ElasticBeanstalkをより便利に使う
ElasticBeanstalk使ってますか?
サーバー、ロードバランサー、DBなどをセットで提供してくれるので、可用性を持ったサービスが簡単に構築できて便利ですよね。
異常発生時の自動復旧も「ある程度」やってくれます。
…あえて「ある程度」と表現しました。
異常の種類によって、自動復旧してくれるケースとしてくれないケースがあるのです。
以下に整理します。
プラットフォームにdockerを選択して、Webアプリを公開しているとします。
| 状態 | ElasticBeanstalkが自動でやってくれる事 |
|---|---|
| EC2インスタンスのステータスが"running"以外になる | 該当EC2インスタンスの削除&新規EC2インスタンスの起動 |
| EC2インスタンス上のdockerプロセスが停止する | 何もしない |
| docker上のWebサーバーが停止する | 何もしない |
つまり、2番目と3番目が起こった場合、サービスの提供が止まっているのにも関わらず、ElasticBeanstalkは自動では復旧をしてくれないのです。
この記事では、2番目と3番目が起こった場合でも自動で復旧する仕組みを作る方法を紹介します。
プロセス監視などのサーバー追加なしに、簡単に仕組みを構築できますので、ぜひやってみて下さい。
必要な前提知識
- ElasticBeanstalkの利用方法
- SNSの利用方法
- Lambdaの利用方法
構築する仕組み概要
以下の仕組みを構築して、サービスの自動復旧を強化します。
- ElasticBeanstalkの拡張ヘルスモニタリングを使って、配下のEC2インスタンスが正常に動作しているかどうかの監視を行う
- 1で異常が発生した時には、SNSを介してLambdaファンクションを実行するようにする
- Lambdaファンクションで、異常が発生したEC2インスタンスの停止を行う
- EC2インスタンスが停止すると、ElasticBeanstalkが自動で停止したEC2インスタンスの削除&EC2の新規作成をやってくれる(ここは設定などの必要なし)
- 自動復旧完了!
上記の仕組みは、ElasticBeanstalk配下に複数のEC2インスタンスがある場合でも活用できます。
