ドワンゴがニコ動の画像配信向けにFPGAエンジニアを募集したり、マイクロソフトはBingをFPGA実装したり、Baiduもディープラーニングの高速化にFPGAを導入したりと、なんだか世の中急にハードウェアくさくなってきた。IoTとは違う意味で。
金融分野ではすでにCPUでは遅すぎてFPGAによるナノ秒単位の株取引が行われているって記事を書いたのは2年前だけど、ここ数年はIntelのCPUのクロックもあまり上がらなくなってきたし、Fusion-ioやNetezzaといった大手御用達のハイエンド鬼速ストレージも、フタを開ければ中身はすでにFPGAに移行済み。IBMが最近出したData Engine for NoSQLという製品ではPOWER8プロセッサにFPGAを直付けしてRedisを高速化したり。いよいよデータセンターにも、先の見えないCPUに代わってFPGAやGPUを導入する波が押し寄せつつある。
フィックスターズ村瀬氏によると、「ハードウェアを熟知したソフトウェアエンジニアが活躍する時代の波が、今やってきている」らしい。このビッグウェーブに乗るしかない! というわけで、マイクロソフトのBingのFPGA実装のペーパーとビデオを見ていたところ、いかにしてBingの検索エンジン機能がFPGAによるハードウェア実装に置き換えられたかが詳細に解説されていて、JP MorganのFPGA導入話いらいの大きな感銘を受けた。さっそく以下に要約したい。
引用元と参考文献
今回の元ネタはこちら:
- A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services by Microsoft
-
検索エンジン自作入門 by 山田浩之さん、末永匡さん
- 検索エンジンの中身といえばこの本。山田さんから献本いただき、BingのFPGA実装についてもご意見いただきました。山田さんあざす!
ところで、このあたりの話題に興味がある人は、FPGAエクストリーム・コンピューティングの第6回を1月〜2月に開催予定なので、遊びに来てみるといいです。mesoさんのご協力により、会場はドワンゴさんの予定!
なぜFPGAか?
マイクロソフトは、ムーアの法則はもう終わってると考えてるようだ。
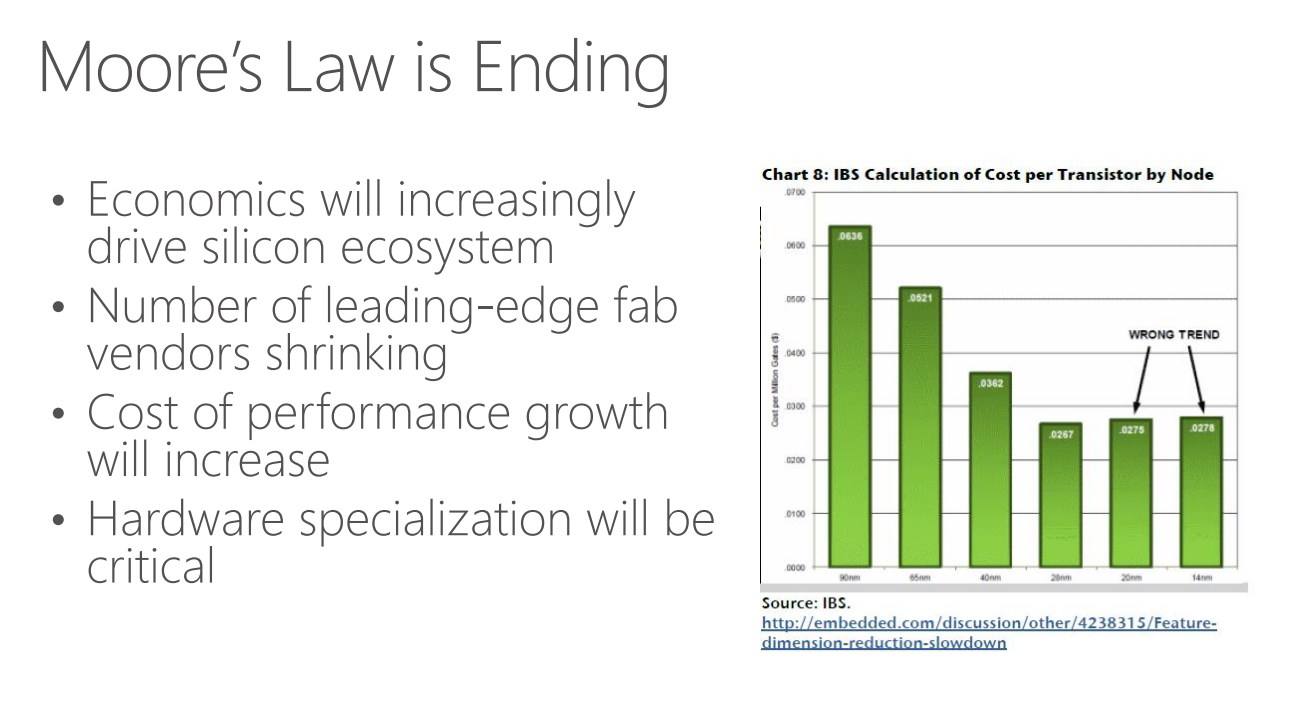
これは「ゲート数あたりのコスト」を示したグラフだが、20nmや14nmプロセスではもはや横ばい。シリコンの集積度が指数的に向上していく時代は終わったので、今後は「hardware specialization(特定用途に特化したハードウェアの実装)」が重要という。
では、汎用品であるCPUに代わって、どのようなハードウェアを使えばいいのか。おもな選択肢としては、ASIC、GPU、FPGAがある(以下は俺の理解):
