JAL6-MD5 において、私の書いたコードが非常に遅いとご指摘いただいていたのですが、主な原因はClojureのformat関数にあります。
format関数は、
(defn format
"Formats a string using java.lang.String.format, see java.util.Formatter for format
string syntax"
{:added "1.0"
:static true}
^String [fmt & args]
(String/format fmt (to-array args)))
という定義で、中身はJavaのString.formatそのまま呼んでいるだけです。
そして、JavaのString.formatメソッドのソース(Oracle JDK 7u10 source)をみると、
public static String format(String format, Object... args) {
return new Formatter().format(format, args).toString();
}
このように、これもまた java.util.Formatterを呼んでいるだけです。ということは、このFormatterにボトルネックがありそうです。String.formatを繰り返し呼ぶプログラムを動かし、プロファイルを取得してみます。
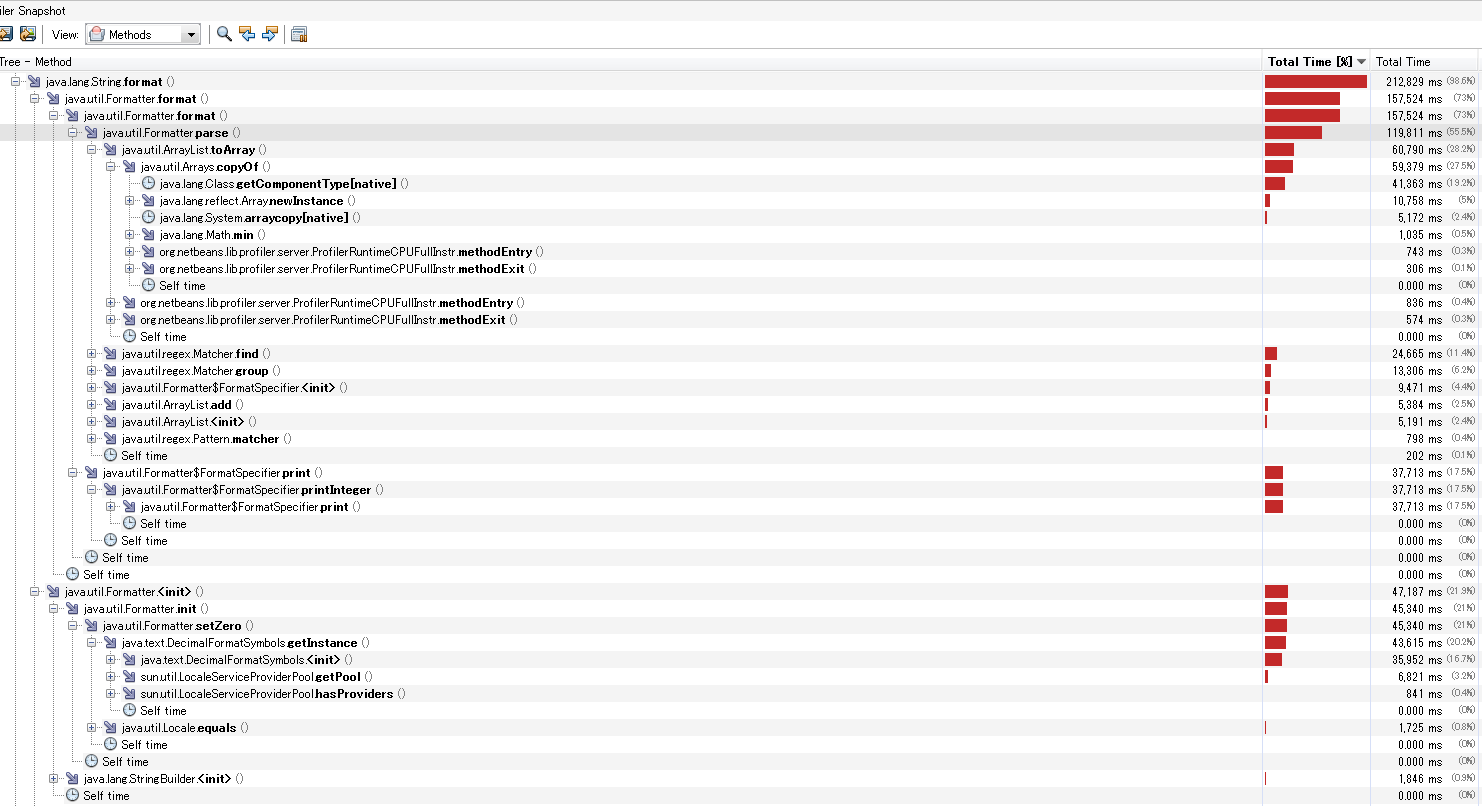
さて、この結果をみると、やはり大方の予想どおりFormatter.parseメソッドが半分以上CPU時間を占めています。
↑のような様々な書式に対応するために、format引数を解析している訳ですが、そこで正規表現を使っているようです。find,groupがそこそこのCPU時間を使っています。
が、しかしそれ以上に喰っているのが、ArrayListのtoArrayメソッドです。これはArrays.copyOfをただ呼び出しているだけなのですが、ここで、コピー先の型がObject配列でない場合は、getComponentTypeが呼ばれます。が、これが比較的コストが高いようです。
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
試しに、toArrayの型指定なしと、型指定ありで簡単なベンチマークを取ってみます。
public static void main(String[] args) throws Exception {
long t1, t2;
ArrayList list = new ArrayList<Integer>(1000);
for (int i=0; i<1000; i++)
list.add(i);
t1 = System.currentTimeMillis();
for (int i=0; i < 100000; i++) {
list.toArray();
}
t2 = System.currentTimeMillis();
System.out.println("toArray():" + (t2-t1));
t1 = System.currentTimeMillis();
for (int i=0; i < 100000; i++) {
list.toArray(new Integer[0]);
}
t2 = System.currentTimeMillis();
System.out.println("toArray(Integer[]):" + (t2-t1));
}
実行してみると、
toArray():454
toArray(Integer[]):1033
となり、型引数を渡した方が、getComponentTypeの分だけ遅くなっていることが分かります。
それからFormatter.formatは、parseした書式にしたがい、Formatter$FormatSpecifier.printで文字列を出力しているのですが、ここは単純にStringBuilderでappendしていくだけで、ボトルネックっぽいものは見当たりませんでした。
さて、String.formatを繰り返し呼んだ場合でも、前述のとおり毎回Formatterがnewされます。プロファイル結果をみると、ここのコストも馬鹿にならなさそうです。中身をみるとほとんどが、DecimalFormatSymbols.getInstanceに費やされていることが分かります。
Formatterをnewするとロケールに応じたCurrencyなどのインスタンスも作られるので、これも結構コストの高い処理になっています。したがって、繰り返し呼ぶ場合は、少なくともFormatterは使いまわした方がよさそうです。
ということで、まとめると、
- 性能が要求される箇所では、format関数/String.formatを使わない方が良い。
- 書式に応じた出力が必要な場合でも、String.formatを使わずに、可能であれば自分でFormatterをnewして使いまわした方が良い。
ということです。Clojurianのみなさま、お騒がせして申し訳ありませんでした。