はじめに
メトリクス監視環境を作るにあたって出来るだけモダンそうなOSSを組み合わせてみようと考え、Fluentd、Kafka、InfluxDB、Grafanaを使って構築してみた。なお、この記事では各ミドルウェアの構築手順は記していない。どちらかというと、どうやってFluentd経由でサーバのメトリクスを取得して、Kafka ProducerとしてKafkaにデータを流して、またKafka ConsumerとしてデータをInfluxDBに流しているのか、という部分について簡単に記述している。
概要
各ミドルウェアの役割は以下の通りである。
| Middleware | Role |
|---|---|
| Fluentd | Kafka Producer & Consumer |
| Kafka | Messaging Queue |
| InfluxDB | TSDB |
| Grafana | Web Interface |
ラフな図にするとこのような感じである。
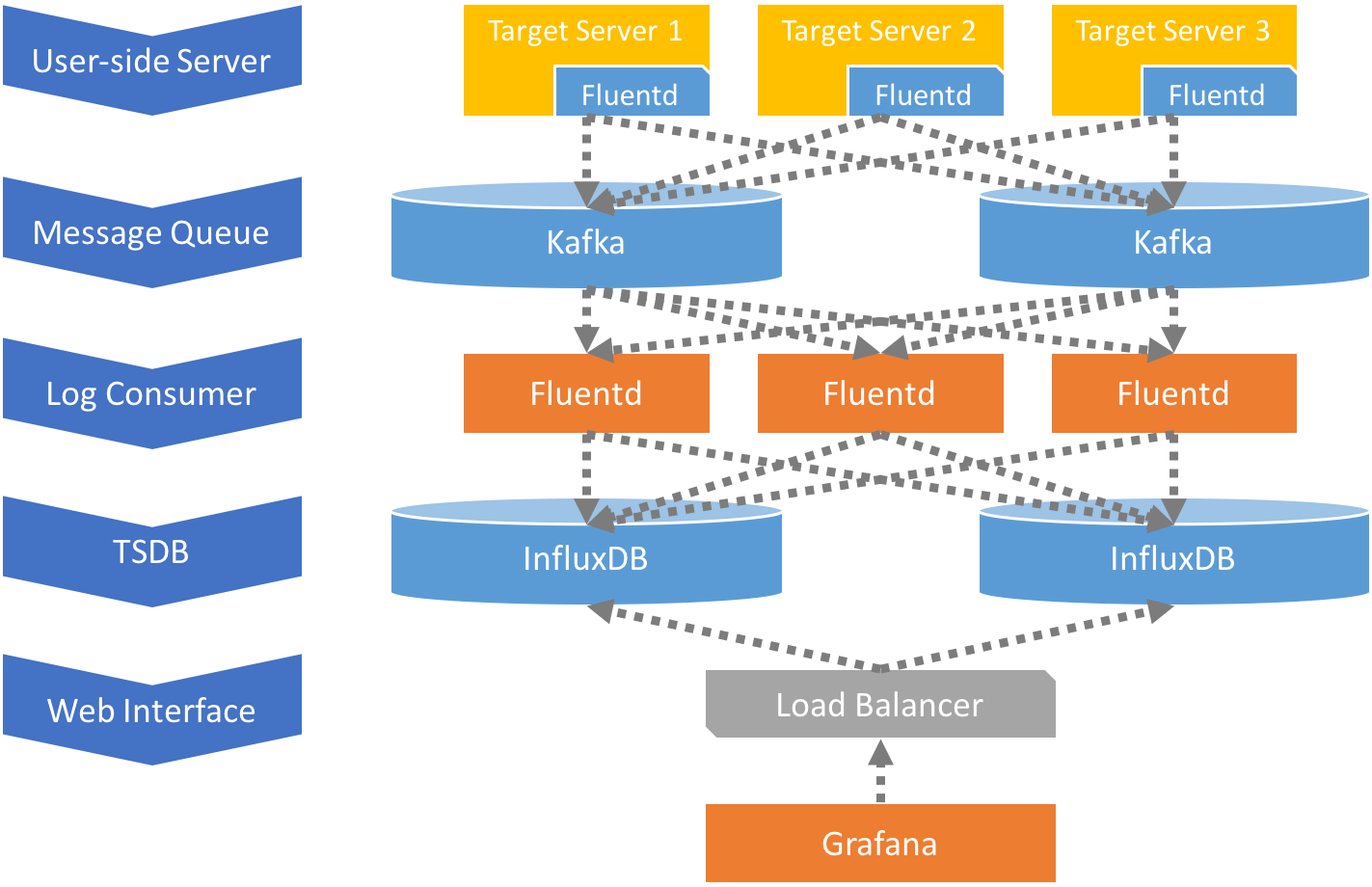
クラスタリング機能が無くなったOSS版InfluxDBで簡単な冗長性を持たせる
OSS版InfluxDBについては元々クラスタリング機能が存在したが、v0.12以降はOSS版InfluxDBでのクラスタリングは廃止され、以後Influx Enterprise及び、Influx Cloudを通じての提供する方針になっている。
日本語の詳細記事はこちらを是非参照してみてほしい。
今回は、OSS版InfluxDBを使う前提なので、カジュアルにDBへのダブルポストを行い、かつ耐障害性もそこそこある構成にするためにKafkaを使っている。Kafkaを使うことで、メトリクスデータは、InfluxDBに投入される前の段階において、Retention期間中Kafkaクラスター内で冗長化された状態で保持される。また、Kafka Consumerとして使うFluentdもConsumer Groupを用いて複数台にスケールしている。そうすることで、監視対象のクライアントサイドからInfluxDBまでのどこで障害が起こっても、どこかの地点では確実にデータが保持され、SPOFになることはないはずである。
Fluentdの設定(Kafka Producer)
Fluentdを用いてメトリクスデータを取得する方法として、今回はdstatとdfを用いた。dstatが入っていない場合は、事前にdstatをインストールしておく必要がある。またFluentdはv0.12以降をインストールする必要がある。インストールが必要なアプリとFluentdのPluginは以下の通りである。
事前にインストールするアプリケーション
- dstat
- Fluentd (v0.12 or later)
インストールが必要なFluentd Plugin
- fluent-plugin-record-reformer
- fluent-plugin-dstat
- fluent-plugin-kafka
Fluentdのconfは以下のような設定にする。
<source>
@type dstat
tag raw_dstat
option -cmldrn
delay 10
tmp_file /tmp/dstat_all.csv
</source>
<source>
@type exec
tag raw_df
command df -TP | sed 1d | sed 's/%//' | sed 's/\s\+/\t/g'
run_interval 10s
format tsv
keys device,type,size,used,available,capacity,mounted_on
</source>