- ASIC: 用途ごとに回路を設計してLSIを特注するもの。工場に発注して大量生産するので数千万〜数億円はかかるし、開発期間も数ヶ月〜数年を要する。しかしもっとも高性能。
- GPU: GPUをグラフィクス以外の用途に使う方法。大量の浮動小数点演算やSIMD演算のスループットを出すのがめっぽう得意で、CUDAやOpenCLで使えるのでソフトウェアエンジニアでも比較的容易に開発できる。しかしASICやFPGAのような自在な回路設計はできないので、用途によって得意不得意がある。
- FPGA: 回路構成をSRAM上に持たせて動的書き換え可能にしたLSI。クロックは数100MHz程度が上限で、ASICやGPUに比べて組める回路規模はぐんと小さい。開発もGPUほど簡単ではない。しかし用途に応じて回路構成を自由に書き換えられるので、うまくハマると絶大な効果が得られる。ASICに比べて開発期間は短くアプリの仕様変更にも強い。1万円あれば評価ボードを買って遊べるお手軽さ。
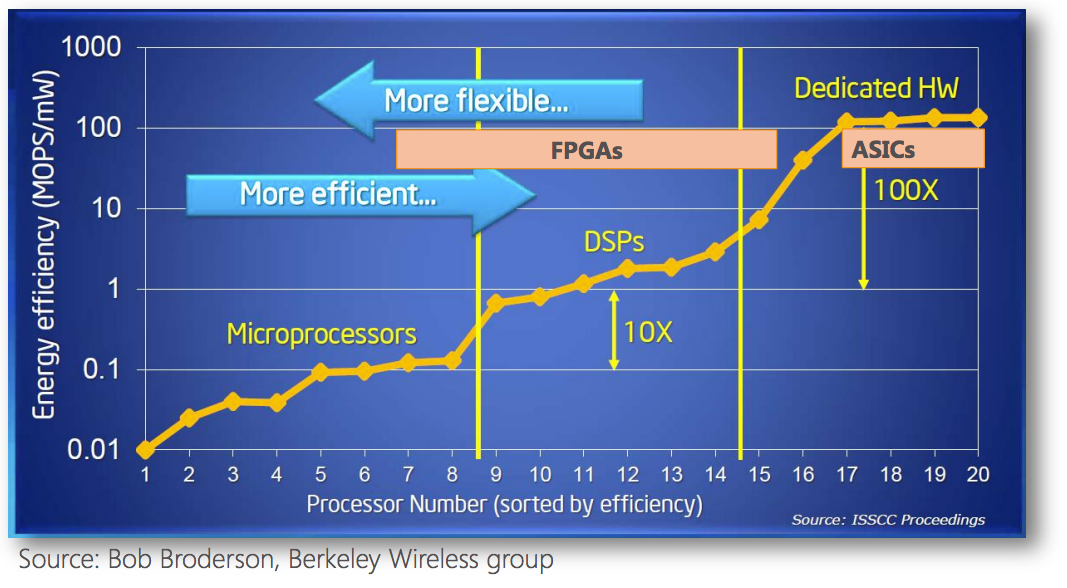
マイクロソフトいわく、ASICでは開発に要するコストや時間が大きく、5年単位での開発と運用となってしまう。しかし5年後のBingにどのような機能の実装が必要でどの程度の負荷が発生するか、予測は不可能。加えて、Bing以外にも200種類のクラウドサービスがある。回路設計を日々更新できるFPGAであれば、ASICほどの性能は得られないものの、アプリケーションのさまざまな要件や変化に対応できる柔軟性と、専用ハードウェアの高効率性を両立させることができる。という結論だ。
ちなみに、このペーパーではGPUという選択肢についてはあまり論じられていない。検索エンジンのアクセラレーションにGPUを使うとどうなるのか? は興味のあるところだ。
FPGAを導入、サーバー台数は半分に
プロジェクトは2010年に始まり、現時点では1,632台のFPGA搭載サーバーがバージニア州のデータセンターに試験導入されている。

試験導入であるため、FPGAによるBing検索結果はまだユーザーには提供されていない。しかし、Bingの実際のクエリ トラフィックがFPGA搭載サーバーにもミラーリングされて送られており、プロダクション運用の準備は整っているという。2015年初めにはユーザー向けサービスに本番投入される見込みで、その後複数のデータセンターにも展開される予定。
そして肝心の効果であるが、

- これまでと同じレイテンシを維持するために必要なサーバー台数が1/2に減少
- FPGA搭載にともなう消費電力増加は10%以下
という。マイクロソフト規模のデータセンター事業者にとって、性能を落とさずにサーバー台数を半分に減らせるというのはただ事ではない破壊的なコスト削減につながる。FPGAはじまってた。
どんなサーバー?
