思ったより簡単にJupyter Notebook(iPython Notebook)でCythonを試せることが分かったのでメモです。Cythonは実行前にコンパイルすること、静的な型付けを行うことで処理を高速化します。
(本記事の.ipynbファイルはGithubのここにアップロードしてあります。)
環境
試した環境は下記です。MacとAnacondaで試しています。Anacondaを導入していれば特に準備は不要です。
Python 3.5.1 |Anaconda custom (x86_64)| (default, Jun 15 2016, 16:14:02)
[GCC 4.2.1 Compatible Apple LLVM 4.2 (clang-425.0.28)] on darwin
IPython 5.0.0
やってみよう
Cythonコンパイル用のマジックコマンド実行
# Jupyter Notebook上でcythonファイルのコンパイルができるようにする
%load_ext Cython
Cythonの関数を宣言
先頭に%%cythonを記載してcythonコードを書きます。
例はCython チュートリアル基礎編から使わせてもらいました。
# ↓ -n <ファイル名>をつけることで後でファイルが確認しやすくなります。
%%cython -n test_cython_code
def fib(int n):
cdef int i
cdef double a=0.0, b=1.0
for i in range(n):
a, b = a+b, a
return a
def primes(int kmax):
cdef int n, k, i
cdef int p[1000]
result = []
if kmax > 1000:
kmax = 1000
k = 0
n = 2
while k < kmax:
i = 0
while i < k and n % p[i] != 0:
i += 1
if i == k:
p[k] = n
k += 1
result.append(n)
n += 1
return result
試してみる
print(fib(90))
print(primes(20))
2.880067194370816e+18
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71]
できた!
生Pythonとの速度比較
同じ処理を生のPythonで書いて実行時間を比較してみます。
import numpy as np
# 性能比較用 Python関数
def pyfib(n):
a, b = 0.0, 1.0
for i in range(n):
a, b = a+b, a
return a
def pyprimes(kmax):
p = np.zeros(1000)
result = []
# 最大個数は1000個
if kmax > 1000:
kmax = 1000
k = 0
n = 2
while k < kmax:
i = 0
while i < k and n % p[i] != 0:
i += 1
if i == k:
p[k] = n
k += 1
result.append(n)
n += 1
return result
フィボナッチ数
# 1000番目のフィボナッチ数を繰り返し生成して計測
%timeit fib(1000)
%timeit pyfib(1000)
cythonの方が50倍くらい早いです!
1000000 loops, best of 3: 786 ns per loop
10000 loops, best of 3: 42.5 µs per loop
素数を取り出す
%timeit primes(1000)
%timeit pyprimes(1000)
100 loops, best of 3: 2.12 ms per loop
1 loop, best of 3: 218 ms per loop
こちらの計算では100倍くらい早いです!
Pandasのapplyに使ってみる
1000個の整数
df = pd.DataFrame(np.arange(1, 10**4), columns=['num'] )
apply関数の中に関数指定するだけで使えます ![]()
%timeit df['fib'] = df.num.apply(fib)
%timeit df['pyfib'] = df.num.apply(pyfib)
10 loops, best of 3: 39.2 ms per loop
1 loop, best of 3: 2.02 s per loop
print(df.head())
num fib pyfib
0 1 1.0 1.0
1 2 1.0 1.0
2 3 2.0 2.0
3 4 3.0 3.0
4 5 5.0 5.0
コンパイルされたcythonファイルは~/.ipython/cythonに格納されています。
コンパイル時に%%cython -n <ファイル名>でファイル名を指定してあった場合はそのファイル名でここに格納されています。
ndarrayを扱う
# データを作る
rd.seed(71)
n_data = 10**5
X = pd.DataFrame(rd.normal(size=3*n_data).reshape((n_data,3)), columns=["a", "b", "c"])
print(X.shape)
print(X.head())
(100000, 3)
a b c
0 -0.430603 -1.193928 -0.444299
1 0.489412 -0.451557 0.585696
2 1.177320 -0.965009 0.218278
3 -0.866144 -0.323006 1.412919
4 -0.712651 -1.362191 -1.705966
ndarrayを引数に取るCythonコードを書く
%%cython -n sample_calc
