ディスクロージャー:以下で紹介する forEach の実装者です。(2015/07/09追記)
OpenCV で画素処理、具体的には cv::Mat を使って各画素ごとに処理をする際のメモです。
cv::Mat::forEach(関数)
OpenCV 3.0 で、画像やボクセルデータを扱う基本型である cv::Mat および cv::Mat_<type> に、与えられた関数をそれぞれの要素上で実行する forEach メソッドが追加されました。公式ドキュメント(英語)
forEach メソッドの利点は、次の通りです。
- 関数内で、cv::Mat の各要素の値を変更することができる
- 単なる関数を渡すだけのお手軽処理で、シングルコアマシンでも大抵のイテレーション処理と同等か、それより早く動作する。
- マルチコアマシンであれば、自動的に並列化され、かつ低オーバーヘッドである。
使用例
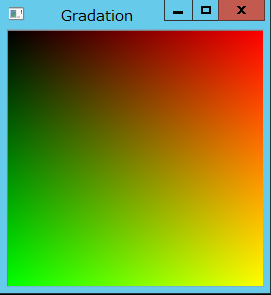
次の結果で、グラデーション画像が生成されます。
# include <opencv2/opencv.hpp>
typedef cv::Point3_<uint8_t> Pixel;
int main(const int an, const char* const* const as)
{
cv::Mat_<Pixel> square(256, 256);
square.forEach([](Pixel &p, const int position[2]) -> void {
// Pixel の BGR(xyz) のうち、GR を、画素の位置に応じた値で塗る。
p.x = 0; // blue
p.y = position[0]; // green
p.z = position[1]; //red
});
cv::imshow("Gradation", square);
cv::waitKey();
}
速度比較
以下に、比較用コードと、関数の処理が軽い時のベンチマーク結果を張っておきます。
# include <iostream>
# include <opencv2/core.hpp>
typedef cv::Point3_<uint8_t> Pixel;
typedef cv::Mat_<Pixel> MatT;
const cv::Size SIZE_FULL_HD(1920, 1020);
void ShowResult(const std::string name, const double time) {
std::cout << cv::format("%40s | %20.10f", name.c_str(), time) << std::endl;
return;
}
void bench(const std::string func_name, void func(MatT&), const int time) {
MatT img(SIZE_FULL_HD);
img *= 0;
const uint64_t start = cv::getCPUTickCount();
for (int count = 0; count < time; ++count) {
func(img);
}
const uint64_t end = cv::getCPUTickCount();
const double time_elapsed = (end - start) / cv::getTickFrequency() / time;
ShowResult(func_name, time_elapsed);
}
inline void iterator_access(MatT& frame) {
auto it = frame.begin();
for (auto &p : frame) {
p.x = 255;
}
}
inline void pointer_access(MatT& frame) {
auto p = reinterpret_cast<Pixel*>(frame.data);
const auto e = p + frame.cols * frame.rows;
while (p < e)
{
p->x = 255;
++p;
}
}
inline void forEach_access(MatT& frame) {
auto mat = cv::Mat_<Pixel>(frame);
mat.forEach([&](Pixel &p, const void*) -> void {
p.x = 255;
});
}
# define BENCH(func_name) \
bench(#func_name, func_name, times);
int main(const int an, const char* const* const as)
{
# ifdef _DEBUG
const int times = 1;
# else
const int times = 1000;
# endif
BENCH(iterator_access);
BENCH(pointer_access);
BENCH(forEach_access);
}
結果
iterator_access | 0.0050911927
pointer_access | 0.0014229820
forEach_access | 0.0003748687
4物理コアマシンで、pinter_access と forEach_access の速度比を求めると、3.7959 倍の高速化が得られました。関数が軽量でも、おおよそスケールしています。(=並列処理のオーバーヘッドは割と小さいです)
関数内の処理が重くなると、そこで律速するので、イテレーターとポインタアクセスは漸近していき、それらと forEach の速度の比は、コア数に近づいていきます。(3.7959 → 4.0 に近づきます)
実施マシン情報
(Windowws 上、dxdiag 実行結果の一部です)
------------------
System Information
------------------
Time of this report: 6/21/2015, 19:28:54
Machine name: NEO
Operating System: Windows Server 2012 R2 Datacenter 64-bit (6.3, Build 9600) (9600.winblue_r9.150322-1500)
Language: Japanese (Regional Setting: Japanese)
System Manufacturer: Gigabyte Technology Co., Ltd.
System Model: EX58-UD3R
BIOS: Award Modular BIOS v6.00PG
Processor: Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz (8 CPUs), ~2.7GHz
Memory: 20480MB RAM
Available OS Memory: 20478MB RAM
Page File: 7164MB used, 23041MB available
Windows Dir: C:\Windows
DirectX Version: DirectX 11
DX Setup Parameters: Not found
User DPI Setting: Using System DPI
System DPI Setting: 96 DPI (100 percent)
DWM DPI Scaling: Disabled
DxDiag Version: 6.03.9600.17415 64bit Unicode
注意点
forEach に渡す関数の中身は、自動的に並列実行されます。
そのため、関数内から、その外部の特定変数に書き込む場合には、同時にほかのスレッドが同じ値を変更しないことを確認する必要があります。
合計値を求める処理(アキュムレーション)の場合には、cv::Accumulator やその周辺の専用関数を使ったほうがいいかと。
以下は違反コードの例です。
int main(const int an, const char* const* const as)
{
cv::Mat_<Pixel> square(256, 256);
long x_total = 0;
square.forEach([&](Pixel &p, const int position[2]) -> void {
x_total += p.x;
// FIXME: 違反コード.複数スレッドから x_total への同時書き込み.
});
}