今回のFPGA導入にあたって、マイクロソフトは初めてサーバーを自社開発し、Microsoft Open Compute Serverとして仕様公開している。こんな仕様のサーバーだ:
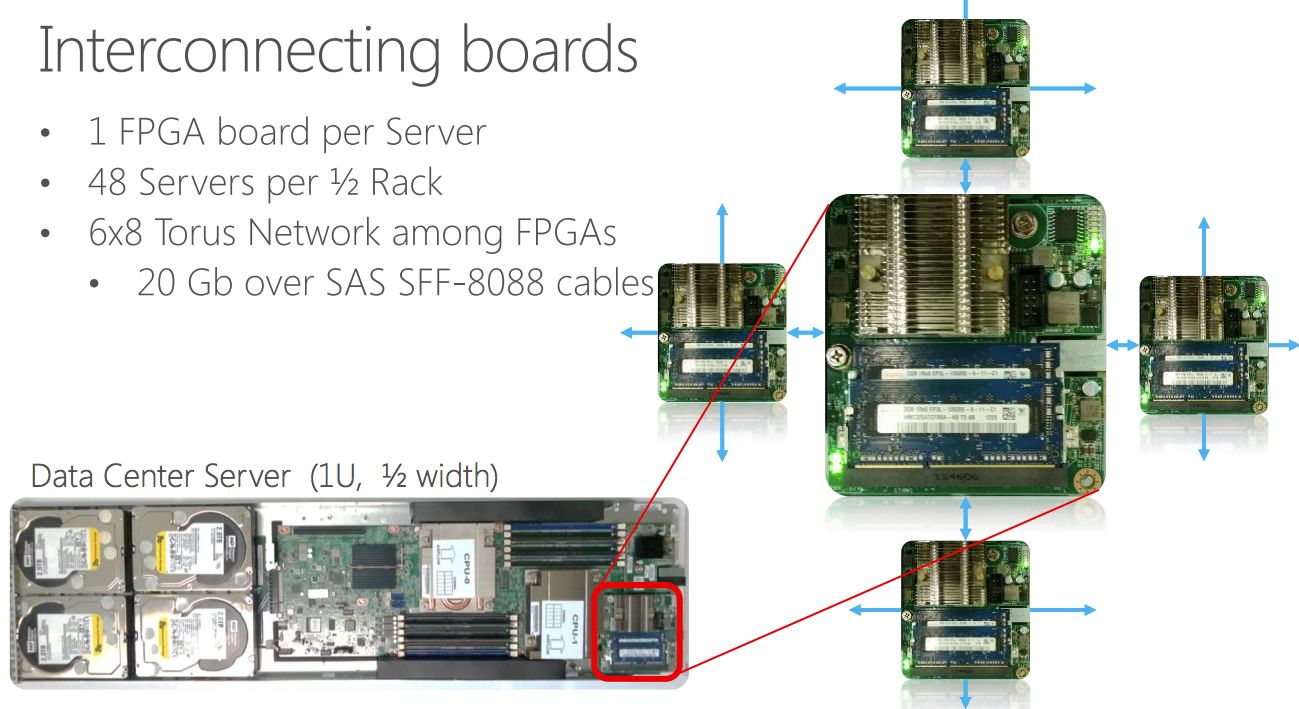
- 1/2幅1Uサーバー、1ラックあたり48台収容
- 8コアXeon 2.1GHz CPU x 2、64GB DRAM、HDD x 4、SSD x 2、10GbE
- FPGA: Altera Stratix V D5, 200MHzクロック, PCIe x 8, 8GB DRAM
この写真にあるように、サーバーの端っこにFPGAカードが載っている。このカードには2GB/sのSerialLite IIIリンクが4本付いており、他サーバーのFPGAカードと接続してトーラスを構成する。
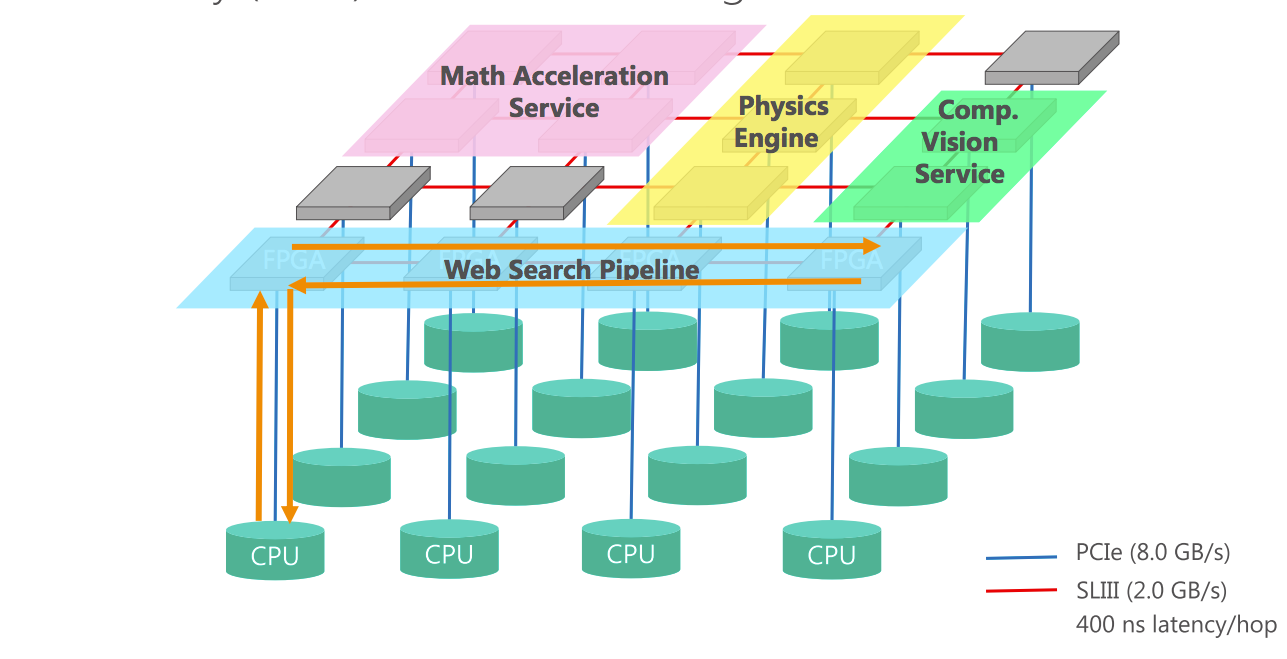
このFPGA専用のトーラスネットワークによって、複数のサーバーをまたがるFPGAのパイプラインを自由に構成できる。つまりCPU側のネットワークとFPGA側のネットワークの二枚重ねになっており、FPGAリソースを柔軟に振り分けられる上、FPGAのパイプライン処理においてCPUがボトルネックにならないように工夫されている。