import numpy as np
cimport numpy as np
cpdef np.ndarray[double] sample_calc(np.ndarray col_a, np.ndarray col_b, np.ndarray col_c):
# 各列の型チェック
assert (col_a.dtype == np.float and col_b.dtype == np.float and col_c.dtype == np.float)
# 各列のサイズが同じであることをチェック
cdef Py_ssize_t n = len(col_c)
assert (len(col_a) == len(col_b) == n)
cdef np.ndarray[double] res = np.empty(n)
# (a-b)/c という計算をする
for i in range(n):
res[i] = (col_a[i] - col_b[i])/col_c[i]
return res
Python側から呼び出す
sample_calc(X.a.values, X.b.values, X.c.values)
array([-1.71804336, 1.60658332, 9.81468496, ..., -0.44683095,
0.46970409, -0.28352272])
# 比較用
def pysample_calc(col_a, col_b, col_c):
# 各列の型チェック
assert (col_a.dtype == np.float and col_b.dtype == np.float and col_c.dtype == np.float)
# 各列のサイズが同じであることをチェック
n = len(col_c)
assert (len(col_a) == len(col_b) == n)
res = np.empty(n)
# (a-b)/c という計算をする
for i in range(n):
res[i] = (col_a[i] - col_b[i])/col_c[i]
return res
%timeit sample_calc(X.a.values, X.b.values, X.c.values)
%timeit pysample_calc(X.a.values, X.b.values, X.c.values)
100 loops, best of 3: 16.7 ms per loop
10 loops, best of 3: 37.2 ms per loop
モンテカルロ法で円周率を計算
# データ生成
rd.seed(71)
n_data = 10**7
X2 = rd.random(size=(n_data,2)).astype(np.float)
X2.dtype
Cython関数の定義
%%cython -n calc_pi
import numpy as np
cimport numpy as np
cpdef np.ndarray[long] calc_pi(np.ndarray[double, ndim=2] data):
cdef Py_ssize_t n = len(data)
cdef np.ndarray[long] res = np.empty(n, dtype=np.int)
for i in range(n):
res[i] = 1 if (data[i,0]**2 + data[i,1]**2) < 1 else 0
return res
比較用Python関数
# 比較用Python関数
def pycalc_pi(data):
n = len(data)
res = [1 if (data[i,0]**2 + data[i,1]**2) < 1 else 0 for i in range(n)]
return res
計測してみる。
%time calc_pi(X2)
%time pycalc_pi(X2)
CPU times: user 25.2 ms, sys: 5.98 ms, total: 31.2 ms
Wall time: 31.1 ms
CPU times: user 7.7 s, sys: 46.1 ms, total: 7.75 s
Wall time: 7.75 s
Cythonの方がだいぶ早い!
# 結果が同一か確認
np.all(res == respy)
あってる!
True
# 円周率の計算
np.sum(res)/n_data*4
3.1413555999999998
描画してみる。
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from matplotlib.colors import LinearSegmentedColormap
sns.set(style="darkgrid", palette="muted", color_codes=True)
# 描画する
n_plot = 10**4 # 描画する点の数
plt.figure(figsize=(8,8))
plt.scatter(X2[:n_plot,0], X2[:n_plot,1], c=res[:n_plot], s=10)
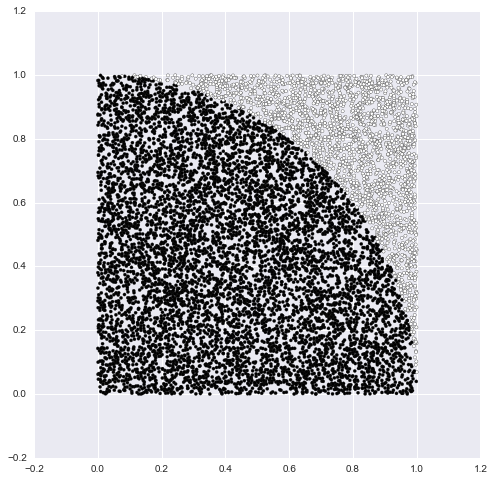
ちゃんと円の中と外を判定していますね。
参考
Cython チュートリアル基礎編
http://omake.accense.com/static/doc-ja/cython/src/userguide/tutorial.html
オライリー "Cython"
https://www.oreilly.co.jp/books/9784873117270/
pandas 0.18.1 documentation Enhancing Performance
http://pandas.pydata.org/pandas-docs/stable/enhancingperf.html