はじめに
画像中にある物体認識の機械学習モデルを作成するに当たってまず必要になるのが大量の訓練画像の収集です。
犬や車といった一般的なものであればImageNetなどのサービスからダウンロードすることができますが、例えば日本の有名人の画像なんかはありません。
今回はTumblr APIを使って機械学習用の画像データを集める方法をご紹介します。
Google Custom Search API ピカチュウ編はこちら
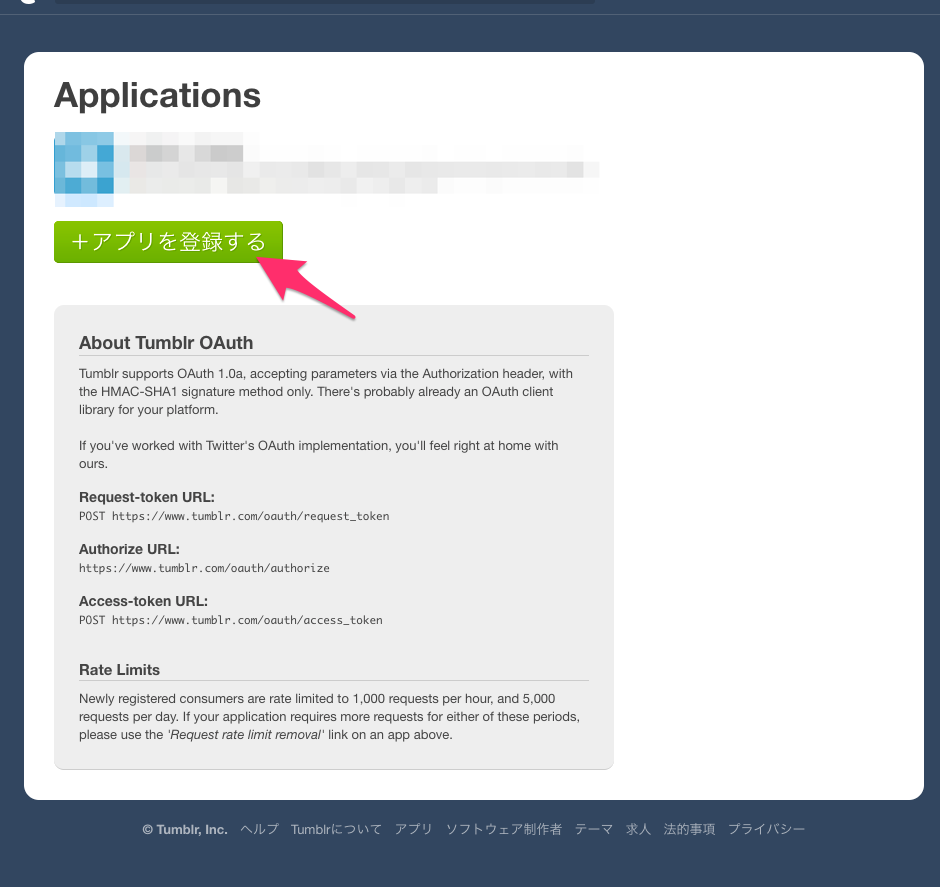
Tumblr API Keyを取得
アプリを登録するをクリック
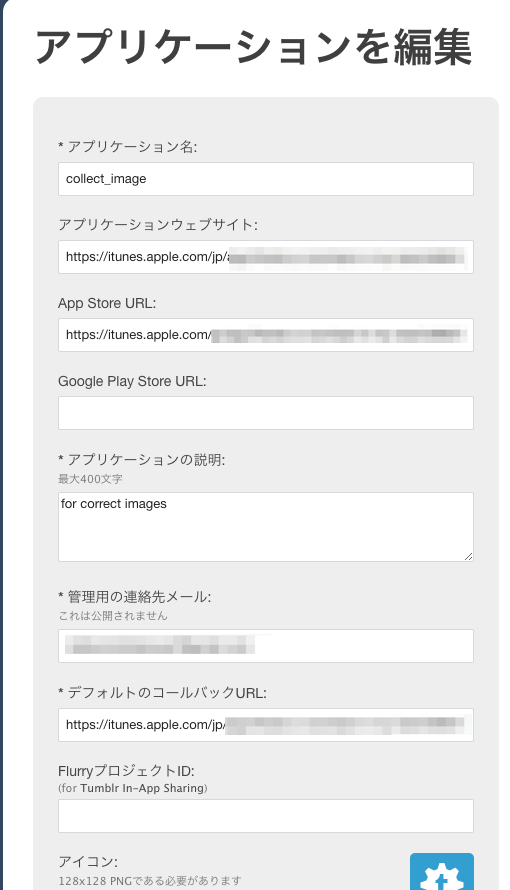
次にアプリケーションの情報を入力していきます。
URL入力(アプリケーションウェブサイト, App Store URL, Google Play Store URL)が必須ですが実際にOauthのアプリを作るわけではないのでここは適当なURLで華麗にかわしてしまいます。(今回は自分が昔作ったアプリのURLを使いました)
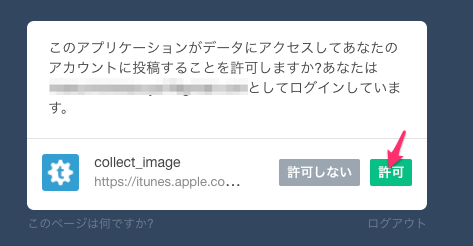
そうするとこんな感じの画面が表示されるのでおもむろにExplore APIをクリックします

許可をクリック
するとこんな画面になるので
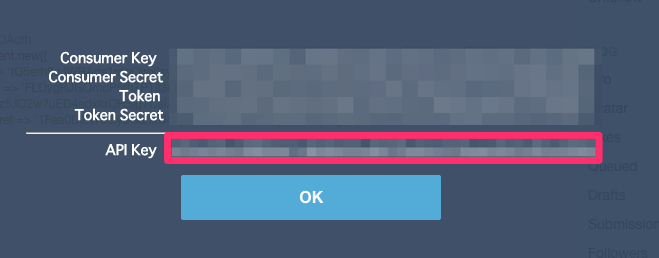
右上のShowKeysをクリックします
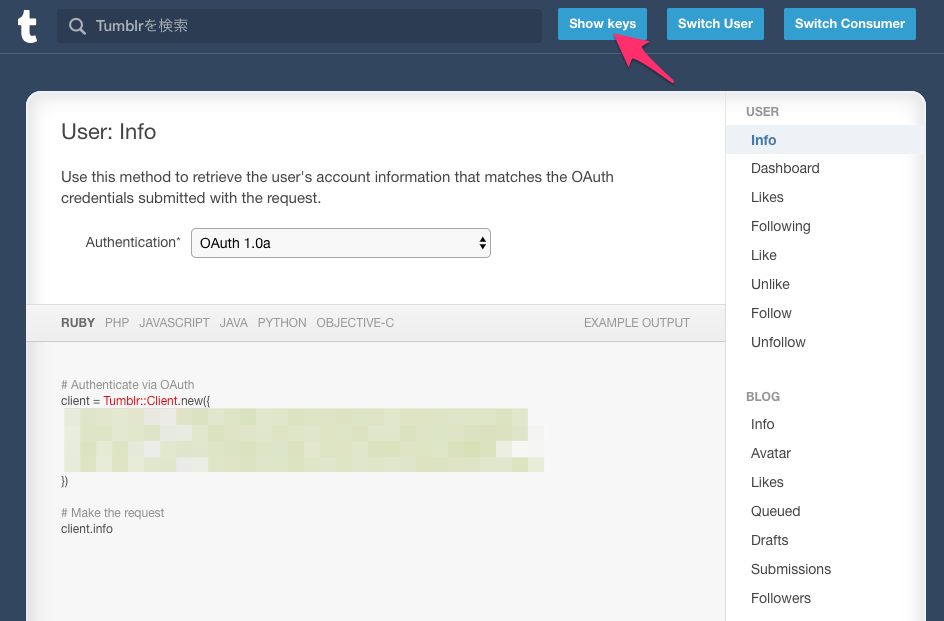
ここにAPIKeyが表示されます。今回欲しかったものはこれなのでメモっておきます。
実際に画像を取得する
では取得したAPI KEYを使って実際に画像を取得してみます。Tumblrは写真の投稿が多く、ピカチュウなどのキャラクターの取得には向かないようです。
ということで今回は最近人気の吉岡里帆さんの写真を取得します。
imagesというディレクトリに取得した画像が順次保存されます。
(参考: http://taka-say.hateblo.jp/entry/2016/12/19/235554)
import requests
import time
import shutil
LOOP = 10
URL = 'https://api.tumblr.com/v2/tagged'
payload = {
'api_key': 'YOUR API KEY HERE',
'tag': '吉岡里帆'
}
image_idx = 0
photo_urls = []
for i in range(LOOP):
response_json = requests.get(URL, params=payload).json()
for data in response_json['response']:
if data['type'] != 'photo':
continue
for photo in data['photos']:
photo_urls.append(photo['original_size']['url'])
if(len(response_json['response']) == 0):
continue
payload['before'] = response_json['response'][(len(response_json['response']) - 1)]['timestamp']
for photo_url in photo_urls:
path = "images/" + str(image_idx) + ".png"
r = requests.get(photo_url, stream=True)
if r.status_code == 200:
with open(path, 'wb') as f:
r.raw.decode_content = True
shutil.copyfileobj(r.raw, f)
image_idx+=1



はいこんな感じで画像がたくさん取得できました。可愛いですね!