ちなみに上図では、Bing用のWeb検索パイプラインに加えて、数値演算サービス、物理演算エンジン、画像処理サービスなど各種サービスがFPGAネットワーク上に構成されている様子がわかる。狙いはBingだけじゃなかった。マイクロソフト本気だ。
Bing FPGAの中身
では、Bingを実装したFPGAの中身はどのような設計になっているか、掘り下げていきたい。個々のFPGAは「Shell」と「Role」というコンポーネントに大きく分割されている。
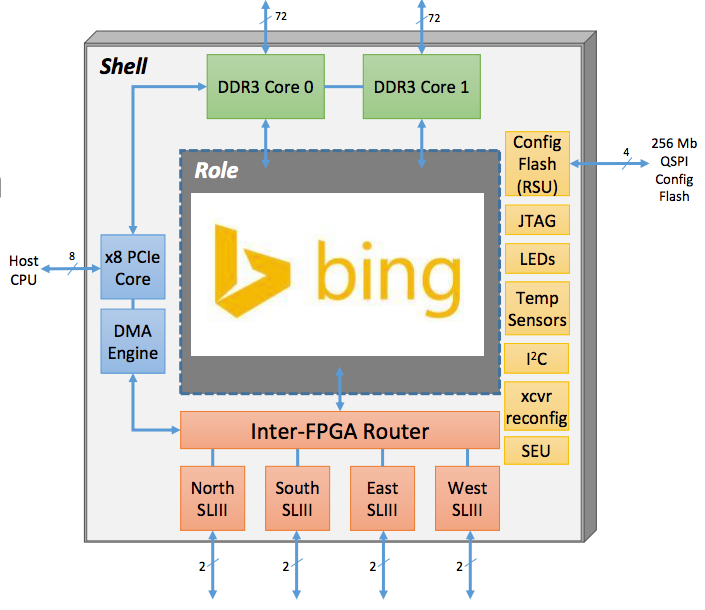
Shellとは、アプリケーションの違いにかかわらず共通して用いられるI/O機能を実装したコンポーネントである。CPUと通信するPCIeコントローラ、DDR3メモリコントローラ、FPGA間トーラスネットワーク、そしてFPGAの回路書き換えのためのインタフェースなどを備える。
一方のRoleは、アプリケーションに応じて差し替えられるコンポーネントで、全体のおよそ80%を占める。例えばBing用のFPGAだったら、ここにBing処理用の回路が入る。そしてなんとこのRole部分は、Shell部分の動作を止めずに回路の動的再構成が可能。サーバーを稼働させたままでアプリケーションのローリング アップグレードを行えるのだ……ハードウェア実装のくせに!