3台のサーバーが動いていて、1台のサーバーに異常が起こったとしても、上記の仕組みは機能する(拡張ヘルスモニタリングがちゃんと教えてくれる)ので、異常発生前の状態(3台稼働の状態)を維持する事ができます。
構築方法の詳細
1. 拡張ヘルスモニタリングの設定をする
ElasticBeanstalkの拡張ヘルスモニタリング機能を使って、あるURLに対するリクエストが有効になっているかの監視を行うようにします。
監視はEC2インスタンスごとに行われるので、複数のEC2インスタンスがある場合、1つでもリクエストが無効になればアラートをあげる事が可能です。
拡張ヘルスモニタリングの設定をします。
ElasticBeanstalkのコンソール画面の「設定」→「ヘルス」から設定します。
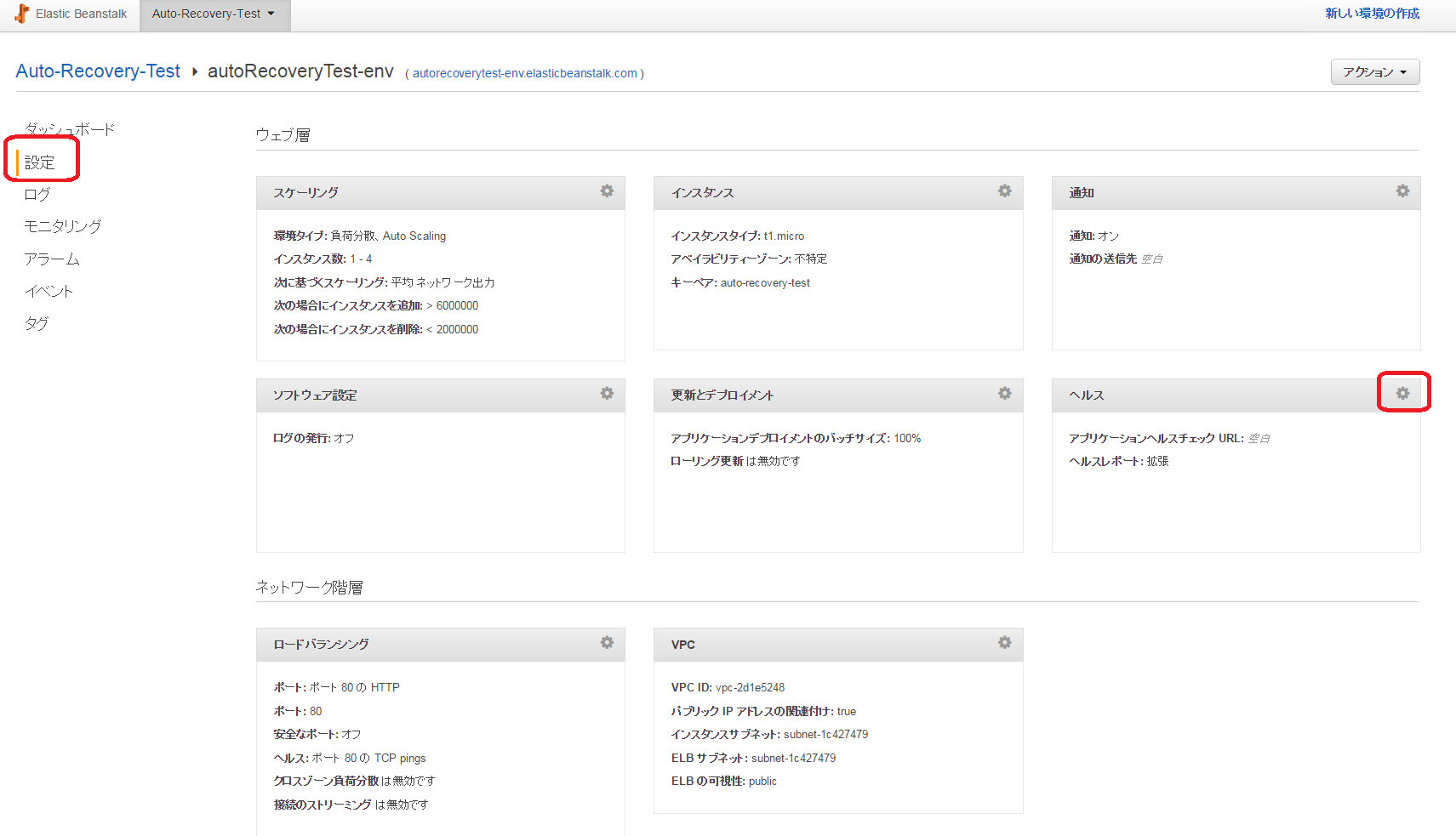
「アプリケーションのヘルスチェックURL」にヘルスチェックに利用するURLを入力します。
ここで指定したURLにアクセスできるかどうかが、チェック事項になります。
「ヘルスレポート」のシステムタイプを「拡張」にします。
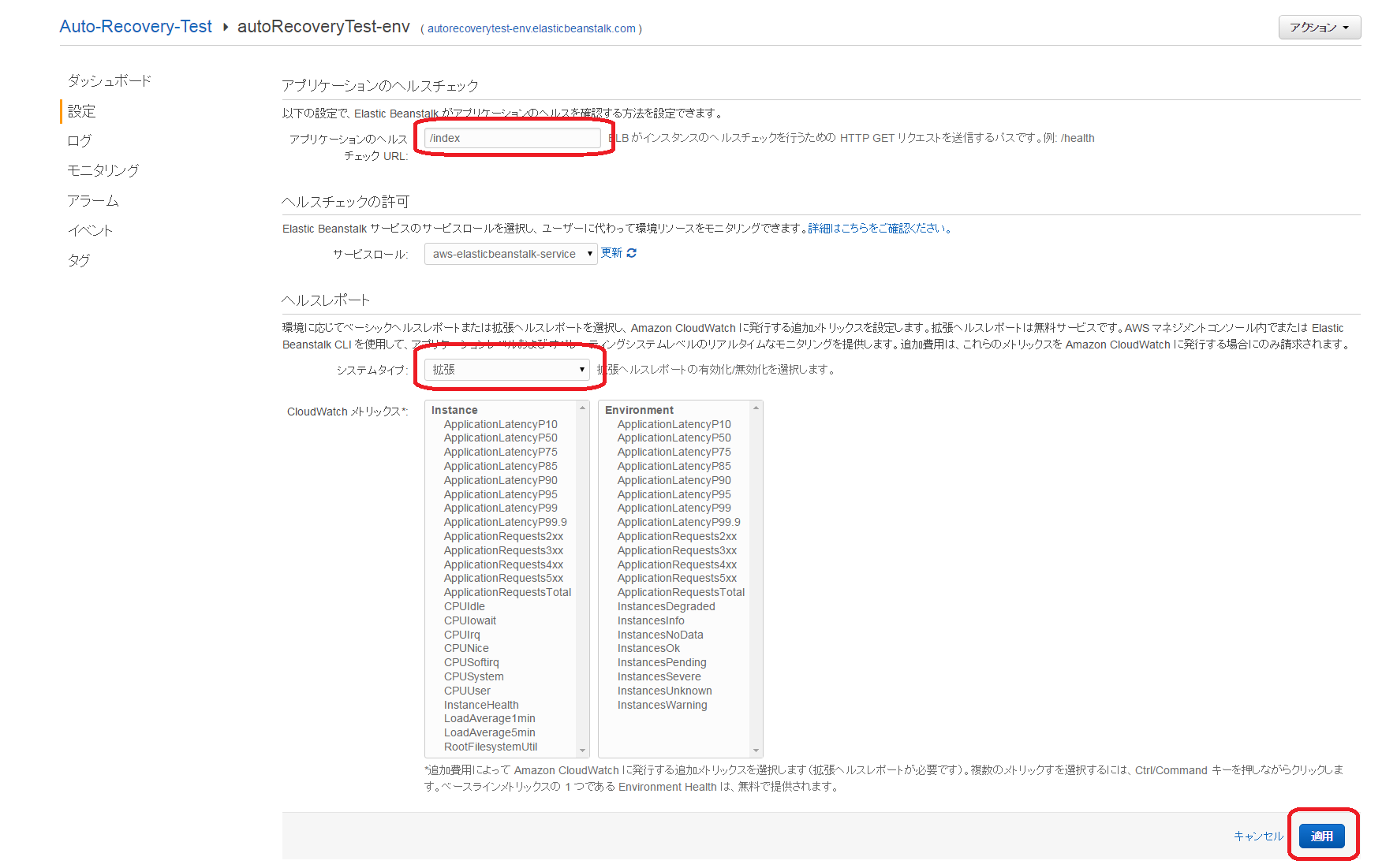
設定が完了すると、「モニタリング」において新しく「Environment Helth ヘルスコード別」が見れるようになります。
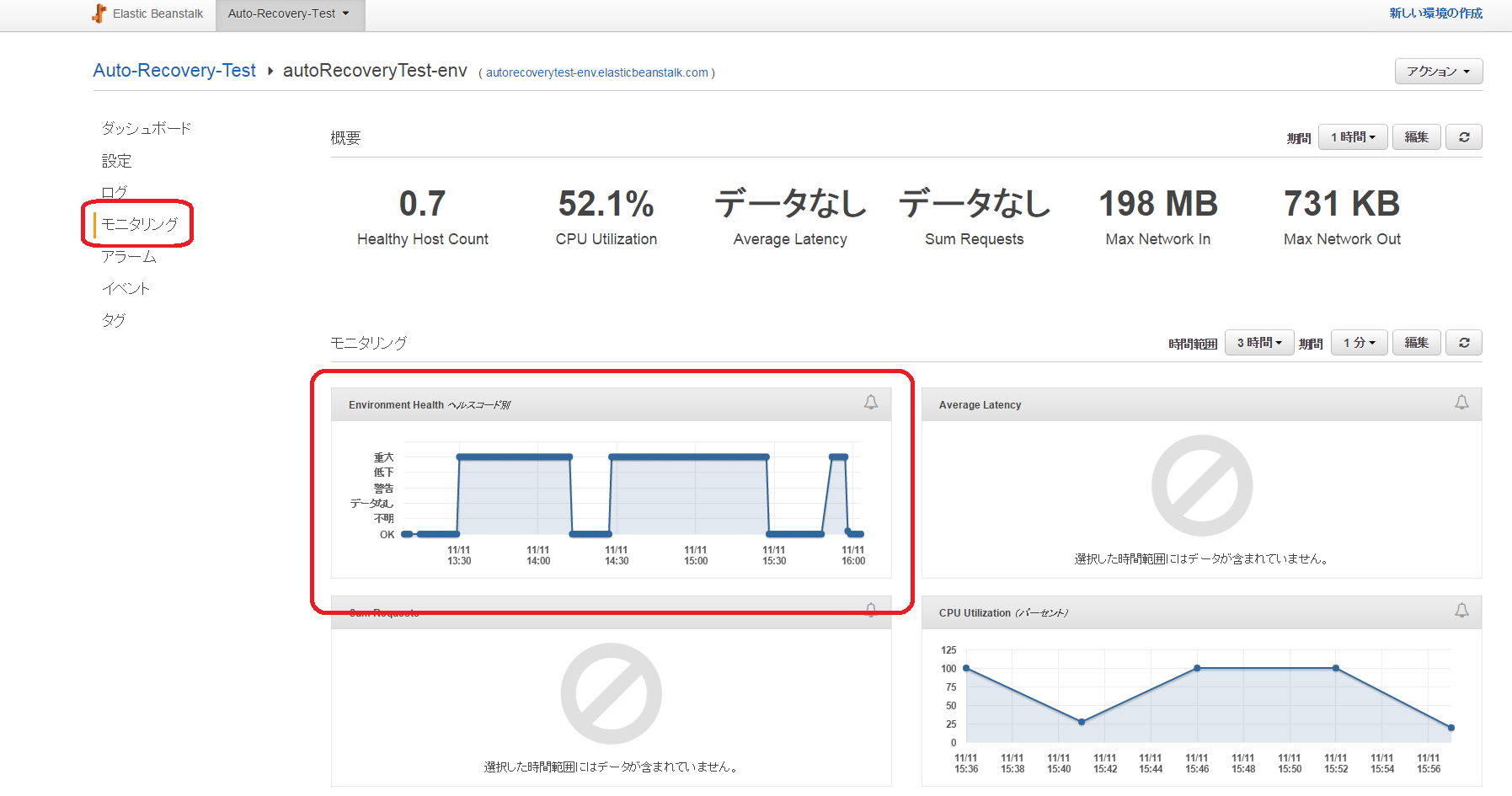
確認したところ、状態とヘルスコードの関係は以下のようになっていました。
| 状態 | ヘルスコード |
|---|---|
| 全てのEC2インスタンスが正常 | OK |
| 一部のEC2インスタンスが異常 | 低下 |
| 全てのEC2インスタンスが異常 | 重大 |
ここまでで、1つでもEC2インスタンスが異常になれば、それを知る事ができるようになりました。
2. SNSの設定をする
続いて、拡張ヘルスモニタリングが"OK"以外となった場合にSNS通知ができるように設定をします。
「モニタリング」の「Environment Helth ヘルスコード別」のベルマークから設定します。
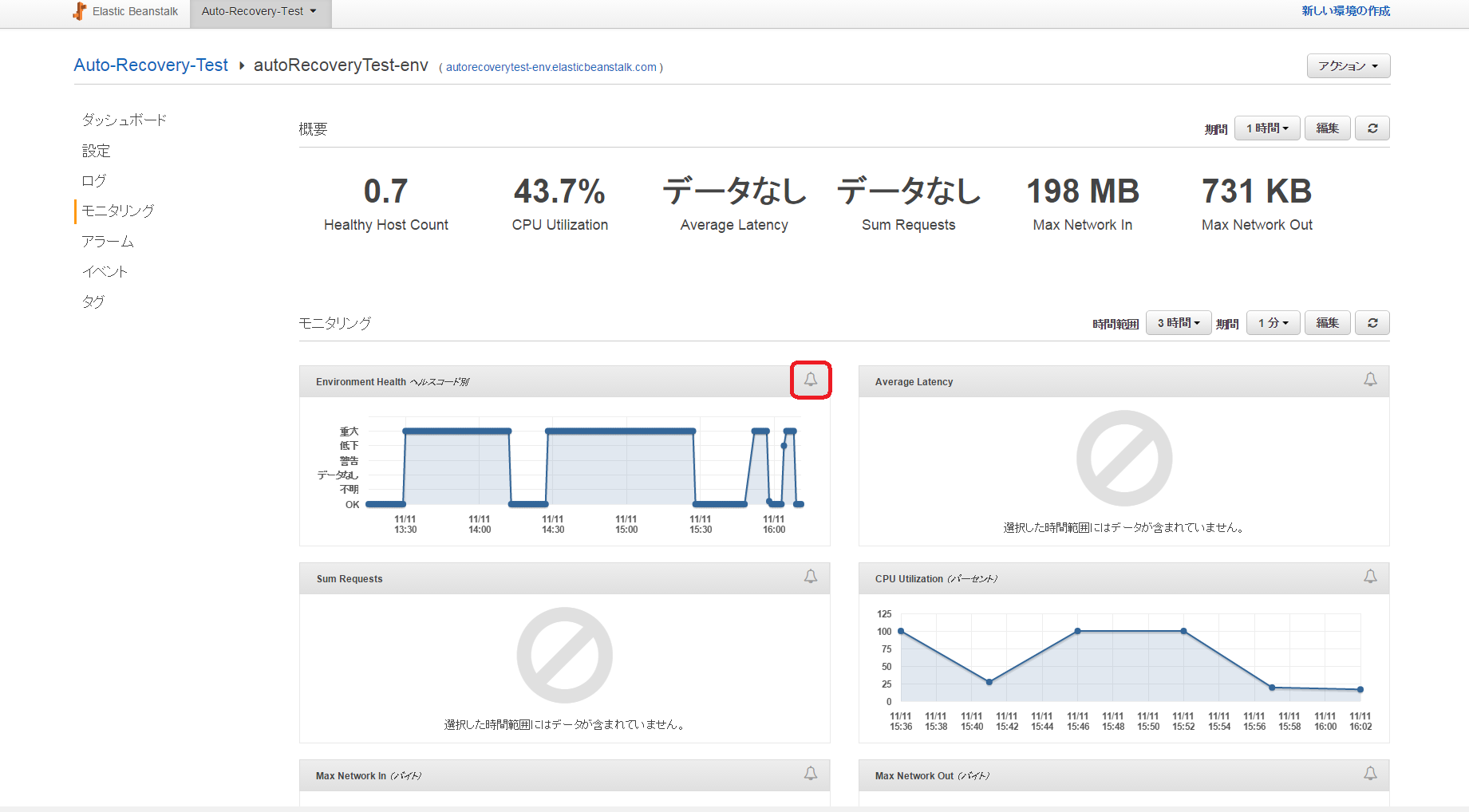
以下のように設定します。
しきい値:Maximum EnvironmentHelth > 0
次の状態の時に通知:アラームにチェックを入れる
EnvironmentHelthはOKの時が0で、異常状態は0よりも大きな値が設定されています。
