おしっこセンサーできました
ウチの小学生の息子が家のトイレでたびたびおしっこをこぼしてしまう。俺がくどくど注意してもあんまり効果ない。そこで、代わりにAIに怒ってもらうことにした。こんな感じである。
 おしっこセンサーのデモ([動画](https://www.youtube.com/watch?v=ktSukhHdogM))。水を数滴床にたらすとブザーが鳴り、床を拭くと止まる。
おしっこセンサーのデモ([動画](https://www.youtube.com/watch?v=ktSukhHdogM))。水を数滴床にたらすとブザーが鳴り、床を拭くと止まる。
ディープラーニングの画像認識を使い、床の上に落ちた水滴をカメラで検出してブザーが鳴る仕組みだ。夏休みの自由工作に過ぎないので精度は期待していなかったけど、意外にきちんと動いてくれて、カメラに映る範囲に水滴を数滴たらすとピッピと鳴り、床を拭くとブザーも止まる。「お父さんだってAIくらい作れるぞ」と息子に自慢したいがための工作なのだ。
でも、これ作るのはそんなに難しくなくて、休み中の3日くらいで完成した。かかったお金は、RasPiやカメラ、周辺デバイスが2万円弱、画像認識のモデル作成に使ったクラウドの料金が数100円である。こんな一般家庭の超どーでもいい問題の解決にも最新AIを投入できるとは、機械学習の民主化バンザイだ。
以下、このおしっこセンサーができるまでのつまづきポイント等を書いておきたい。ソースコードはすべてここに置いておいた。
RasPi+GrovePiを用意
今回は、Dexter Industriesが提供するGrovePiを使ってLEDとブザー、明るさセンサーをRaspberry Pi 3に接続した。

GrovePiはRasPi用の周辺デバイスキットで、LEDや光センサー、ブザー、LCDディスプレイ等をハンダ付けなしで簡単にRasPiにつなげられる。Pythonドライバも付属しており、ArduinoのようなシンプルなAPIで数行書くだけでLEDをチカチカさせたり周囲の明るさを取得したりできる。ただし、ちょっとお高い。
さらにRasPi用の標準カメラをつなげておく。RasPiにハリガネを貼り付けてカメラを固定できるようにした。
TensorFlowとKerasをRasPiにインストール
ディープラーニングによる画像認識部分は、TensorFlowとKerasの組み合わせで作った。TensorFlow単体でも作れそうだけど、今回のキモである「転移学習」を使って画像認識エンジンを作るには、Kerasがいちばん手軽そうだった。手軽さ重要。一度Keras使ってみたかったし。Kerasが提供する高レベルなAPIを使ってディープラーニングのモデルを定義すると、その下でTensorFlowが動く仕組みである。
また、
- RasPi上でディープラーニングを動かして画像認識を実行する
- RasPiは画像を撮るだけで、ディープラーニングによる画像認識はクラウド上で実行する
のどちらにするかも悩んだが、今回はRasPi上で画像認識することにした。KerasやTensorFlowってRasPiできちんと動くのか? 速度はどの程度か? って体験してみたかった。
ただ、RasPiにTensorFlowとKerasを入れるのは結構手間取った。詳しくはこの記事を見て欲しい。さらに、ディープラーニングによる画像認識は今のRasPiには荷が重い。今回のように何にも最適化をせずにそのまま動かすと、一回の認識に2秒くらいかかる。
もちろんRasPi上でディープラーニングを動かすメリットもいくつかある。クラウド上のAPIやバックエンドを呼び出す必要がないので、このおしっこセンサーはネット環境のない場所でも単体で使える。また、ランニングコストも電気代だけで済む。
Kerasで転移学習
ディープラーニングを使うときよく課題となるのは、たくさんの学習用データをどうやって用意するかという点だ。例えば高精度な画像認識モデルをゼロから作ろうとすると、数万〜数10万枚の学習用画像とそのラベルを用意して、数日間かけてGPUで学習する必要がある。ハードル高すぎて夏休みの自由工作にはならない。
そこで今回は、この問題を解決するためによく使われる転移学習(transfer learning)をいかに手軽に使うかにポイントを絞った。転移学習とは、あらかじめ誰か(例えばGoogleとか)が膨大な学習データと計算リソースを使って学習済みのモデルを再利用し、個々の用途に応じてちょこっと再学習して使う手法だ。
Kerasでの転移学習の使い方は、Kerasの作者Francoisが書いたBuilding powerful image classification models using very little dataや、aidiaryさんのVGG16のFine-tuningによる犬猫認識 (2)がとっても参考になった。
今回のコードは、Francoisのサンプルコードの割とそのまんまである。Kerasを使うと画像認識のための転移学習がとてもラクに書けて、例えばこんな感じで一行書くだけで、ポピュラーな画像認識モデルであるVGG16の学習済みモデルをダウンロードして読み込んでくれる。
base_model = applications.VGG16(weights='imagenet', include_top=False, input_shape=(150, 150,3))
VGG16の構成はこんな感じ。