Bing IndexServeの構成
Bing検索サービスを提供する「Bing IndexServe」は以下のようなツリー構成になっている。
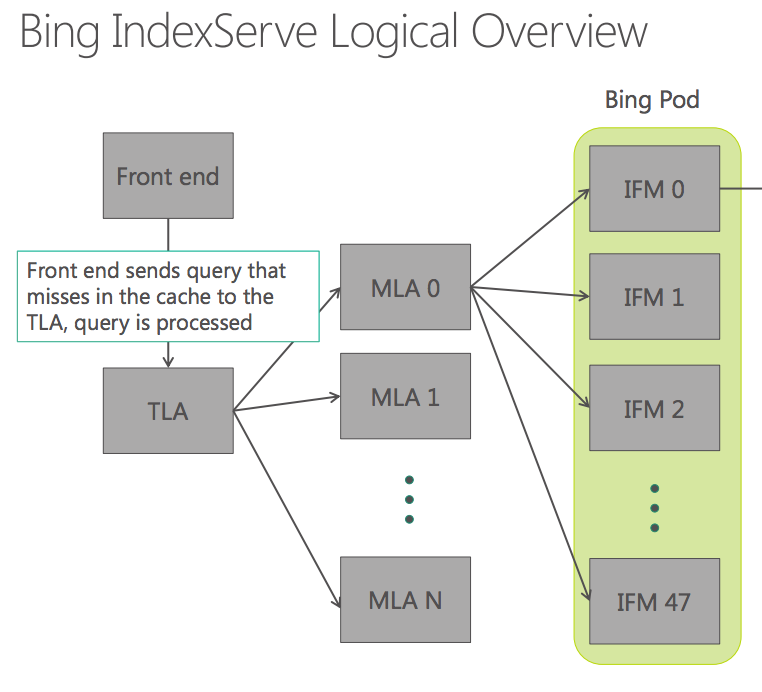
ユーザーからの検索クエリはフロントエンドによって受けられ、キャッシュミスしたもののみ以下の流れで検索処理が実行される。
- TLA (Top Level Aggregator):フロントエンドからのクエリを20〜40台程度のMLAに転送し、検索結果をMLAから集約してフロントエンドに返す
- MLA (Mid Level Aggregator):ラック単位で設置。ラック内の48台のIFMにクエリを転送する。
- IFM (Index File Manager):例えば2万ページ程度のドキュメントの集まりに対して、クエリに基づくランクの計算を行う。ランク上位の4ドキュメントのIDをMLAへ返す。MLAは上位100ドキュメントをTLAに返し、TLAは上位10ドキュメントをソートしてフロントエンドに返す
つまり、ユーザーからのクエリはおおよそ1000台を超えるIFMに分散され、そこで検索とランクの計算が並列実行される。
IFMによるドキュメント検索とランク計算
では、肝心のIFM内部におけるFPGAアクセラレーションの実際を見てみよう。IFMでは以下の3つの処理が行われる。
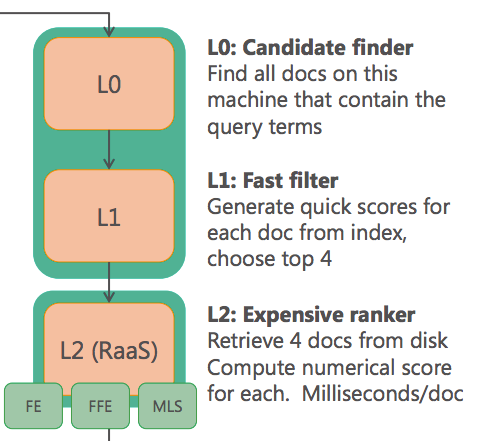
- L0 Candidate finder: 検索インデックスに基づき、クエリ内の単語をふくむすべてのドキュメントを選出
- L1 Fast filter: 検索インデックスに基づき、上位4ドキュメントを絞り込む
- L2 Expensive ranker: 上位4ドキュメントのランクを計算する
これらのうち、計算負荷の高い最後のランク計算、L2の部分がFPGA化されている。このランク計算部分はもともと3万行のC++で記述されており、それを4人年をかけてVerilog HDL(ハードウェア記述言語)に置き換えたという。
ちなみに、ここまでのアーキテクチャ全体は既存のBingサービスと共通となっており、L1までのソフトウェア側ではFPGAの存在を意識する必要はない。IFM内部でのランク計算APIが呼び出された段階で個々のサーバーでFPGAアクセラレータが稼働しているかチェックされ、存在すればAPI内部でFPGAが呼び出され、存在しなければ既存のソフトウェア ライブラリで実行される。