なので、OK以外の時にアラートを出すために、EnvironmentHelth > 0と設定します。
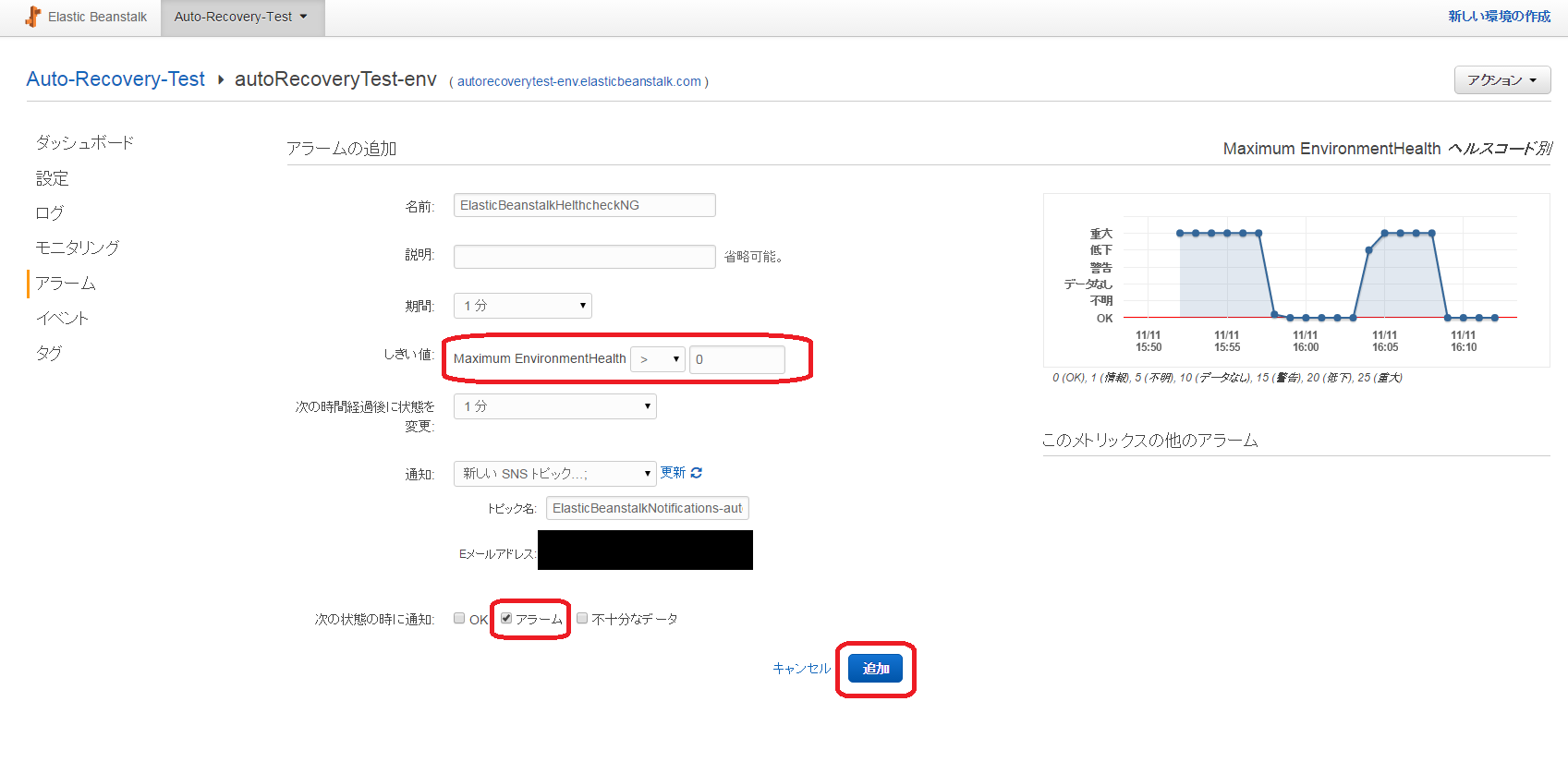
上記の設定で必要なSNSTopicも作成されます。
ここまでで、EC2インスタンスに異常が発生した場合SNS通知が飛ぶようになりました。
3. Lambdaファンクションの設定をする
まずはLambdaファンクションを書きます。
ファンクションでやる事は以下です。
- SNSのメッセージから、異常が発生したElasticBeanstalkの環境名を取得する
- 対象のElasticBeanstalk配下にある、ヘルスモニタリングNGとなったEC2インスタンスを取得する
- 2で取得したEC2インスタンスを停止する
Javaで書きました。ご利用下さい。
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import com.amazonaws.services.ec2.AmazonEC2Client;
import com.amazonaws.services.ec2.model.DescribeInstancesRequest;
import com.amazonaws.services.ec2.model.DescribeInstancesResult;
import com.amazonaws.services.ec2.model.Reservation;
import com.amazonaws.services.ec2.model.StopInstancesRequest;
import com.amazonaws.services.elasticbeanstalk.AWSElasticBeanstalkClient;
import com.amazonaws.services.elasticbeanstalk.model.DescribeInstancesHealthRequest;
import com.amazonaws.services.elasticbeanstalk.model.DescribeInstancesHealthResult;
import com.amazonaws.services.elasticbeanstalk.model.InstancesHealthAttribute;
