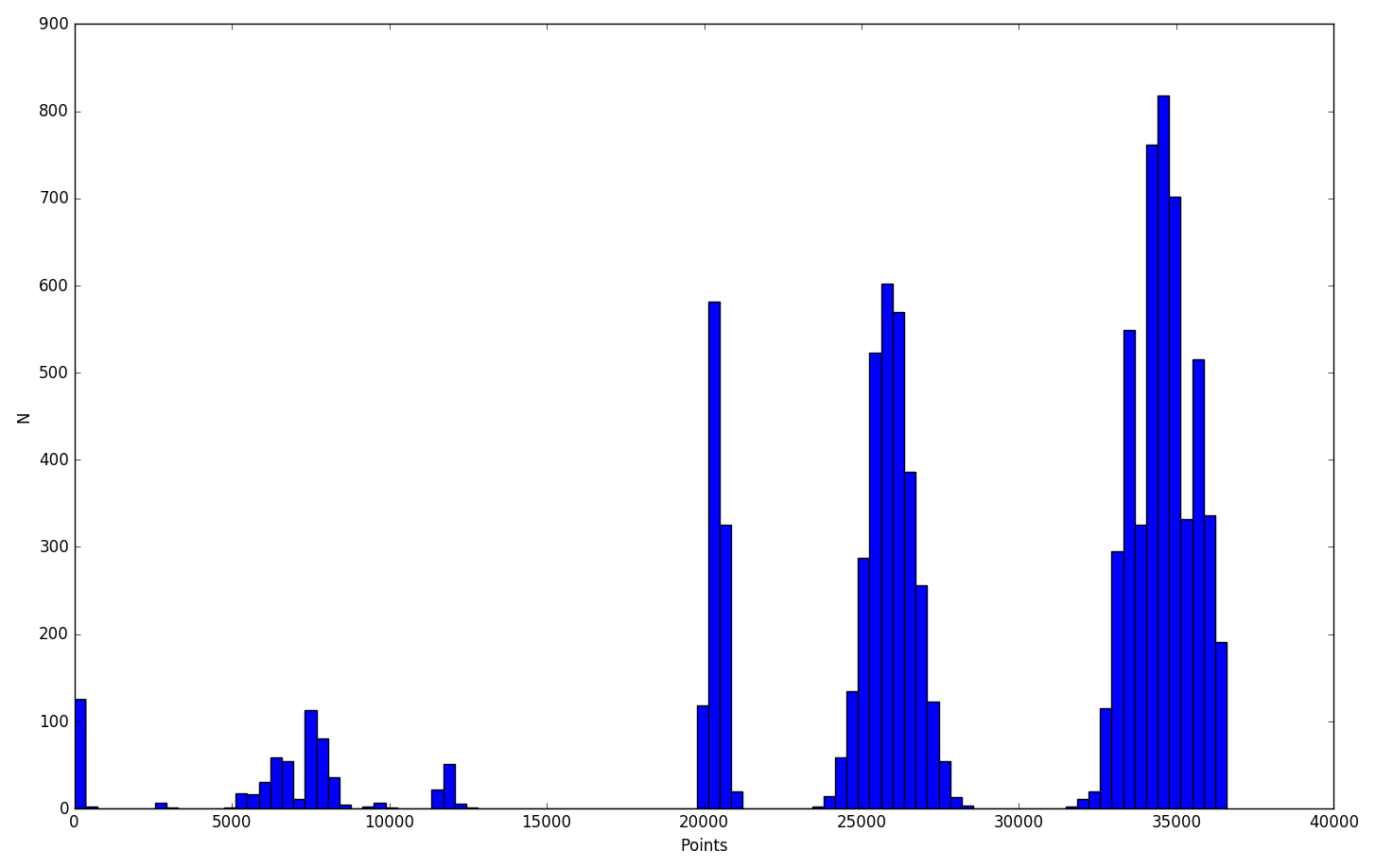
30000点あたりに全く分布しないことから,多分10000点の配点の問題がどこかにあるんでしょう.
あと多分5000点の配点の問題もある.
でも35000±α点くらい取ってたら上のグループには属していることになるので,ちょっとした自己満足くらいは得ることが出来ます.
まとめ
この手の診断って定期的にバズりますよね.ちょっとした暇つぶしくらいにはなるけど診断結果は信用しちゃいけない…ことの確認になりました.
信用してる人の方が少ないと思うけど.
診断サイト側も診断結果を貯めてちゃんと分布取ればいいのに
(ある程度)信頼できる語彙力検定をしたい人は朝日新聞社とベネッセが行っている語彙・読解力検定を受験しましょう.Web上でミニ検定も受けられます.