CPUからFPGAへのPCIeバスを介した呼び出しにはシステム コールは用いず、ユーザープロセス上の特定のアドレス空間に読み書きすることで行う。16KBのデータでは16usで転送可能。FPGAで計算されたランク処理結果はDMAでメモリに返される。
特徴量の抽出と合成、機械学習
L1からL2へは、4つのドキュメントIDとクエリ内容が流れてくる。このIDに基づいてSSDからドキュメント内容が読み込まれ、Hit Vector(ドキュメントにおけるクエリ内の単語の位置)のストリームが生成される。このHit Vectorストリームに対して、FPGAで実装された以下の処理が実行される。
- Feature Extraction (FE): 特徴量抽出
- Free-Form Expression (FFE): 特徴量の合成
- Machine Learning Scoring (MLS): 機械学習によるスコア計算
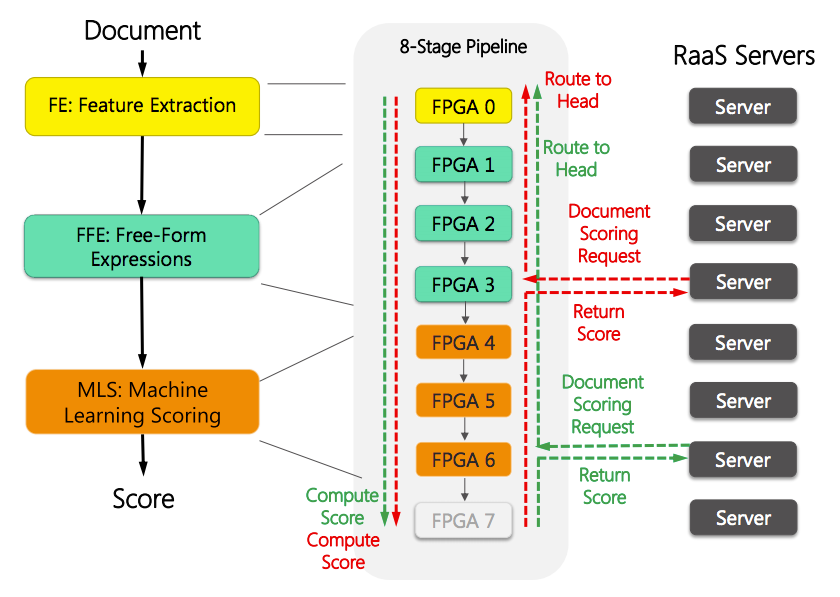
CPUからFPGA上のL2へのリクエストは、上図にあるように、FPGAのトーラスネットワークを通じて、FEを担当するFPGA 0へと転送される。そこから8個のFPGAを繋いだパイプラインを通して、FE、FFE、MLSの各演算を実施していく。
FE: ステートマシンによる特徴量抽出
FEでは、ドキュメントのHit Vectorのストリームを読み込んで、そこからさまざまな特徴量を抽出する。ドキュメントの特徴量とは、例えば「FPGA Configuration」というクエリが与えられたとき、単語「FPGA」の出現回数、「Configuration」の回数、そして「FPGA Configuration」という並びの回数はそれぞれいくつか、といったクエリに対するドキュメントの特徴を表す値である。
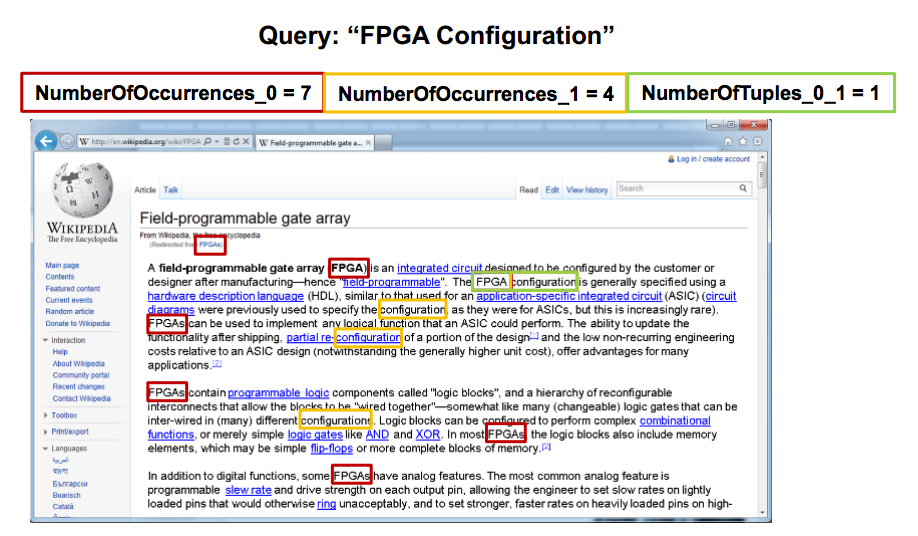
FEにはハードウェアで実装されたステートマシンが54個並んでおり、これらに同じHit Vectorを流すことで196種類の異なる特徴量を並列に取り出し、2.6K個の特徴量を抽出することができる。
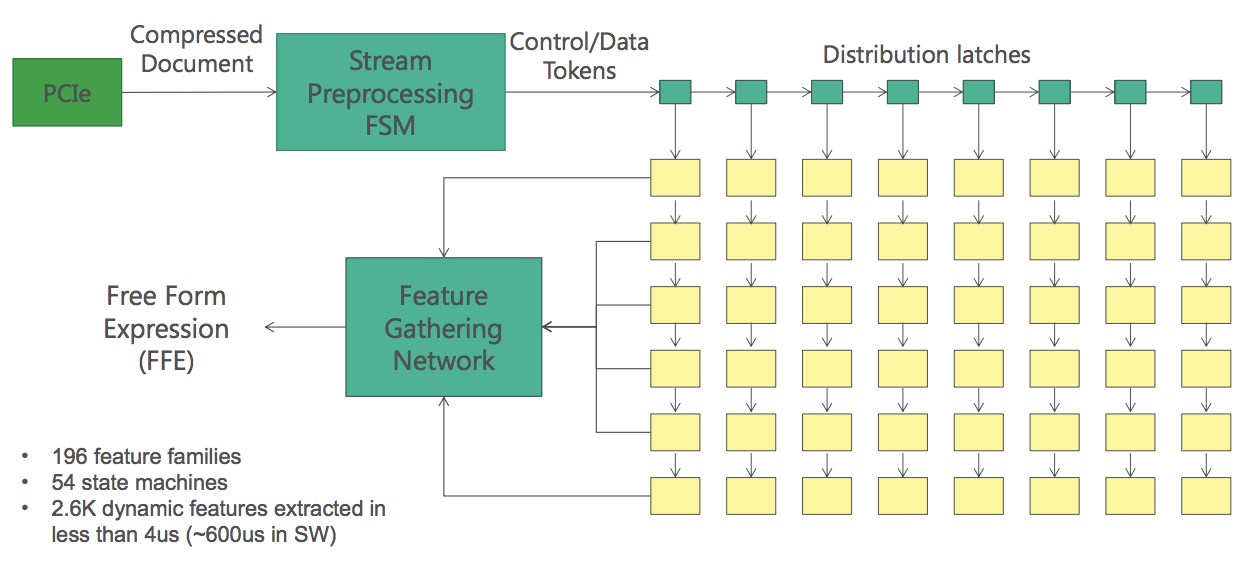
ペーパーではこのアーキテクチャをMISD (Multiple Instruction, Single Data)と分類している。つまり、ひとつのドキュメントに対して複数の異なるロジックを並列適用する専用計算機を設計したようなものだ。この並列化によって、ソフト実装では600usかかっていた処理をハード実装では4us、つまり150倍(!)の速さで実行できる。