import com.amazonaws.services.elasticbeanstalk.model.SingleInstanceHealth;
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import com.amazonaws.services.lambda.runtime.events.SNSEvent;
import com.amazonaws.services.lambda.runtime.events.SNSEvent.SNSRecord;
import com.amazonaws.util.json.JSONArray;
import com.amazonaws.util.json.JSONException;
import com.amazonaws.util.json.JSONObject;
public class LambdaFunctionHandler implements RequestHandler<SNSEvent, Object> {
@Override
public Object handleRequest(SNSEvent input, Context context) {
// SNSからElasticBeanstalkの環境名を取得する
String eBName = null;
List<SNSRecord> snsRecordList = input.getRecords();
String message = snsRecordList.get(0).getSNS().getMessage();
context.getLogger().log("SNS MESSAGE: " + message);
try {
JSONArray jsonArray = new JSONArray("[" + message + "]");
JSONObject jsonObject = jsonArray.getJSONObject(0);
eBName = jsonObject.getJSONObject("Trigger").getJSONArray("Dimensions").getJSONObject(0).getString("value");
context.getLogger().log("EB NAME: " + eBName);
} catch (JSONException e) {
context.getLogger().log("Error: " + e.getMessage());
return null;
}
// ElasticBeanstalk配下のヘルスチェックNGなEC2インスタンスをリストアップする
List<String> unHelthEC2InstanceList = new ArrayList<>();
AWSElasticBeanstalkClient aWSElasticBeanstalkClient = new AWSElasticBeanstalkClient();
DescribeInstancesHealthRequest describeInstancesHealthRequest = new DescribeInstancesHealthRequest();
List<String> attributeList = new ArrayList<>();
attributeList.add(InstancesHealthAttribute.HealthStatus.toString());
describeInstancesHealthRequest.setAttributeNames(attributeList);
describeInstancesHealthRequest.setEnvironmentName(eBName);
DescribeInstancesHealthResult describeInstancesHealthResult = aWSElasticBeanstalkClient.describeInstancesHealth(describeInstancesHealthRequest);
List<SingleInstanceHealth> instanceHelthList = describeInstancesHealthResult.getInstanceHealthList();
for (SingleInstanceHealth instanceHelth : instanceHelthList) {
context.getLogger().log(instanceHelth.getInstanceId() + " : " + instanceHelth.getHealthStatus());