<filter raw_df>
@type record_transformer
enable_ruby true
<record>
hostname ${hostname}
</record>
</filter>
<match raw_dstat raw_df>
@type kafka_buffered
brokers kafkabroker001:9092,kafkabroker002:9092
default_topic metrics-topic
flush_interval 60
buffer_type file
buffer_path /tmp/td-agent.*.buffer
output_data_type json
output_include_tag true
output_include_time true
</match>
Brokerがkafkabroker001:9092,kafkabroker002:9092であり、Topic名がmetrics-topicという名前であるという仮定している。dfに関してはデバイスごとのキャパシティが取得できるのだが、Fluentdのtag名がdf.<デバイス名>になってしまい、かつ取得できるjsonにデバイス名が含まれていないため、reord_reformaerで書き換えている。
Fluentdの設定(Kafka Consumer)
今回、FluentdをKafka Consuemerとしても使用する。ConsumerとしてKafkaからデータを取得してInfluxDBにダブルポストを行う。
インストールが必要なFluentd Plugin
- fluent-plugin-record-reformer
- fluent-plugin-influxdb
- fluent-plugin-kafka
Fluentdのconfは以下のような設定にする。
<source>
@type kafka_group
brokers kafkabroker001:9092,kafkabroker002:9092
consumer_group consumer_group_001
topics metrics-topic
format json
</source>
<match metrics-topic>
@type record_reformer
tag ${record['tag']}
enable_ruby true
auto_typecast true
</match>
<match raw_dstat>
@type copy
<store>
@type record_reformer
tag cpu
enable_ruby true
auto_typecast true
renew_record true
<record>
host ${record['hostname']}
usr ${record['dstat']['total_cpu_usage']['usr'].to_f}
sys ${record['dstat']['total_cpu_usage']['sys'].to_f}
idl ${record['dstat']['total_cpu_usage']['idl'].to_f}
wai ${record['dstat']['total_cpu_usage']['wai'].to_f}
hiq ${record['dstat']['total_cpu_usage']['hiq'].to_f}
siq ${record['dstat']['total_cpu_usage']['siq'].to_f}
time ${record['time']}
</record>
</store>
<store>
@type record_reformer
tag mem