FFE: メニーコアによる特徴量合成
FEで特徴量が抽出されたのち、FFEでは複数種類の特徴量どうしを掛けたり割ったりして合成特徴量を計算する。これにより、ステートマシンだけでは取得しづらい複雑な特徴量を得る。
この合成特徴量の数は数千におよび、単純な四則演算に加えて複雑な浮動小数点演算も含まれる。このニーズに最適なアーキテクチャとして、FFEではメニーコア プロセッサを採用している。
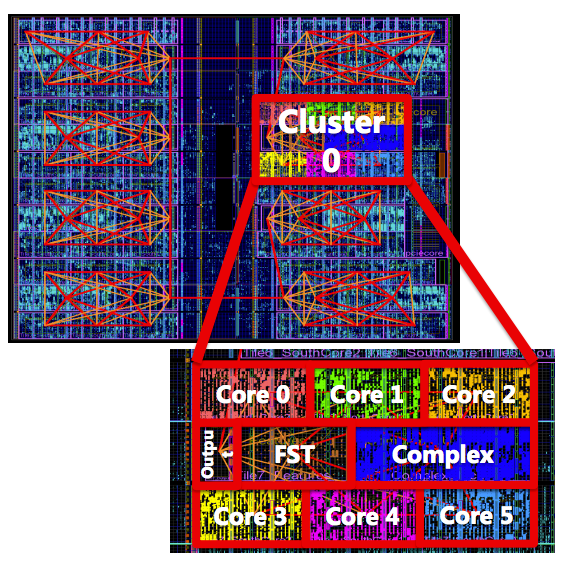
1個のFPGA上に最大で48コアを構成可能で、個々のコアは簡単なCPUの機能を備えている。このメニーコア プロセッサ用のマイクロコードを記述することで、例えば551個の合成特徴量の演算を5usで実現する。これはx86上のソフト実装の10倍の速度だ。
こんなふうに、FPGAであれば特定のアプリケーション ロジックの実行に特化したレジスタや演算器、命令セットを備えるオレオレマイクロプロセッサをゼロから設計でき、必要ならその設計を動的に再構成できる。これはGPUにもASICにもできない芸当だ。FEやFFEのような粒度が細かく並列実行のし易いロジックにうまくはまると、上で見たように数100倍や数10倍といったケタ違いの性能向上もめずらしくない。ハードとソフト両方を使いこなして、シリコンの並列性を最大限引き出せるコンピュータを自分でスクラッチから設計できるというところが、エンジニアにとってFPGAのいちばん魅力的なところである。
MLS: 専用回路による機械学習アルゴリズム
さて、FFEから生成される2K個ほどの合成特徴量は、最終段であるMLSに投入され、機械学習アルゴリズムによるランクの計算が行われる。

しかし、ペーパーでもビデオでも、このMLS部分の詳細は明かされていない(まあそうだろう)。Doug Burgerによれば、「例えばニューラルネットのような」アルゴリズムが専用の回路で実装されており、ステートマシンやメニーコアのようなある程度汎用な仕組みにはなっていないとのこと。結果、出てくるのは、ドキュメントごとのランクを表す浮動小数点値だ。
もっとも、機械学習のアルゴリズムは入れ替わりが激しく、実験的なアルゴリズムも一部に含まれているため、月に一度は更新される。そのたびに毎回Verilog HDLを修正するような手間はかけていない。アルゴリズムのモデルを記述する言語が用意され、そこからモデル コンパイラを通じてマイクロコードが生成されるとのこと。
耐障害性とFPGA再構成
マイクロソフト規模のデータセンターで大量のFPGAを本番導入するに際して、FPGAの耐障害性への考慮も必要となった。