if (!"Ok".equals(instanceHelth.getHealthStatus())) {
unHelthEC2InstanceList.add(instanceHelth.getInstanceId());
}
}
// UnHelthなEC2インスタンスのうち、起動から10分以上経っているインスタンスを停止対象とする
AmazonEC2Client ec2Client = new AmazonEC2Client();
List<String> stopEC2InstanceList = new ArrayList<String>();
DescribeInstancesRequest describeInstancesRequest = new DescribeInstancesRequest();
describeInstancesRequest.setInstanceIds(unHelthEC2InstanceList);
DescribeInstancesResult describeInstancesResult = ec2Client.describeInstances(describeInstancesRequest);
for (Reservation reservation : describeInstancesResult.getReservations()) {
for (com.amazonaws.services.ec2.model.Instance ec2Instance : reservation.getInstances()) {
long nowTime = new Date().getTime();
long launchTime = ec2Instance.getLaunchTime().getTime();
if ((nowTime - launchTime) > 1000 * 60 * 10) { // 10分以上経過しているかどうか
stopEC2InstanceList.add(ec2Instance.getInstanceId());
context.getLogger().log("Stop EC2 ID :" + ec2Instance.getInstanceId());
}
}
}
// UnHelthなEC2インスタンスの停止
if (stopEC2InstanceList.size() != 0) {