enable_ruby true
auto_typecast true
renew_record true
<record>
host ${record['hostname']}
used ${record['dstat']['memory_usage']['used'].to_f}
buff ${record['dstat']['memory_usage']['buff'].to_f}
cach ${record['dstat']['memory_usage']['cach'].to_f}
free ${record['dstat']['memory_usage']['free'].to_f}
time ${record['time']}
</record>
</store>
<store>
@type record_reformer
tag load
enable_ruby true
auto_typecast true
renew_record true
<record>
host ${record['hostname']}
1m ${record['dstat']['load_avg']['1m'].to_f}
5m ${record['dstat']['load_avg']['5m'].to_f}
15m ${record['dstat']['load_avg']['15m'].to_f}
time ${record['time']}
</record>
</store>
<store>
@type record_reformer
tag disk
enable_ruby true
auto_typecast true
renew_record true
<record>
host ${record['hostname']}
read ${record['dstat']['dsk/total']['read'].to_f}
writ ${record['dstat']['dsk/total']['writ'].to_f}
time ${record['time']}
</record>
</store>
<store>
@type record_reformer
tag diskio
enable_ruby true
auto_typecast true
renew_record true
<record>
host ${record['hostname']}
read ${record['dstat']['io/total']['read'].to_f}
writ ${record['dstat']['io/total']['writ'].to_f}
time ${record['time']}
</record>
</store>
<store>
@type record_reformer
tag net
enable_ruby true
auto_typecast true
renew_record true
<record>
host ${record['hostname']}
recv ${record['dstat']['net/total']['recv'].to_f}
send ${record['dstat']['net/total']['send'].to_f}
time ${record['time']}
</record>
</store>
</match>
<match raw_df>
@type record_reformer
tag df
enable_ruby true
auto_typecast true
renew_record true
<record>
host ${record['hostname']}
size ${record['size'].to_f}