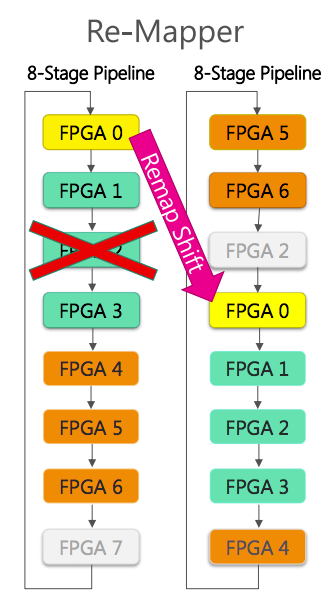
今回の実装では、FPGAのトーラスネットワーク上に8個のFPGAを連ねたリングを構成し、うち1個を予備とする冗長構成をとっている。タイムアウト等でFPGAの障害を検知すると、FPGAのリセットによるリカバリを試みる。もしリカバリできない場合は、そのFPGAを外してリングを作り直す。
さらに、FPGAの回路構成を読み込ませるためのビットストリーム イメージの配布も、データセンター規模でスムーズに行えるような環境が整えられている。
最初は相手にされなかったFPGA
以上がBing検索サービスにおけるFPGA実装部分のメカニズムだが、これを実際にプロダクション環境へ投入するまでには、さまざまな苦労があったそうだ。
2011年に最初の実装が完成したとき、現場からの評判は芳しくないものだったという。最初にFPGAを6個搭載するPCIeカードを実装したところ、
- そんなPCIeスロットが空いてるサーバーなんてないし、特殊なサーバーは置きたくない
- FPGAが6個だと足りなかったり余ったりするのだけど?
- そのFPGAをプログラミングできるエンジニアってウチに何人いるの? いないの?
という反応だったそう。そこで、PCIeスロットではなくドーターカード形式で、マイクロソフト内のデータセンター共通のサーバー筐体内にコンパクトに収められる設計に変更。また、FPGA用のトーラスネットワークを設けることで、異なるサーバー間でFPGA同士のパイプラインを構成し、リソースの柔軟な配分を可能にした。結果的に、ハードウェア エンジニアの採用コストに見合う多大なコスト削減効果を示すことができたという。Doug Burgerがんばった。
MSさんカッコいいです
以上、Microsoft BingにおけるFPGA導入について、同社のペーパーとビデオに基いてまとめてみた。ここで書いてあるように、設計を見るとマイクロソフトの本気度が伝わってくる内容になっており、今後はBing以外のさまざまなアプリケーションやサービスがFPGA化されそうだな、という印象だ。ここまで大胆なパラダイム シフトをデータセンター規模で推し進めているマイクロソフト、背水の陣というか、なかなかカッコいいのである。
1/22追記
MSのDerekさんが東大で講演されてたので、聞きに行った。そのまとめはこちら。
Disclaimer この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。