From: VGG in TensorFlow
このVGG16の学習済みモデルは、一般画像データベースであるImageNetの画像を使って学習されている。そのため、それらの画像を左から入れると、一番右の全結合層に「ネコ」とか「クルマ」といったラベルが出てくる。
しかし、今回認識したいのは以下の写真のような床に落ちた水滴である(あんまりきれいではないトイレ画像をさらしてごめんなさい)。

この画像をVGG16に入れても、「床に落ちた水滴」っていう認識結果が出てくるわけではない。でもVGG16の内部では、ネコやクルマを識別する手前の段階で、多種多様な画像のさまざまな形や色、パターン、模様などを認識できるニューラルネットワークが形成されている。そして、一番最後の全結合層が1000種類のラベル(ネコとかクルマとか)を取り出すために使われている。
そこで、最後の全結合層を外してしまう(上記のモデル作成時に指定したinclude_top=Falseがその指定)。そして、水滴の形やテカリなどの「床に落ちた水滴に特有なパターン」かどうかを判定する小さなニューラルネットワークを用意する。
top_model = Sequential()
top_model.add(Flatten(input_shape=base_model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))
これは2段(それぞれ256ノードと1ノード)からなる全結合型の小さなネットワークだ。これとVGG16を以下のコードで接続する。
model = Model(inputs=base_model.input, outputs=top_model(base_model.output))
これで最終段の差し替えが完了だ。モデル全体の構成はこんな感じ。ほとんどVGG16そのままだが、一番最後の層だけ入れ替えてある。
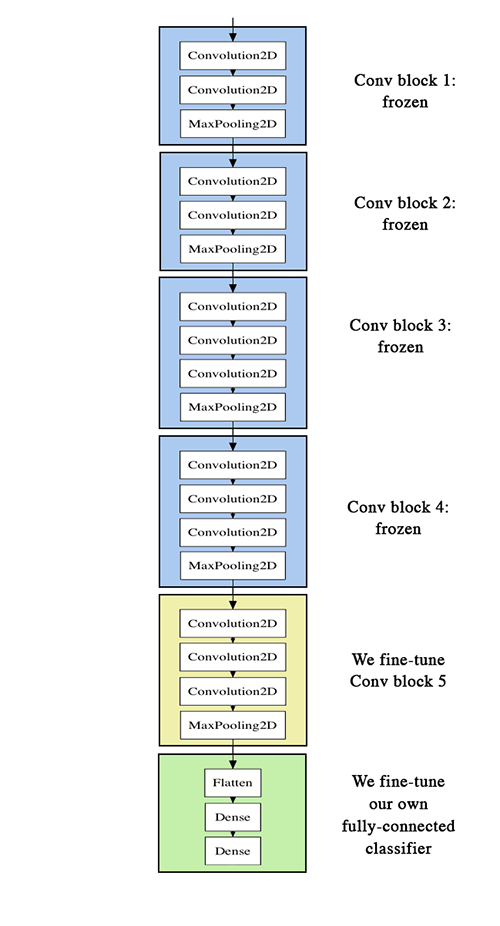
From: Building powerful image classification models using very little data
そして、このモデルのうち、前半の14段を学習しないように設定する。
for layer in model.layers[:15]:
layer.trainable = False
これで、上図の黄色の部分(VGG16の最後の畳み込み層)と緑色の部分(今回追加した全結合層)だけを再学習する設定となる。こうした転移学習の方法はfine-tuningと呼ばれている。
こんな感じで、Kerasでは転移学習用のモデル設計も簡単だ。
学習用画像を作成する
さて、転移学習を使えば学習データはぐっと少なくて済むはず...と思ったが、実際に「水滴のある床」と「水滴のない床」のそれぞれ100〜200枚くらいを作って試してみても、全然精度が上がらない。もっと画像が必要だ。そこでトイレにこもって手に水を漬けて水滴をぽたぽた垂らしながら、RasPiでは0.2秒おきに画像キャプチャするコードを動かし、こういう画像をひたすら集めていくのである。

結果的には水滴あるなし合計で1500枚くらいの学習用画像を用意しないと十分な精度は出なかった。
また画像の種類も工夫が必要。試行錯誤の途中では、水滴がなくても人影に反応してブザーが鳴ってしまうこともあった。水滴ではなく人影を認識するモデルになってしまっていた。