used ${record['used'].to_f}
available ${record['available'].to_f}
capacity ${record['capacity'].to_f}
device ${record['device']}
type ${record['type']}
mounted_on ${record['mounted_on']}
time ${record['time']}
</record>
</match>
<filter df cpu mem load disk diskio net>
@type record_transformer
renew_time_key time
</filter>
<filter df cpu mem load disk diskio net>
@type record_transformer
remove_keys time
</filter>
<match df cpu mem load disk diskio net>
@type copy
<store>
@type influxdb
host influxdb001
port 8086
dbname metrics_db
user kafka
password kafka
use_ssl false
verify_ssl false
tag_keys ["host", "device"]
time_precision s
flush_interval 10s
</store>
<store>
@type influxdb
host influxdb002
port 8086
dbname metrics_db
user kafka
password kafka
use_ssl false
verify_ssl false
tag_keys ["host", "device", "type", "mounted_on",]
time_precision s
flush_interval 10s
</store>
</match>
InfluxDBのホスト名をinfluxdb001とinfluxdb002とし、DB名を両方ともmetrics_dbと仮定している。また、InfluxDBのTagには、Strings型で取得しているhostとdeviceを設定している。
Kafka & InfluxDB
事前にKafkaのTopicやInfluxDBのデータベースを作成しておく。細かいチューニングはこの記事では省させていただく。
Grafana
InfluxDBにデータが投入されれば、Grafanaからは以下のように容易にグラフを作成可能である。
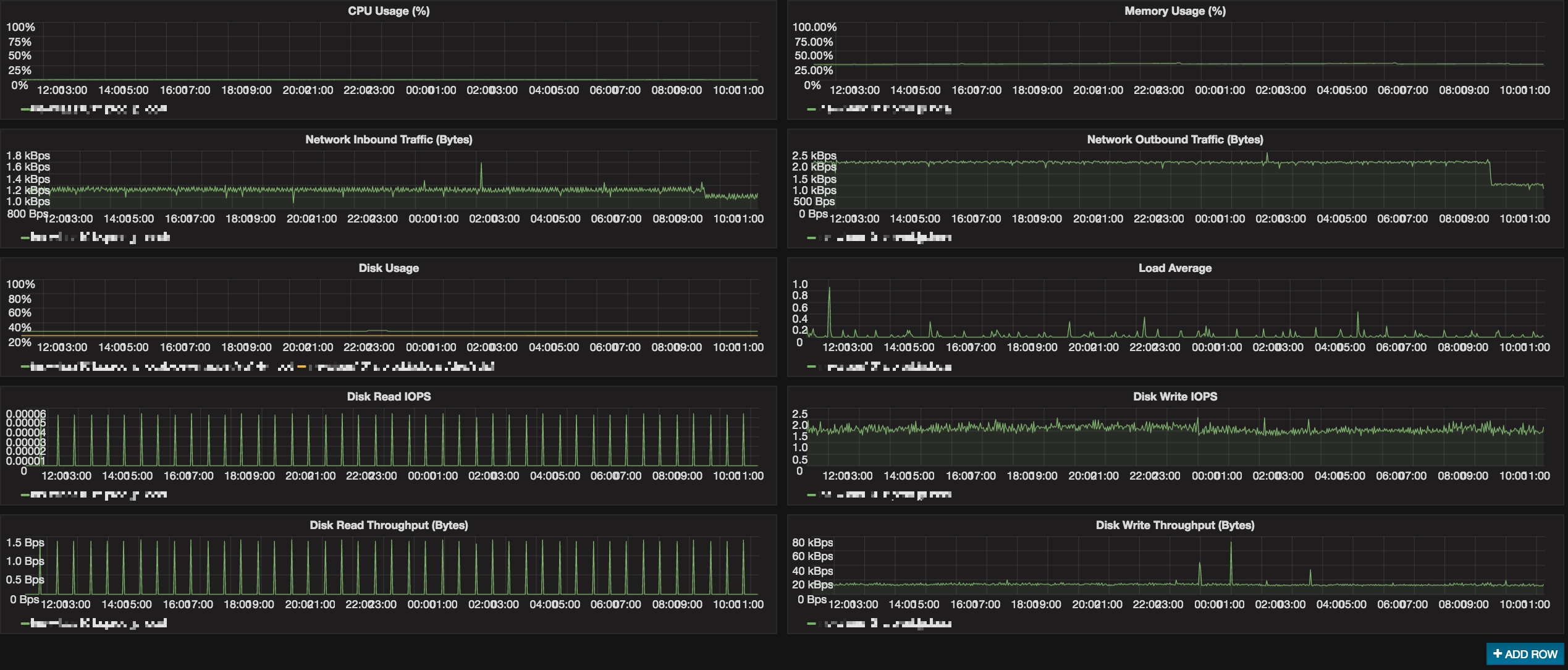
GrafanaからInfluxDBへ接続する際、InfluxDBのフロントにロードバランサを配置しGrafanaがロードバランサに接続するように設定しておけば、どちらかのInfluxDBが障害でダウンしていたとしても、継続してGrafanaから監視データを確認することが可能である。
おわりに
そんなめんどくさいことせずにTelegraf使えよって言われたらそれまでなんだが、元々Fluentdを別のログ収集目的で既に使っていて別途Telegrafを入れたくない場合みたいな、どうしてもFluentdを使ってメトリクス監視をやりたい場合には、今回のようなやり方が妥当な方法なんじゃなかろうか。dstatやdfを使わなくても/proc配下をチェックするFluentd Pluginがあったらもっとスマートなのかもしれない。今回は既存であるものを使ってできるかどうか試してみた次第である。
今回は、祝InfluxDB v1.0.0リリース! ということでこんな記事を書いてみました。