ec2Client.stopInstances(new StopInstancesRequest(stopEC2InstanceList));
context.getLogger().log("UnHelth EC2 Instance Stopped");
}
return null;
}
}
ソースコード中の
// UnHelthなEC2インスタンスのうち、起動から10分以上経っているインスタンスを停止対象とする
これは、EC2インスタンスが新たに生成されてから、ヘルスチェックがOKになるまで少し時間がかかるためです。
このチェックがないと、新たに生成されたEC2インスタンスがすぐに停止されてしまいます。
上記のコードをLambdaファンクションに設定して、Lmabdaの"Event Source"に「2. SNSの設定をする」の結果作られるSNS Topicを設定します。
これで仕組みは完成です!
EC2インスタンスが異常状態になった時だけでなく、EC2インスタンス上のプロセス停止時にも自動で復旧するようになります。
自動復旧の仕組みはワーカーアプリでも機能する
ElasticBeanstalkでは、Webアプリケーションとワーカーアプリケーションの2つを作る事ができます。
この仕組みはワーカーアプリでもちゃんと機能します。
ワーカーアプリで重要なプロセスにaws-sqsdがあります。
EC2インスタンス上で動作しSQSの処理をしてくれるプロセスです。
詳細は以下をご覧下さい。
http://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/using-features-managing-env-tiers.html
aws-sqsdが停止するとワーカーアプリも機能しなくなりますが、ElasticBeanstalkの拡張ヘルスモニタリングはちゃんとaws-sqsdの監視もしてくれます。
つまり、aws-sqsdが停止→アラート→Lambdaファンクション呼び出し、が機能するのです。
注意点
上記の構成による自動復旧には約5分かかります。
5分のダウンタイムが許されない場合には、ElasticBeanstalkの設定でEC2の最低インスタンス数を2以上にして下さい。
まとめ
ElasticBeanstalkがやってくれる異常発生時の自動復旧は「ある程度」です。
拡張ヘルスモニタリング + Lambdaで自動復旧を強化しましょう。