そこで、「水滴のない床」の画像にはいろいろなパターンを追加した。人影や手の影がかぶったもの、トイレのフタの位置が違うもの、トイレがまっくらなもの等々。バリエーションをどんどん増やしていくと、誤認識もぐんと減った。
(追記)
1500枚の学習画像を集めるのたいへんそう! というコメントを結構いただいたけど、実際に集めるのにかかった時間は2時間くらい。RasPiカメラで0.2秒おきくらいにパシャパシャ自動撮影しながら、上から水滴をぽたぽた落としていくだけ。撮影止めて、床拭いて、また撮影開始してぽたぽた…を5回くらい繰り返したかな。そんなに大変じゃなかったです。
画像の「水増し」で汎化性能を上げる
さらに画像認識の精度を上げる常套手段が「水増し」(data augmentation)である。苦労して集めた元画像を使い、画像の回転や反転、移動、拡大・縮小、正規化や白色化等々、いろいろな加工画像を自動生成して学習に用いる方法だ。Kerasにはこの水増しのためのImageDataGeneratorが用意されていて、以下のように元画像のディレクトリと水増し数(batch_size)を指定すると、水増し画像をいくらでも生成できるジェネレータを用意してくれる。
train_generator = train_datagen.flow_from_directory(
'myimagedir',
target_size=(150, 150),
batch_size=32,
class_mode='binary')
これがあるとないとでは、モデルの汎化性能、つまり「現場で実際に得られる性能」が全然違ってくる。
水増しせずに学習したモデルはすんなり高精度が出るけど、それは学習に使った画像に対してのみ高い精度が出てるだけで、実際にトイレに持っていくと全然まともに動かない。言われたことしかできない新人君のようなモデルなのだ。いわゆる「過学習」である。一方、水増し画像を加えてじっくり時間をかけて鍛えると、見たことのない画像に現場で遭遇しても臨機応変に認識できる「使える」モデルになった。
クラウドのGPUで学習
こうして用意したたくさんの画像を使ったモデルの学習は、さすがにRasPiを使ったのでは永遠の時間がかかってしまうので、クラウドサーバ(Google Compute Engine)を使って行う。
今回はNVIDIA K80を1個載せたGCEのGPUインスタンスを用意した。ちなみにGCEのGPUインスタンスはまだ公開ベータ版のため、作成するにはGPUの割り当て申請が必要で、かつ無料トライアルアカウントでは作成できないので注意が必要。GCPの東京リージョンにはまだGPUが来てないけど、台湾にあるasia-east1-aゾーンならGPUインスタンスを作れる。
 Google Compute EngineのGPUインスタンスを作る
Google Compute EngineのGPUインスタンスを作る
このインスタンス作成画面の右側にはコスト見積もりが表示されており、4個のvCPUと15GBのメモリ、1個のK80を搭載したインスタンスで1時間あたり1ドル弱である。GPUインスタンスが用意できたら、TensorFlowのインストールページを参考にして、NVIDIAのCUDA ToolkitやcuDNNをインストールしておく。
GPUは、CPUと比べてざっくりひとケタ以上の高速な学習ができる。今回の学習の規模はこんな感じ。
- 1200枚の学習用画像(150x150に縮小)
- 水増し枚数は32枚(合計4万枚弱)
- 500エポック時点での検証精度はおよそ95%
この規模の学習は数10分で終わる。時間をかけて我がモデルがじわじわと精度を上げていくのを見守るのは嬉しいものである。オーブン料理を作ってるみたいだ。

何回か試行錯誤したけど、クラウド代金の合計は1000円行ったか行かないか、くらいのはず。
マルチGPUも試そうかな? と思ったけど、KerasでマルチGPUを使うにはいろいろ面倒な書き直しが発生するので、今回はやめておいた。マルチGPUを使うなら、TensorFlowのEstimator APIで書いてML Engineで自動分散させた方がラクじゃないかなと思う(VMにCUDAやcuDNN入れたり等々も不要だし)。
十分な精度の出るモデルができあがったら、RasPi上でモデルを読み込んで「床に水滴が落ちている確率」を予測するコードをこんなふうに書く。この確率が一定値を上回った時にブザーを鳴らすコードをGrovePiのAPIでこんなふうに書いておいた。また明るさセンサーも使って、トイレに誰か居るときにだけ認識するようにした。
今回のまとめ
実際のところ、このおしっこセンサーで息子の悪癖が治るとはあんまり期待していない(むしろ面白がって試しまくる恐れが...)。でも、RasPiに苦労してTensorFlowを入れたり、トイレにこもって水滴画像集めたり、いろいろ学習の方法を工夫してじわじわ精度が上がっていくのを眺めたりのプロセスが楽しい。お仕事で使う機械学習は精度の要件とかいろいろ厳しいだろうけど、趣味の自由工作で使う機械学習は精度あまり気にしないしクッキングのような楽しさがあるので、ぜひお試しあれ。
Disclaimer この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。